 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNull-Space Diffusion Distillation for Efficient Photorealistic Lensless Imaging
Nov 15, 2025State-of-the-art photorealistic reconstructions for lensless cameras often rely on paired lensless-lensed supervision, which can bias models due to lens-lensless domain mismatch. To avoid this, ground-truth-free diffusion priors are attractive; however, generic formulations tuned for conventional inverse problems often break under the noisy, highly multiplexed, and ill-posed lensless deconvolution setting. We observe that methods which separate range-space enforcement from null-space diffusion-prior updates yield stable, realistic reconstructions. Building on this, we introduce Null-Space Diffusion Distillation (NSDD): a single-pass student that distills the null-space component of an iterative DDNM+ solver, conditioned on the lensless measurement and on a range-space anchor. NSDD preserves measurement consistency and achieves photorealistic results without paired supervision at a fraction of the runtime and memory. On Lensless-FFHQ and PhlatCam, NSDD is the second fastest, behind Wiener, and achieves near-teacher perceptual quality (second-best LPIPS, below DDNM+), outperforming DPS and classical convex baselines. These results suggest a practical path toward fast, ground-truth-free, photorealistic lensless imaging.
Extended Depth-of-Field Lensless Imaging using an Optimized Radial Mask
Mar 21, 2023



The freedom of design of coded masks used by mask-based lensless cameras is an advantage these systems have when compared to lens-based ones. We leverage this freedom of design to propose a shape-preserving optimization scheme for a radial-type amplitude coded mask, used for extending the depth of field (DOF) of a lensless camera. Our goal is to identify the best parameters for the coded mask, while retaining its radial characteristics and therefore extended-DOF capabilities. We show that our optimized radial mask achieved better overall frequency response when compared to a naive implementation of a radial mask. We also quantitatively and qualitatively demonstrated the extended DOF imaging achieved by our optimized radial mask in simulations by comparing it to different non-radial coded masks. Finally, we built a prototype camera to validate the extended DOF capabilities of our coded mask in real scenarios.
Descriptor-Free Multi-View Region Matching for Instance-Wise 3D Reconstruction
Nov 27, 2020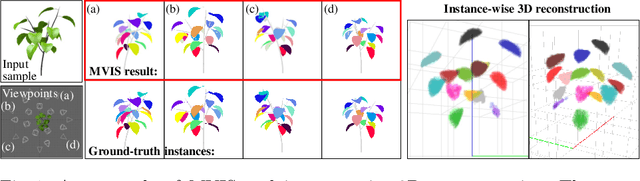


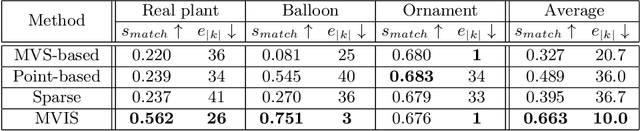
This paper proposes a multi-view extension of instance segmentation without relying on texture or shape descriptor matching. Multi-view instance segmentation becomes challenging for scenes with repetitive textures and shapes, e.g., plant leaves, due to the difficulty of multi-view matching using texture or shape descriptors. To this end, we propose a multi-view region matching method based on epipolar geometry, which does not rely on any feature descriptors. We further show that the epipolar region matching can be easily integrated into instance segmentation and effective for instance-wise 3D reconstruction. Experiments demonstrate the improved accuracy of multi-view instance matching and the 3D reconstruction compared to the baseline methods.
Noisy-LSTM: Improving Temporal Awareness for Video Semantic Segmentation
Oct 19, 2020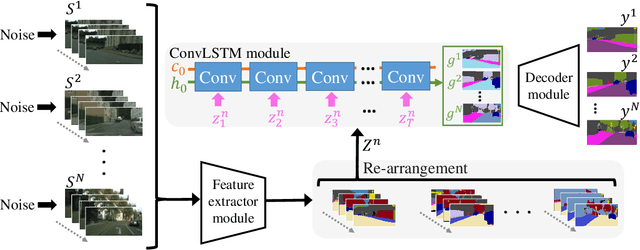

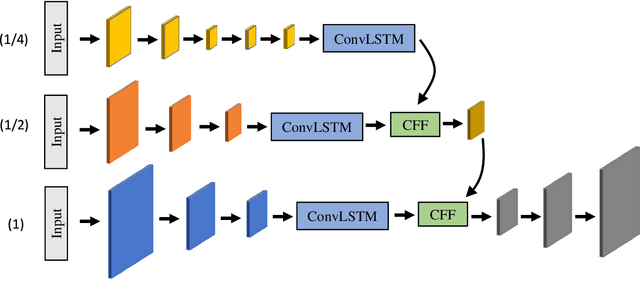

Semantic video segmentation is a key challenge for various applications. This paper presents a new model named Noisy-LSTM, which is trainable in an end-to-end manner, with convolutional LSTMs (ConvLSTMs) to leverage the temporal coherency in video frames. We also present a simple yet effective training strategy, which replaces a frame in video sequence with noises. This strategy spoils the temporal coherency in video frames during training and thus makes the temporal links in ConvLSTMs unreliable, which may consequently improve feature extraction from video frames, as well as serve as a regularizer to avoid overfitting, without requiring extra data annotation or computational costs. Experimental results demonstrate that the proposed model can achieve state-of-the-art performances in both the CityScapes and EndoVis2018 datasets.
Probabilistic Plant Modeling via Multi-View Image-to-Image Translation
Apr 25, 2018

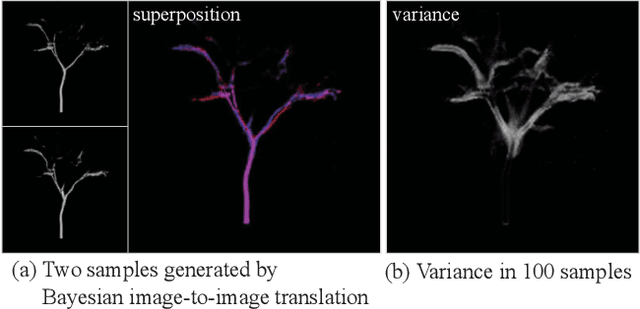
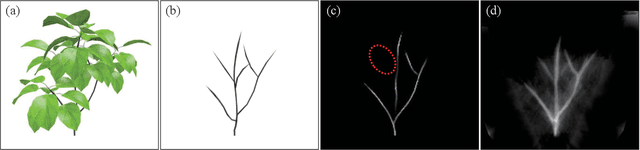
This paper describes a method for inferring three-dimensional (3D) plant branch structures that are hidden under leaves from multi-view observations. Unlike previous geometric approaches that heavily rely on the visibility of the branches or use parametric branching models, our method makes statistical inferences of branch structures in a probabilistic framework. By inferring the probability of branch existence using a Bayesian extension of image-to-image translation applied to each of multi-view images, our method generates a probabilistic plant 3D model, which represents the 3D branching pattern that cannot be directly observed. Experiments demonstrate the usefulness of the proposed approach in generating convincing branch structures in comparison to prior approaches.