 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoded-E2LF: Coded Aperture Light Field Imaging from Events
Feb 26, 2026We propose Coded-E2LF (coded event to light field), a computational imaging method for acquiring a 4-D light field using a coded aperture and a stationary event-only camera. In a previous work, an imaging system similar to ours was adopted, but both events and intensity images were captured and used for light field reconstruction. In contrast, our method is purely event-based, which relaxes restrictions for hardware implementation. We also introduce several advancements from the previous work that enable us to theoretically support and practically improve light field reconstruction from events alone. In particular, we clarify the key role of a black pattern in aperture coding patterns. We finally implemented our method on real imaging hardware to demonstrate its effectiveness in capturing real 3-D scenes. To the best of our knowledge, we are the first to demonstrate that a 4-D light field with pixel-level accuracy can be reconstructed from events alone. Our software and supplementary video are available from our project website.
PANICL: Mitigating Over-Reliance on Single Prompt in Visual In-Context Learning
Sep 26, 2025Visual In-Context Learning (VICL) uses input-output image pairs, referred to as in-context pairs (or examples), as prompts alongside query images to guide models in performing diverse vision tasks. However, VICL often suffers from over-reliance on a single in-context pair, which can lead to biased and unstable predictions. We introduce PAtch-based $k$-Nearest neighbor visual In-Context Learning (PANICL), a general training-free framework that mitigates this issue by leveraging multiple in-context pairs. PANICL smooths assignment scores across pairs, reducing bias without requiring additional training. Extensive experiments on a variety of tasks, including foreground segmentation, single object detection, colorization, multi-object segmentation, and keypoint detection, demonstrate consistent improvements over strong baselines. Moreover, PANICL exhibits strong robustness to domain shifts, including dataset-level shift (e.g., from COCO to Pascal) and label-space shift (e.g., FSS-1000), and generalizes well to other VICL models such as SegGPT, Painter, and LVM, highlighting its versatility and broad applicability.
Enhancing Ambiguous Dynamic Facial Expression Recognition with Soft Label-based Data Augmentation
Jun 25, 2025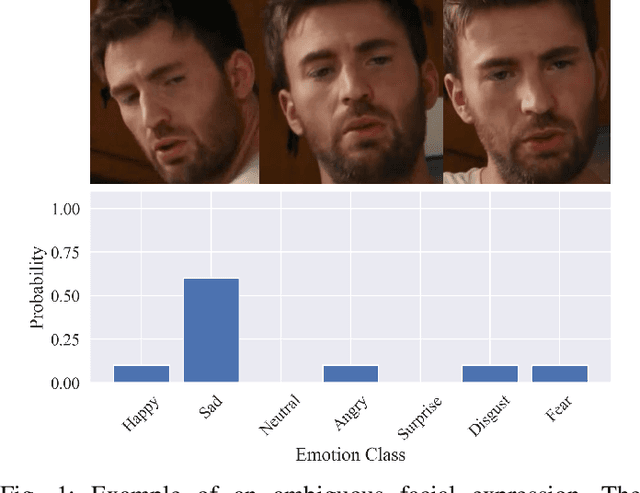
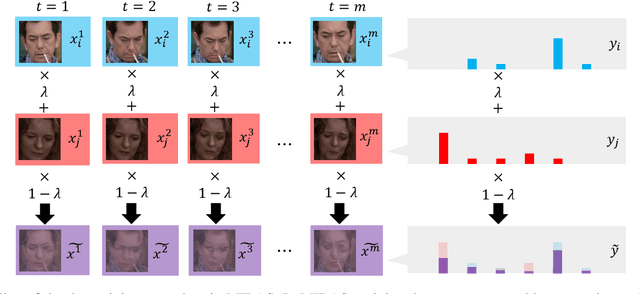
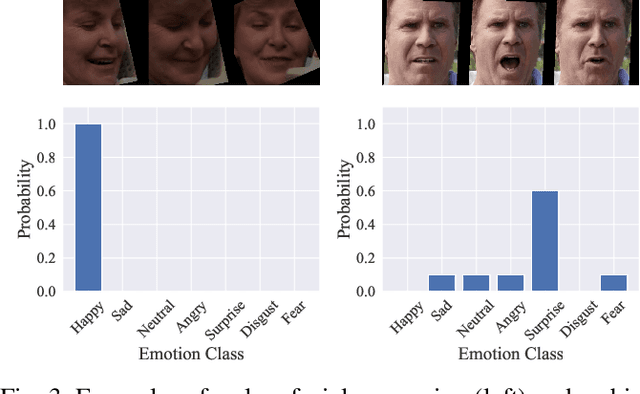
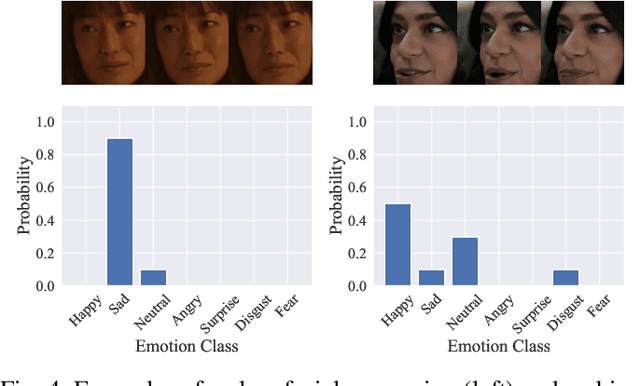
Dynamic facial expression recognition (DFER) is a task that estimates emotions from facial expression video sequences. For practical applications, accurately recognizing ambiguous facial expressions -- frequently encountered in in-the-wild data -- is essential. In this study, we propose MIDAS, a data augmentation method designed to enhance DFER performance for ambiguous facial expression data using soft labels representing probabilities of multiple emotion classes. MIDAS augments training data by convexly combining pairs of video frames and their corresponding emotion class labels. This approach extends mixup to soft-labeled video data, offering a simple yet highly effective method for handling ambiguity in DFER. To evaluate MIDAS, we conducted experiments on both the DFEW dataset and FERV39k-Plus, a newly constructed dataset that assigns soft labels to an existing DFER dataset. The results demonstrate that models trained with MIDAS-augmented data achieve superior performance compared to the state-of-the-art method trained on the original dataset.
E-InMeMo: Enhanced Prompting for Visual In-Context Learning
Apr 25, 2025Large-scale models trained on extensive datasets have become the standard due to their strong generalizability across diverse tasks. In-context learning (ICL), widely used in natural language processing, leverages these models by providing task-specific prompts without modifying their parameters. This paradigm is increasingly being adapted for computer vision, where models receive an input-output image pair, known as an in-context pair, alongside a query image to illustrate the desired output. However, the success of visual ICL largely hinges on the quality of these prompts. To address this, we propose Enhanced Instruct Me More (E-InMeMo), a novel approach that incorporates learnable perturbations into in-context pairs to optimize prompting. Through extensive experiments on standard vision tasks, E-InMeMo demonstrates superior performance over existing state-of-the-art methods. Notably, it improves mIoU scores by 7.99 for foreground segmentation and by 17.04 for single object detection when compared to the baseline without learnable prompts. These results highlight E-InMeMo as a lightweight yet effective strategy for enhancing visual ICL. Code is publicly available at: https://github.com/Jackieam/E-InMeMo
DiReCT: Diagnostic Reasoning for Clinical Notes via Large Language Models
Aug 06, 2024



Large language models (LLMs) have recently showcased remarkable capabilities, spanning a wide range of tasks and applications, including those in the medical domain. Models like GPT-4 excel in medical question answering but may face challenges in the lack of interpretability when handling complex tasks in real clinical settings. We thus introduce the diagnostic reasoning dataset for clinical notes (DiReCT), aiming at evaluating the reasoning ability and interpretability of LLMs compared to human doctors. It contains 511 clinical notes, each meticulously annotated by physicians, detailing the diagnostic reasoning process from observations in a clinical note to the final diagnosis. Additionally, a diagnostic knowledge graph is provided to offer essential knowledge for reasoning, which may not be covered in the training data of existing LLMs. Evaluations of leading LLMs on DiReCT bring out a significant gap between their reasoning ability and that of human doctors, highlighting the critical need for models that can reason effectively in real-world clinical scenarios.
SpotFormer: Multi-Scale Spatio-Temporal Transformer for Facial Expression Spotting
Jul 30, 2024



Facial expression spotting, identifying periods where facial expressions occur in a video, is a significant yet challenging task in facial expression analysis. The issues of irrelevant facial movements and the challenge of detecting subtle motions in micro-expressions remain unresolved, hindering accurate expression spotting. In this paper, we propose an efficient framework for facial expression spotting. First, we propose a Sliding Window-based Multi-Resolution Optical flow (SW-MRO) feature, which calculates multi-resolution optical flow of the input image sequence within compact sliding windows. The window length is tailored to perceive complete micro-expressions and distinguish between general macro- and micro-expressions. SW-MRO can effectively reveal subtle motions while avoiding severe head movement problems. Second, we propose SpotFormer, a multi-scale spatio-temporal Transformer that simultaneously encodes spatio-temporal relationships of the SW-MRO features for accurate frame-level probability estimation. In SpotFormer, our proposed Facial Local Graph Pooling (FLGP) and convolutional layers are applied for multi-scale spatio-temporal feature extraction. We show the validity of the architecture of SpotFormer by comparing it with several model variants. Third, we introduce supervised contrastive learning into SpotFormer to enhance the discriminability between different types of expressions. Extensive experiments on SAMM-LV and CAS(ME)^2 show that our method outperforms state-of-the-art models, particularly in micro-expression spotting.
Deep Polarization Cues for Single-shot Shape and Subsurface Scattering Estimation
Jul 11, 2024



In this work, we propose a novel learning-based method to jointly estimate the shape and subsurface scattering (SSS) parameters of translucent objects by utilizing polarization cues. Although polarization cues have been used in various applications, such as shape from polarization (SfP), BRDF estimation, and reflection removal, their application in SSS estimation has not yet been explored. Our observations indicate that the SSS affects not only the light intensity but also the polarization signal. Hence, the polarization signal can provide additional cues for SSS estimation. We also introduce the first large-scale synthetic dataset of polarized translucent objects for training our model. Our method outperforms several baselines from the SfP and inverse rendering realms on both synthetic and real data, as demonstrated by qualitative and quantitative results.
Explainable Image Recognition via Enhanced Slot-attention Based Classifier
Jul 08, 2024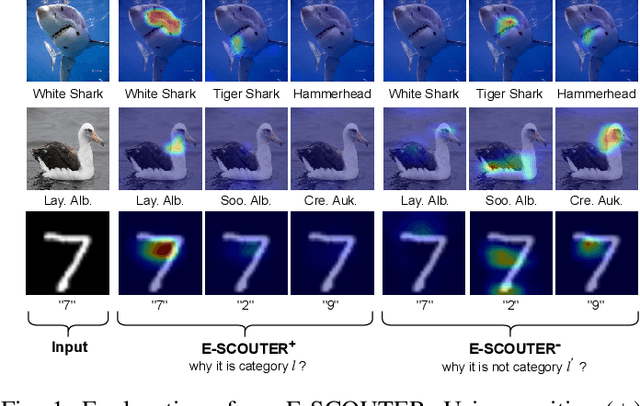
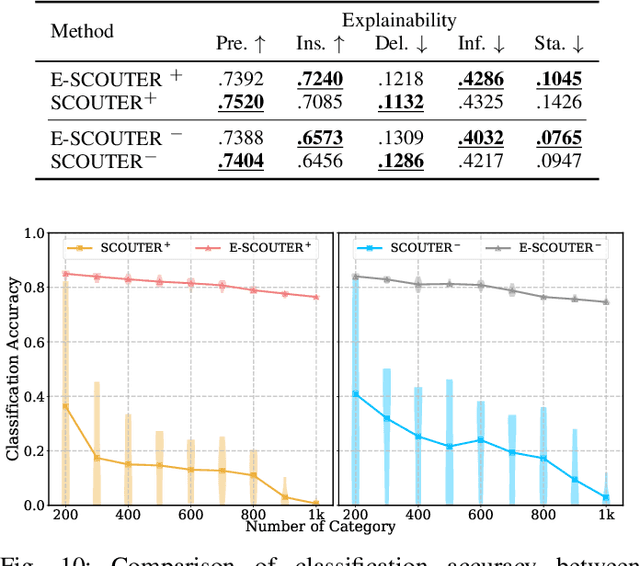
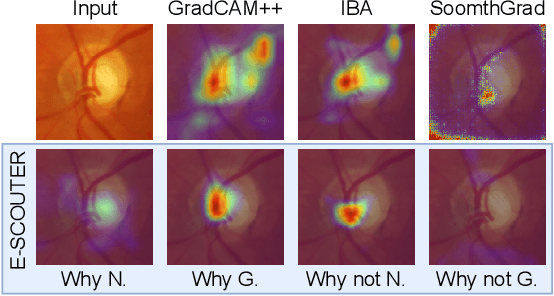
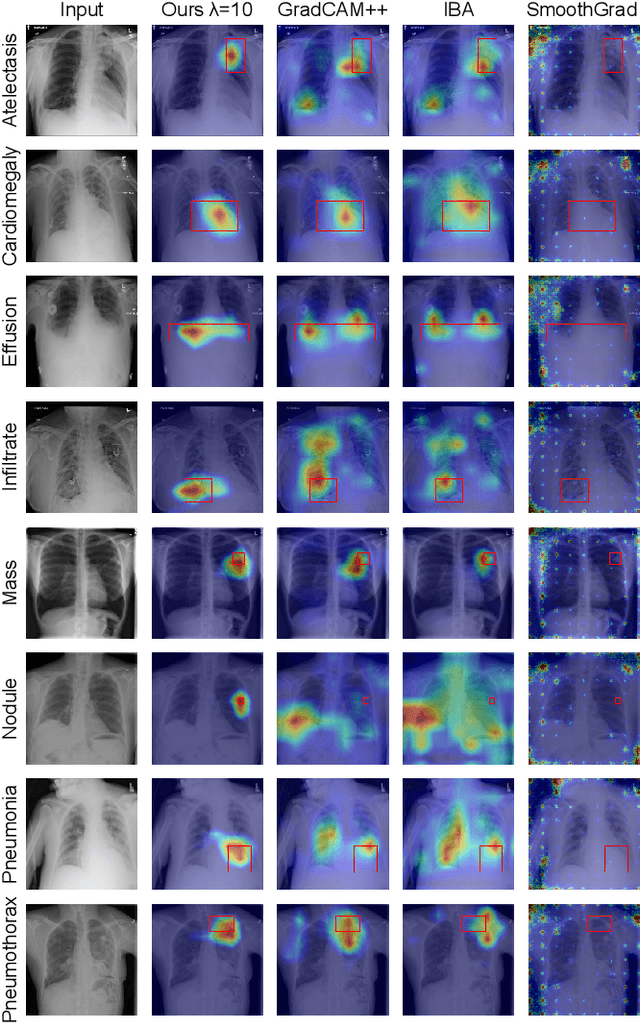
The imperative to comprehend the behaviors of deep learning models is of utmost importance. In this realm, Explainable Artificial Intelligence (XAI) has emerged as a promising avenue, garnering increasing interest in recent years. Despite this, most existing methods primarily depend on gradients or input perturbation, which often fails to embed explanations directly within the model's decision-making process. Addressing this gap, we introduce ESCOUTER, a visually explainable classifier based on the modified slot attention mechanism. ESCOUTER distinguishes itself by not only delivering high classification accuracy but also offering more transparent insights into the reasoning behind its decisions. It differs from prior approaches in two significant aspects: (a) ESCOUTER incorporates explanations into the final confidence scores for each category, providing a more intuitive interpretation, and (b) it offers positive or negative explanations for all categories, elucidating "why an image belongs to a certain category" or "why it does not." A novel loss function specifically for ESCOUTER is designed to fine-tune the model's behavior, enabling it to toggle between positive and negative explanations. Moreover, an area loss is also designed to adjust the size of the explanatory regions for a more precise explanation. Our method, rigorously tested across various datasets and XAI metrics, outperformed previous state-of-the-art methods, solidifying its effectiveness as an explanatory tool.
CALICO: Confident Active Learning with Integrated Calibration
Jul 02, 2024The growing use of deep learning in safety-critical applications, such as medical imaging, has raised concerns about limited labeled data, where this demand is amplified as model complexity increases, posing hurdles for domain experts to annotate data. In response to this, active learning (AL) is used to efficiently train models with limited annotation costs. In the context of deep neural networks (DNNs), AL often uses confidence or probability outputs as a score for selecting the most informative samples. However, modern DNNs exhibit unreliable confidence outputs, making calibration essential. We propose an AL framework that self-calibrates the confidence used for sample selection during the training process, referred to as Confident Active Learning with Integrated CalibratiOn (CALICO). CALICO incorporates the joint training of a classifier and an energy-based model, instead of the standard softmax-based classifier. This approach allows for simultaneous estimation of the input data distribution and the class probabilities during training, improving calibration without needing an additional labeled dataset. Experimental results showcase improved classification performance compared to a softmax-based classifier with fewer labeled samples. Furthermore, the calibration stability of the model is observed to depend on the prior class distribution of the data.
Multi-Scale Spatio-Temporal Graph Convolutional Network for Facial Expression Spotting
Mar 24, 2024
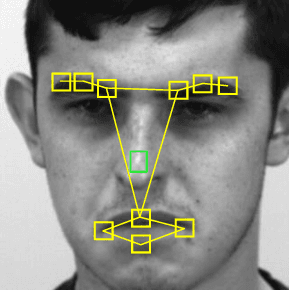
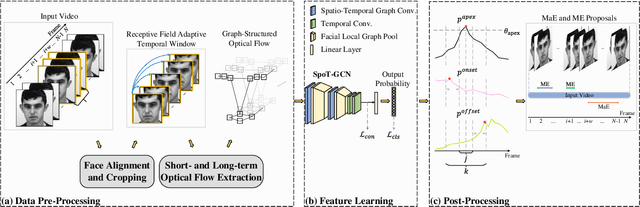

Facial expression spotting is a significant but challenging task in facial expression analysis. The accuracy of expression spotting is affected not only by irrelevant facial movements but also by the difficulty of perceiving subtle motions in micro-expressions. In this paper, we propose a Multi-Scale Spatio-Temporal Graph Convolutional Network (SpoT-GCN) for facial expression spotting. To extract more robust motion features, we track both short- and long-term motion of facial muscles in compact sliding windows whose window length adapts to the temporal receptive field of the network. This strategy, termed the receptive field adaptive sliding window strategy, effectively magnifies the motion features while alleviating the problem of severe head movement. The subtle motion features are then converted to a facial graph representation, whose spatio-temporal graph patterns are learned by a graph convolutional network. This network learns both local and global features from multiple scales of facial graph structures using our proposed facial local graph pooling (FLGP). Furthermore, we introduce supervised contrastive learning to enhance the discriminative capability of our model for difficult-to-classify frames. The experimental results on the SAMM-LV and CAS(ME)^2 datasets demonstrate that our method achieves state-of-the-art performance, particularly in micro-expression spotting. Ablation studies further verify the effectiveness of our proposed modules.