 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Scale Spatio-Temporal Graph Convolutional Network for Facial Expression Spotting
Paper and Code
Mar 24, 2024
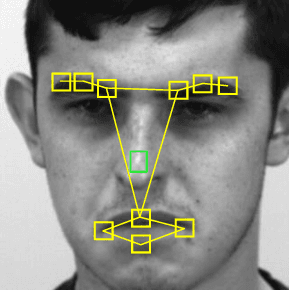
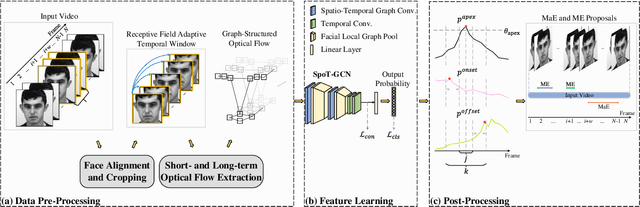

Facial expression spotting is a significant but challenging task in facial expression analysis. The accuracy of expression spotting is affected not only by irrelevant facial movements but also by the difficulty of perceiving subtle motions in micro-expressions. In this paper, we propose a Multi-Scale Spatio-Temporal Graph Convolutional Network (SpoT-GCN) for facial expression spotting. To extract more robust motion features, we track both short- and long-term motion of facial muscles in compact sliding windows whose window length adapts to the temporal receptive field of the network. This strategy, termed the receptive field adaptive sliding window strategy, effectively magnifies the motion features while alleviating the problem of severe head movement. The subtle motion features are then converted to a facial graph representation, whose spatio-temporal graph patterns are learned by a graph convolutional network. This network learns both local and global features from multiple scales of facial graph structures using our proposed facial local graph pooling (FLGP). Furthermore, we introduce supervised contrastive learning to enhance the discriminative capability of our model for difficult-to-classify frames. The experimental results on the SAMM-LV and CAS(ME)^2 datasets demonstrate that our method achieves state-of-the-art performance, particularly in micro-expression spotting. Ablation studies further verify the effectiveness of our proposed modules.