 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpotFormer: Multi-Scale Spatio-Temporal Transformer for Facial Expression Spotting
Jul 30, 2024



Facial expression spotting, identifying periods where facial expressions occur in a video, is a significant yet challenging task in facial expression analysis. The issues of irrelevant facial movements and the challenge of detecting subtle motions in micro-expressions remain unresolved, hindering accurate expression spotting. In this paper, we propose an efficient framework for facial expression spotting. First, we propose a Sliding Window-based Multi-Resolution Optical flow (SW-MRO) feature, which calculates multi-resolution optical flow of the input image sequence within compact sliding windows. The window length is tailored to perceive complete micro-expressions and distinguish between general macro- and micro-expressions. SW-MRO can effectively reveal subtle motions while avoiding severe head movement problems. Second, we propose SpotFormer, a multi-scale spatio-temporal Transformer that simultaneously encodes spatio-temporal relationships of the SW-MRO features for accurate frame-level probability estimation. In SpotFormer, our proposed Facial Local Graph Pooling (FLGP) and convolutional layers are applied for multi-scale spatio-temporal feature extraction. We show the validity of the architecture of SpotFormer by comparing it with several model variants. Third, we introduce supervised contrastive learning into SpotFormer to enhance the discriminability between different types of expressions. Extensive experiments on SAMM-LV and CAS(ME)^2 show that our method outperforms state-of-the-art models, particularly in micro-expression spotting.
Multi-Scale Spatio-Temporal Graph Convolutional Network for Facial Expression Spotting
Mar 24, 2024
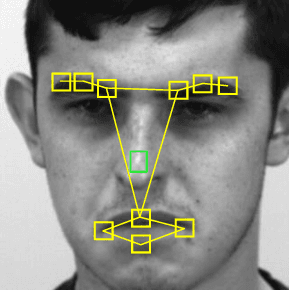
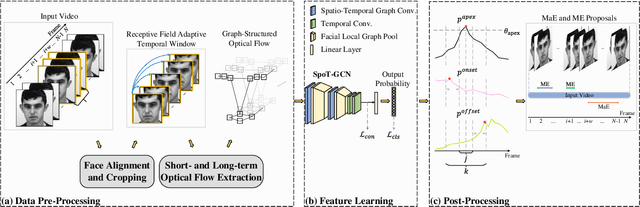

Facial expression spotting is a significant but challenging task in facial expression analysis. The accuracy of expression spotting is affected not only by irrelevant facial movements but also by the difficulty of perceiving subtle motions in micro-expressions. In this paper, we propose a Multi-Scale Spatio-Temporal Graph Convolutional Network (SpoT-GCN) for facial expression spotting. To extract more robust motion features, we track both short- and long-term motion of facial muscles in compact sliding windows whose window length adapts to the temporal receptive field of the network. This strategy, termed the receptive field adaptive sliding window strategy, effectively magnifies the motion features while alleviating the problem of severe head movement. The subtle motion features are then converted to a facial graph representation, whose spatio-temporal graph patterns are learned by a graph convolutional network. This network learns both local and global features from multiple scales of facial graph structures using our proposed facial local graph pooling (FLGP). Furthermore, we introduce supervised contrastive learning to enhance the discriminative capability of our model for difficult-to-classify frames. The experimental results on the SAMM-LV and CAS(ME)^2 datasets demonstrate that our method achieves state-of-the-art performance, particularly in micro-expression spotting. Ablation studies further verify the effectiveness of our proposed modules.
A Synchronized Reprojection-based Model for 3D Human Pose Estimation
Jun 16, 2021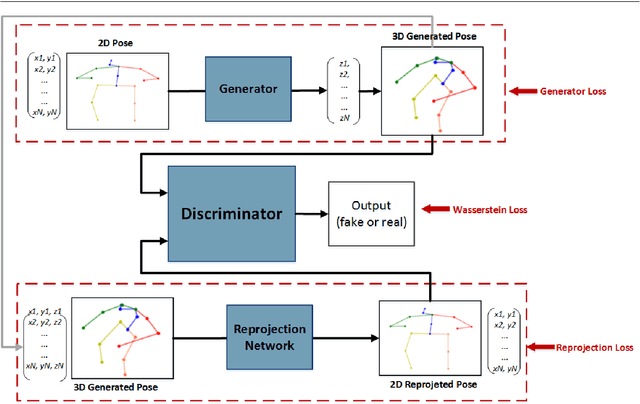
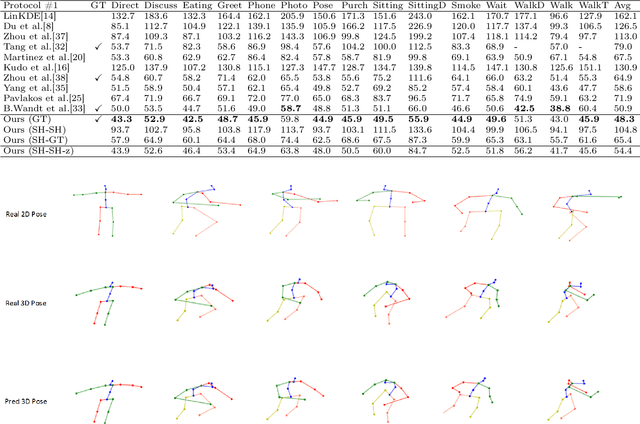
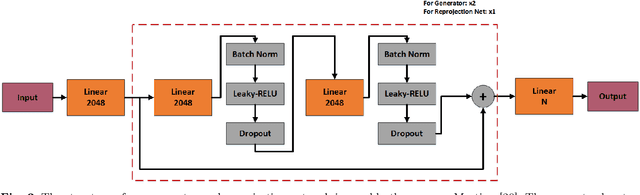
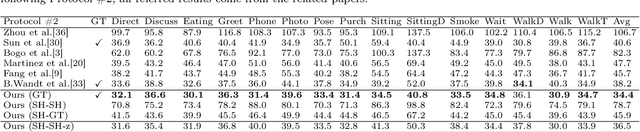
3D human pose estimation is still a challenging problem despite the large amount of work that has been done in this field. Generally, most methods directly use neural networks and ignore certain constraints (e.g., reprojection constraints and joint angle and bone length constraints). This paper proposes a weakly supervised GAN-based model for 3D human pose estimation that considers 3D information along with 2D information simultaneously, in which a reprojection network is employed to learn the mapping of the distribution from 3D poses to 2D poses. In particular, we train the reprojection network and the generative adversarial network synchronously. Furthermore, inspired by the typical kinematic chain space (KCS) matrix, we propose a weighted KCS matrix, which is added into the discriminator's input to impose joint angle and bone length constraints. The experimental results on Human3.6M show that our method outperforms state-of-the-art methods by approximately 5.1\%.
SVMA: A GAN-based model for Monocular 3D Human Pose Estimation
Jun 16, 2021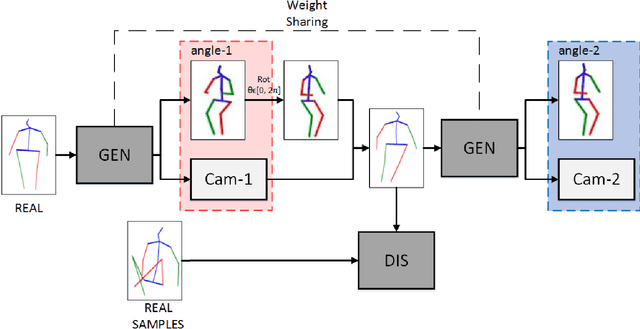
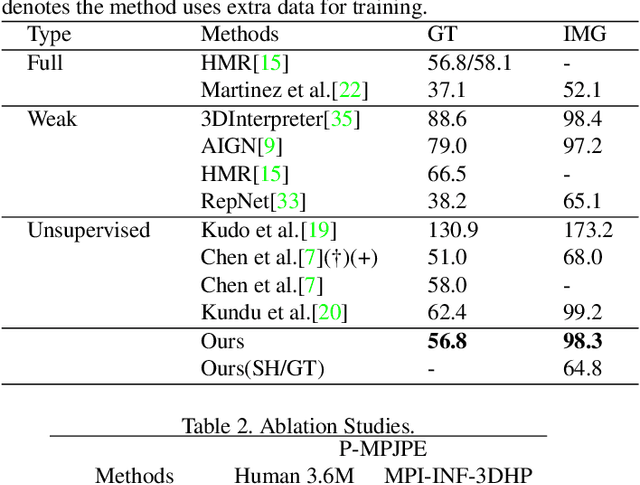
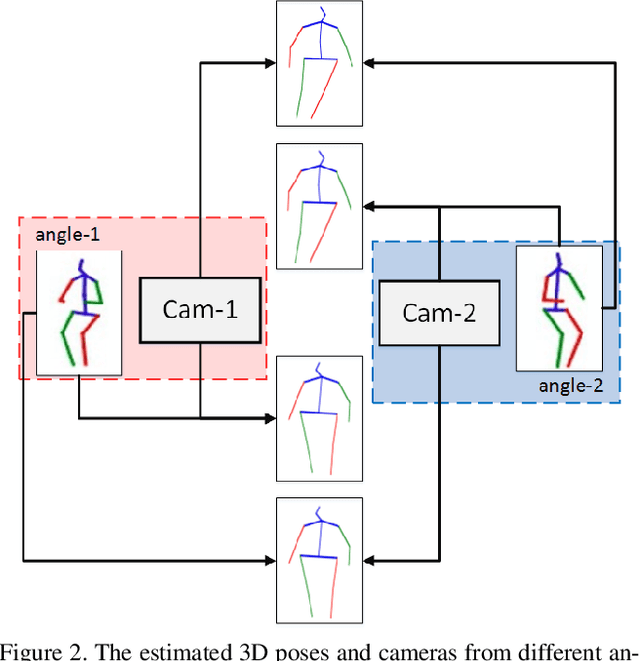
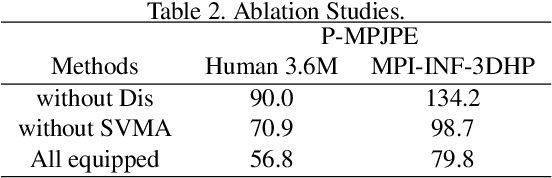
Recovering 3D human pose from 2D joints is a highly unconstrained problem, especially without any video or multi-view information. We present an unsupervised GAN-based model to recover 3D human pose from 2D joint locations extracted from a single image. Our model uses a GAN to learn the mapping of distribution from 2D poses to 3D poses, not the simple 2D-3D correspondence. Considering the reprojection constraint, our model can estimate the camera so that we can reproject the estimated 3D pose to the original 2D pose. Based on this reprojection method, we can rotate and reproject the generated pose to get our "new" 2D pose and then use a weight sharing generator to estimate the "new" 3D pose and a "new" camera. Through the above estimation process, we can define the single-view-multi-angle consistency loss during training to simulate multi-view consistency, which means the 3D poses and cameras estimated from two angles of a single view should be able to be mixed to generate rich 2D reprojections, and the 2D reprojections reprojected from the same 3D pose should be consistent. The experimental results on Human3.6M show that our method outperforms all the state-of-the-art methods, and results on MPI-INF-3DHP show that our method outperforms state-of-the-art by approximately 15.0%.