 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast Sign Retrieval via Sub-band Convolution: An Elementary Extension of Binary Classification
Apr 30, 2025To efficiently compress the sign information of images, we address a sign retrieval problem for the block-wise discrete cosine transformation~(DCT): reconstruction of the signs of DCT coefficients from their amplitudes. To this end, we propose a fast sign retrieval method on the basis of binary classification machine learning. We first introduce 3D representations of the amplitudes and signs, where we pack amplitudes/signs belonging to the same frequency band into a 2D slice, referred to as the sub-band block. We then retrieve the signs from the 3D amplitudes via binary classification, where each sign is regarded as a binary label. We implement a binary classification algorithm using convolutional neural networks, which are advantageous for efficiently extracting features in the 3D amplitudes. Experimental results demonstrate that our method achieves accurate sign retrieval with an overwhelmingly low computation cost.
Holographic Phase Retrieval via Wirtinger Flow: Cartesian Form with Auxiliary Amplitude
Mar 14, 2024
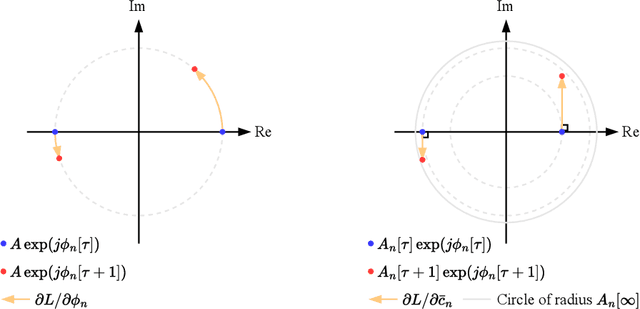


We propose a new gradient method for holography, where a phase-only hologram is parameterized by not only the phase but also amplitude. The key idea of our approach is the formulation of a phase-only hologram using an auxiliary amplitude. We optimize the parameters using the so-called Wirtinger flow algorithm in the Cartesian domain, which is a gradient method defined on the basis of the Wirtinger calculus. At the early stage of optimization, each element of the hologram exists inside a complex circle, and it can take a large gradient while diverging from the origin. This characteristic contributes to accelerating the gradient descent. Meanwhile, at the final stage of optimization, each element evolves along a complex circle, similar to previous state-of-the-art gradient methods. The experimental results demonstrate that our method outperforms previous methods, primarily due to the optimization of the amplitude.
Time-Efficient Light-Field Acquisition Using Coded Aperture and Events
Mar 12, 2024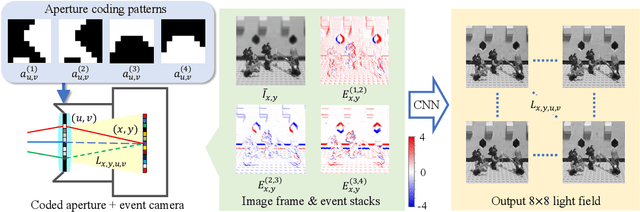
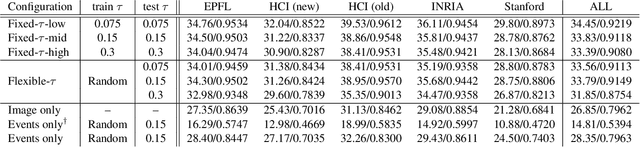
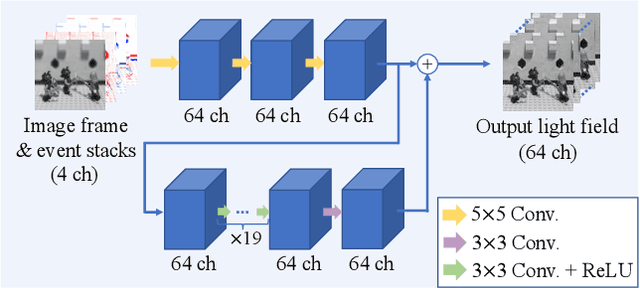
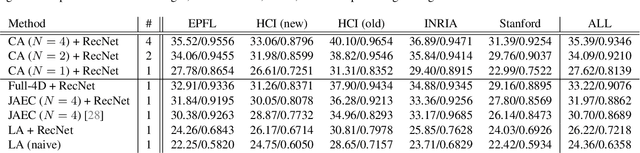
We propose a computational imaging method for time-efficient light-field acquisition that combines a coded aperture with an event-based camera. Different from the conventional coded-aperture imaging method, our method applies a sequence of coding patterns during a single exposure for an image frame. The parallax information, which is related to the differences in coding patterns, is recorded as events. The image frame and events, all of which are measured in a single exposure, are jointly used to computationally reconstruct a light field. We also designed an algorithm pipeline for our method that is end-to-end trainable on the basis of deep optics and compatible with real camera hardware. We experimentally showed that our method can achieve more accurate reconstruction than several other imaging methods with a single exposure. We also developed a hardware prototype with the potential to complete the measurement on the camera within 22 msec and demonstrated that light fields from real 3-D scenes can be obtained with convincing visual quality. Our software and supplementary video are available from our project website.
Reconstructing Continuous Light Field From Single Coded Image
Nov 16, 2023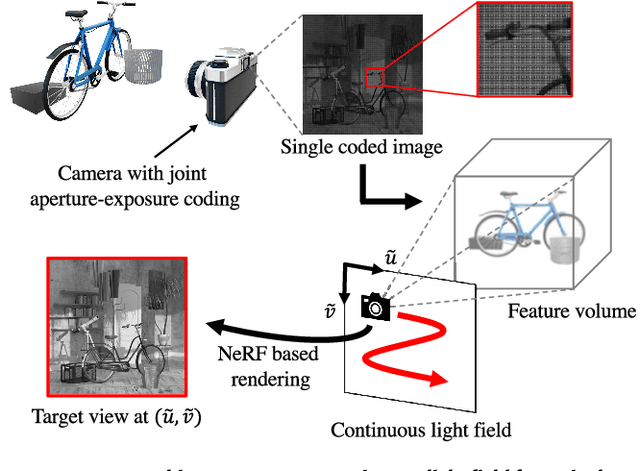

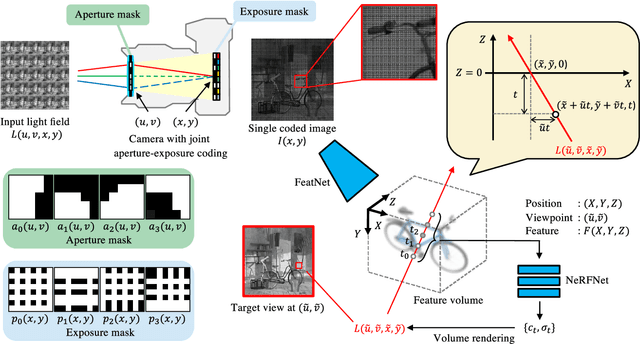

We propose a method for reconstructing a continuous light field of a target scene from a single observed image. Our method takes the best of two worlds: joint aperture-exposure coding for compressive light-field acquisition, and a neural radiance field (NeRF) for view synthesis. Joint aperture-exposure coding implemented in a camera enables effective embedding of 3-D scene information into an observed image, but in previous works, it was used only for reconstructing discretized light-field views. NeRF-based neural rendering enables high quality view synthesis of a 3-D scene from continuous viewpoints, but when only a single image is given as the input, it struggles to achieve satisfactory quality. Our method integrates these two techniques into an efficient and end-to-end trainable pipeline. Trained on a wide variety of scenes, our method can reconstruct continuous light fields accurately and efficiently without any test time optimization. To our knowledge, this is the first work to bridge two worlds: camera design for efficiently acquiring 3-D information and neural rendering.
Compressing Sign Information in DCT-based Image Coding via Deep Sign Retrieval
Sep 21, 2022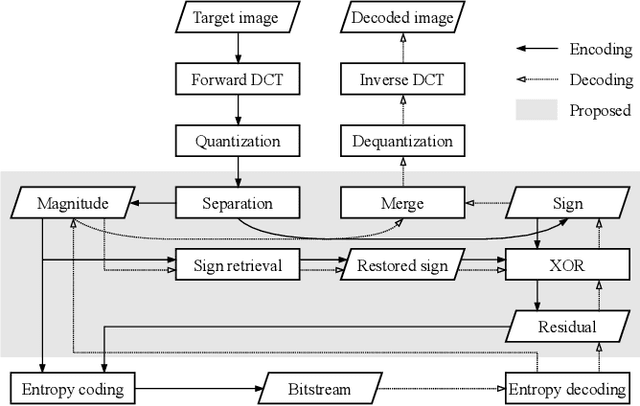

Compressing the sign information of discrete cosine transform (DCT) coefficients is an intractable problem in image coding schemes due to the equiprobable characteristics of the signs. To overcome this difficulty, we propose an efficient compression method for the sign information called "sign retrieval." This method is inspired by phase retrieval, which is a classical signal restoration problem of finding the phase information of discrete Fourier transform coefficients from their magnitudes. The sign information of all DCT coefficients is excluded from a bitstream at the encoder and is complemented at the decoder through our sign retrieval method. We show through experiments that our method outperforms previous ones in terms of the bit amount for the signs and computation cost. Our method, implemented in Python language, is available from https://github.com/ctsutake/dsr.
Acquiring a Dynamic Light Field through a Single-Shot Coded Image
Apr 26, 2022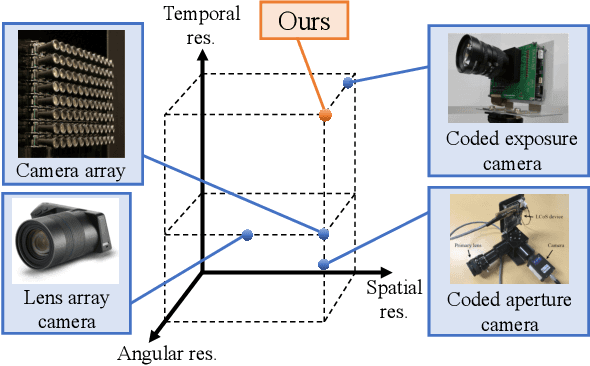
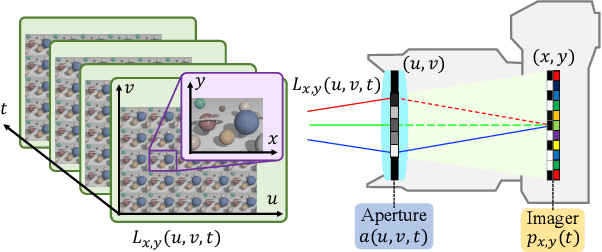
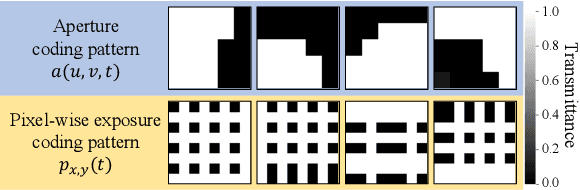

We propose a method for compressively acquiring a dynamic light field (a 5-D volume) through a single-shot coded image (a 2-D measurement). We designed an imaging model that synchronously applies aperture coding and pixel-wise exposure coding within a single exposure time. This coding scheme enables us to effectively embed the original information into a single observed image. The observed image is then fed to a convolutional neural network (CNN) for light-field reconstruction, which is jointly trained with the camera-side coding patterns. We also developed a hardware prototype to capture a real 3-D scene moving over time. We succeeded in acquiring a dynamic light field with 5x5 viewpoints over 4 temporal sub-frames (100 views in total) from a single observed image. Repeating capture and reconstruction processes over time, we can acquire a dynamic light field at 4x the frame rate of the camera. To our knowledge, our method is the first to achieve a finer temporal resolution than the camera itself in compressive light-field acquisition. Our software is available from our project webpage