 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReconstructing Continuous Light Field From Single Coded Image
Paper and Code
Nov 16, 2023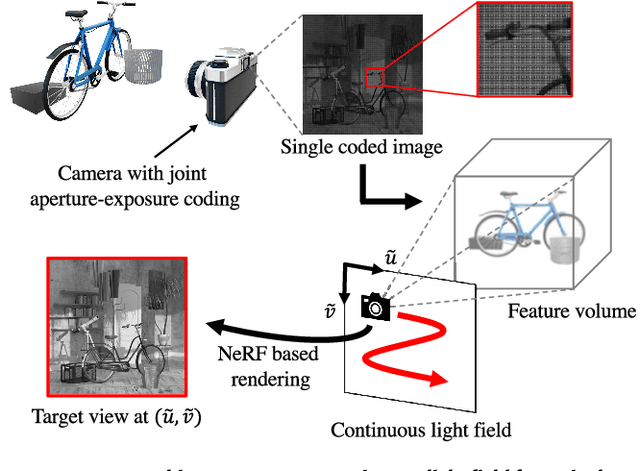

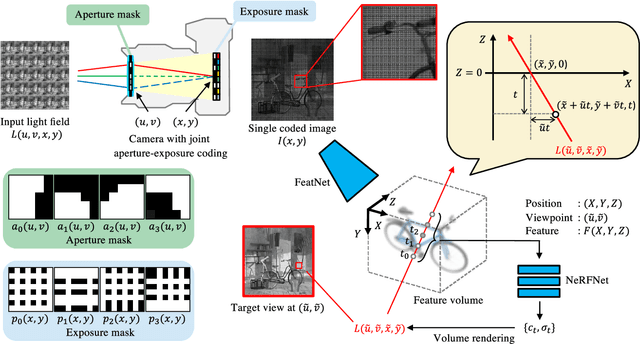

We propose a method for reconstructing a continuous light field of a target scene from a single observed image. Our method takes the best of two worlds: joint aperture-exposure coding for compressive light-field acquisition, and a neural radiance field (NeRF) for view synthesis. Joint aperture-exposure coding implemented in a camera enables effective embedding of 3-D scene information into an observed image, but in previous works, it was used only for reconstructing discretized light-field views. NeRF-based neural rendering enables high quality view synthesis of a 3-D scene from continuous viewpoints, but when only a single image is given as the input, it struggles to achieve satisfactory quality. Our method integrates these two techniques into an efficient and end-to-end trainable pipeline. Trained on a wide variety of scenes, our method can reconstruct continuous light fields accurately and efficiently without any test time optimization. To our knowledge, this is the first work to bridge two worlds: camera design for efficiently acquiring 3-D information and neural rendering.