 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Visual Prompting: Robustness Inheritance and Beyond
Jun 07, 2025Visual Prompting (VP), an efficient method for transfer learning, has shown its potential in vision tasks. However, previous works focus exclusively on VP from standard source models, it is still unknown how it performs under the scenario of a robust source model: Can the robustness of the source model be successfully inherited? Does VP also encounter the same trade-off between robustness and generalization ability as the source model during this process? If such a trade-off exists, is there a strategy specifically tailored to VP to mitigate this limitation? In this paper, we thoroughly explore these three questions for the first time and provide affirmative answers to them. To mitigate the trade-off faced by VP, we propose a strategy called Prompt Boundary Loosening (PBL). As a lightweight, plug-and-play strategy naturally compatible with VP, PBL effectively ensures the successful inheritance of robustness when the source model is a robust model, while significantly enhancing VP's generalization ability across various downstream datasets. Extensive experiments across various datasets show that our findings are universal and demonstrate the significant benefits of the proposed strategy.
Generalized Multimodal Fusion via Poisson-Nernst-Planck Equation
Oct 20, 2024



Previous studies have highlighted significant advancements in multimodal fusion. Nevertheless, such methods often encounter challenges regarding the efficacy of feature extraction, data integrity, consistency of feature dimensions, and adaptability across various downstream tasks. This paper proposes a generalized multimodal fusion method (GMF) via the Poisson-Nernst-Planck (PNP) equation, which adeptly addresses the aforementioned issues. Theoretically, the optimization objective for traditional multimodal tasks is formulated and redefined by integrating information entropy and the flow of gradient backward step. Leveraging these theoretical insights, the PNP equation is applied to feature fusion, rethinking multimodal features through the framework of charged particles in physics and controlling their movement through dissociation, concentration, and reconstruction. Building on these theoretical foundations, GMF disassociated features which extracted by the unimodal feature extractor into modality-specific and modality-invariant subspaces, thereby reducing mutual information and subsequently lowering the entropy of downstream tasks. The identifiability of the feature's origin enables our approach to function independently as a frontend, seamlessly integrated with a simple concatenation backend, or serve as a prerequisite for other modules. Experimental results on multiple downstream tasks show that the proposed GMF achieves performance close to the state-of-the-art (SOTA) accuracy while utilizing fewer parameters and computational resources. Furthermore, by integrating GMF with advanced fusion methods, we surpass the SOTA results.
ReLayout: Towards Real-World Document Understanding via Layout-enhanced Pre-training
Oct 14, 2024Recent approaches for visually-rich document understanding (VrDU) uses manually annotated semantic groups, where a semantic group encompasses all semantically relevant but not obviously grouped words. As OCR tools are unable to automatically identify such grouping, we argue that current VrDU approaches are unrealistic. We thus introduce a new variant of the VrDU task, real-world visually-rich document understanding (ReVrDU), that does not allow for using manually annotated semantic groups. We also propose a new method, ReLayout, compliant with the ReVrDU scenario, which learns to capture semantic grouping through arranging words and bringing the representations of words that belong to the potential same semantic group closer together. Our experimental results demonstrate the performance of existing methods is deteriorated with the ReVrDU task, while ReLayout shows superiour performance.
DiReCT: Diagnostic Reasoning for Clinical Notes via Large Language Models
Aug 06, 2024



Large language models (LLMs) have recently showcased remarkable capabilities, spanning a wide range of tasks and applications, including those in the medical domain. Models like GPT-4 excel in medical question answering but may face challenges in the lack of interpretability when handling complex tasks in real clinical settings. We thus introduce the diagnostic reasoning dataset for clinical notes (DiReCT), aiming at evaluating the reasoning ability and interpretability of LLMs compared to human doctors. It contains 511 clinical notes, each meticulously annotated by physicians, detailing the diagnostic reasoning process from observations in a clinical note to the final diagnosis. Additionally, a diagnostic knowledge graph is provided to offer essential knowledge for reasoning, which may not be covered in the training data of existing LLMs. Evaluations of leading LLMs on DiReCT bring out a significant gap between their reasoning ability and that of human doctors, highlighting the critical need for models that can reason effectively in real-world clinical scenarios.
Towards Robust and Accurate Visual Prompting
Nov 18, 2023Visual prompting, an efficient method for transfer learning, has shown its potential in vision tasks. However, previous works focus exclusively on VP from standard source models, it is still unknown how it performs under the scenario of a robust source model: Whether a visual prompt derived from a robust model can inherit the robustness while suffering from the generalization performance decline, albeit for a downstream dataset that is different from the source dataset? In this work, we get an affirmative answer of the above question and give an explanation on the visual representation level. Moreover, we introduce a novel technique named Prompt Boundary Loose (PBL) to effectively mitigates the suboptimal results of visual prompt on standard accuracy without losing (or even significantly improving) its adversarial robustness when using a robust model as source model. Extensive experiments across various datasets show that our findings are universal and demonstrate the significant benefits of our proposed method.
Concatenated Masked Autoencoders as Spatial-Temporal Learner
Nov 02, 2023
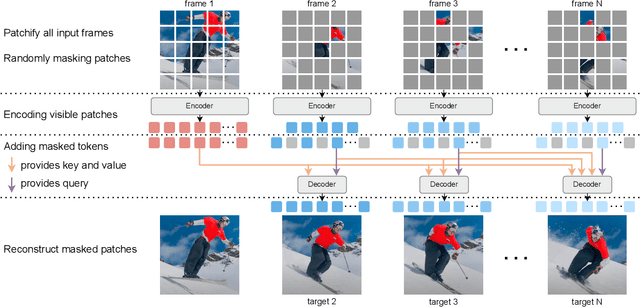
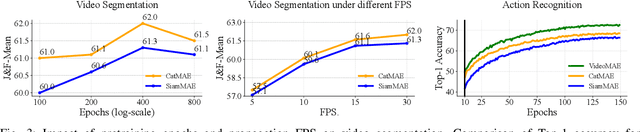

Learning representations from videos requires understanding continuous motion and visual correspondences between frames. In this paper, we introduce the Concatenated Masked Autoencoders (CatMAE) as a spatial-temporal learner for self-supervised video representation learning. For the input sequence of video frames, CatMAE keeps the initial frame unchanged while applying substantial masking (95%) to subsequent frames. The encoder in CatMAE is responsible for encoding visible patches for each frame individually; subsequently, for each masked frame, the decoder leverages visible patches from both previous and current frames to reconstruct the original image. Our proposed method enables the model to estimate the motion information between visible patches, match the correspondences between preceding and succeeding frames, and ultimately learn the evolution of scenes. Furthermore, we propose a new data augmentation strategy, Video-Reverse (ViRe), which uses reversed video frames as the model's reconstruction targets. This further encourages the model to utilize continuous motion details and correspondences to complete the reconstruction, thereby enhancing the model's capabilities. Compared to the most advanced pre-training methods, CatMAE achieves a leading level in video segmentation tasks and action recognition tasks.
IncreLoRA: Incremental Parameter Allocation Method for Parameter-Efficient Fine-tuning
Aug 23, 2023



With the increasing size of pre-trained language models (PLMs), fine-tuning all the parameters in the model is not efficient, especially when there are a large number of downstream tasks, which incur significant training and storage costs. Many parameter-efficient fine-tuning (PEFT) approaches have been proposed, among which, Low-Rank Adaptation (LoRA) is a representative approach that injects trainable rank decomposition matrices into every target module. Yet LoRA ignores the importance of parameters in different modules. To address this problem, many works have been proposed to prune the parameters of LoRA. However, under limited training conditions, the upper bound of the rank of the pruned parameter matrix is still affected by the preset values. We, therefore, propose IncreLoRA, an incremental parameter allocation method that adaptively adds trainable parameters during training based on the importance scores of each module. This approach is different from the pruning method as it is not limited by the initial number of training parameters, and each parameter matrix has a higher rank upper bound for the same training overhead. We conduct extensive experiments on GLUE to demonstrate the effectiveness of IncreLoRA. The results show that our method owns higher parameter efficiency, especially when under the low-resource settings where our method significantly outperforms the baselines. Our code is publicly available.