 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Self-Evolving Agentic Framework for Metasurface Inverse Design
Apr 01, 2026Metasurface inverse design has become central to realizing complex optical functionality, yet translating target responses into executable, solver-compatible workflows still demands specialized expertise in computational electromagnetics and solver-specific software engineering. Recent large language models (LLMs) offer a complementary route to reducing this workflow-construction burden, but existing language-driven systems remain largely session-bounded and do not preserve reusable workflow knowledge across inverse-design tasks. We present an agentic framework for metasurface inverse design that addresses this limitation through context-level skill evolution. The framework couples a coding agent, evolving skill artifacts, and a deterministic evaluator grounded in physical simulation so that solver-specific strategies can be iteratively refined across tasks without modifying model weights or the underlying physics solver. We evaluate the framework on a benchmark spanning multiple metasurface inverse-design task types, with separate training-aligned and held-out task families. Evolved skills raise in-distribution task success from 38% to 74%, increase criteria pass fraction from 0.510 to 0.870, and reduce average attempts from 4.10 to 2.30. On held-out task families, binary success changes only marginally, but improvements in best margin together with shifts in error composition and agent behavior indicate partial transfer of workflow knowledge. These results suggest that the main value of skill evolution lies in accumulating reusable solver-specific expertise around reliable computational engines, thereby offering a practical path toward more autonomous and accessible metasurface inverse-design workflows.
Concatenated Masked Autoencoders as Spatial-Temporal Learner
Nov 02, 2023
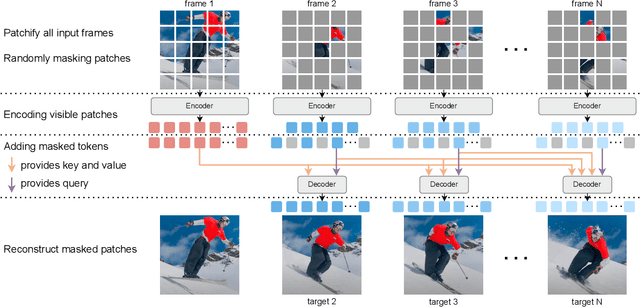
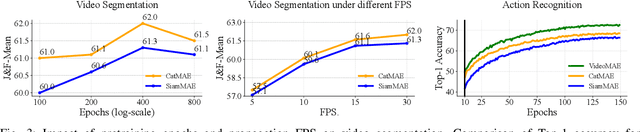

Learning representations from videos requires understanding continuous motion and visual correspondences between frames. In this paper, we introduce the Concatenated Masked Autoencoders (CatMAE) as a spatial-temporal learner for self-supervised video representation learning. For the input sequence of video frames, CatMAE keeps the initial frame unchanged while applying substantial masking (95%) to subsequent frames. The encoder in CatMAE is responsible for encoding visible patches for each frame individually; subsequently, for each masked frame, the decoder leverages visible patches from both previous and current frames to reconstruct the original image. Our proposed method enables the model to estimate the motion information between visible patches, match the correspondences between preceding and succeeding frames, and ultimately learn the evolution of scenes. Furthermore, we propose a new data augmentation strategy, Video-Reverse (ViRe), which uses reversed video frames as the model's reconstruction targets. This further encourages the model to utilize continuous motion details and correspondences to complete the reconstruction, thereby enhancing the model's capabilities. Compared to the most advanced pre-training methods, CatMAE achieves a leading level in video segmentation tasks and action recognition tasks.
Outage Analysis of Aerial Semi-Grant-Free NOMA Systems
May 12, 2022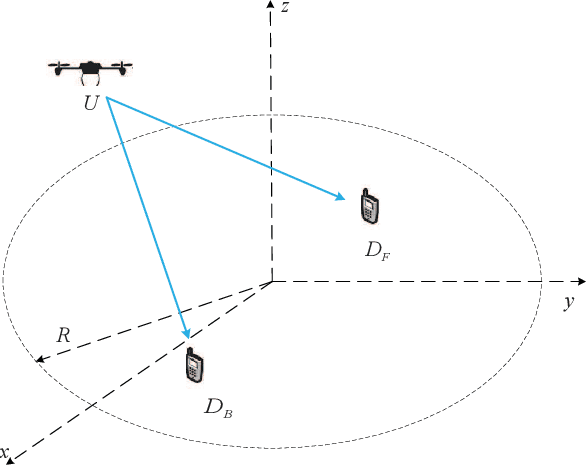
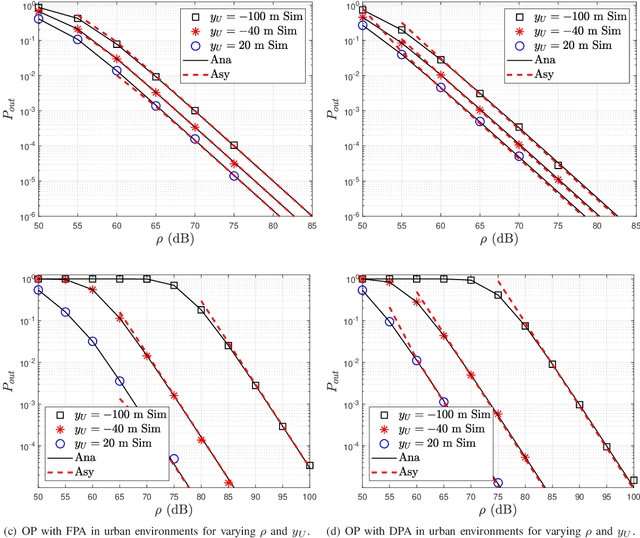
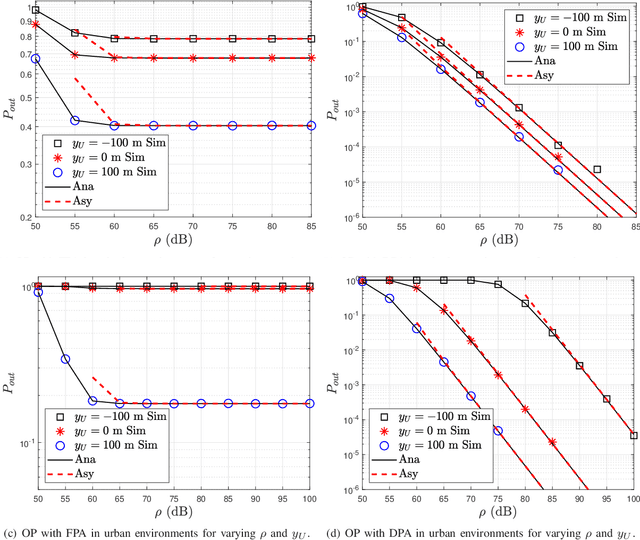

In this paper, we analyze the outage performance of unmanned aerial vehicles (UAVs)-enabled downlink non-orthogonal multiple access (NOMA) communication systems with the semi-grant-free (SGF) transmission scheme. A UAV provides coverage services for a grant-based (GB) user and one user is allowed to utilize the same channel resource opportunistically. The hybrid successive interference cancellation scheme is implemented in the downlink NOMA scenarios for the first time. The analytical expressions for the exact and asymptotic outage probability (OP) of the grant-free (GF) user are derived. The results demonstrate that no-zero diversity order can be achieved only under stringent conditions on users' quality of service requirements. Subsequently, we propose an efficient dynamic power allocation (DPA) scheme to relax such data rate constraints to address this issue. The analytical expressions for the exact and asymptotic OP of the GF user with the DPA scheme are derived. Finally, Monte Carlo simulation results are presented to validate the correctness of the derived analytical expressions and demonstrate the effects of the UAV's location and altitude on the OP of the GF user.
Deep Convolutional Neural Networks to Predict Mutual Coupling Effects in Metasurfaces
Feb 02, 2021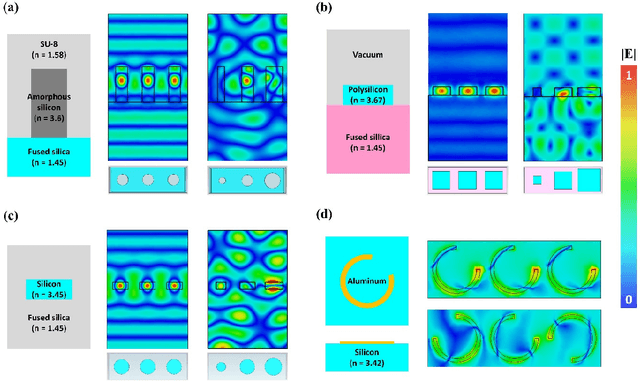
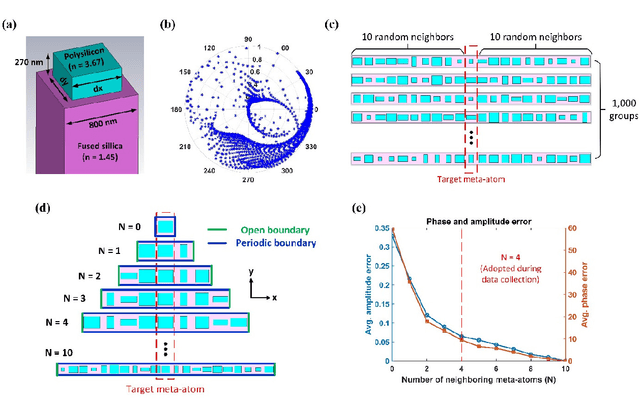
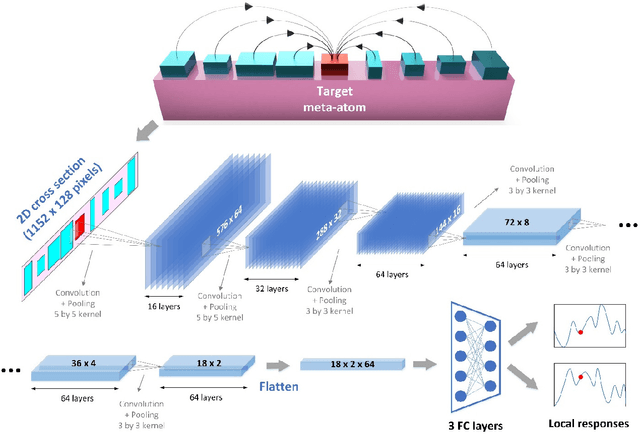
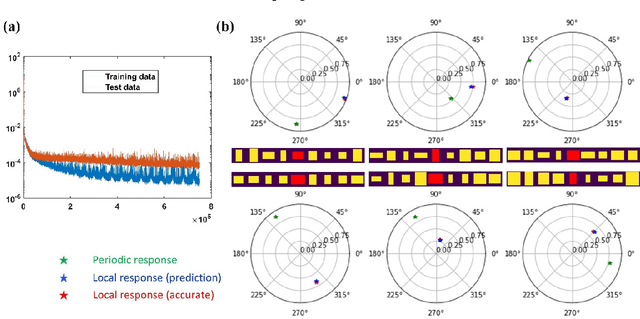
Metasurfaces have provided a novel and promising platform for the realization of compact and large-scale optical devices. The conventional metasurface design approach assumes periodic boundary conditions for each element, which is inaccurate in most cases since the near-field coupling effects between elements will change when surrounded by non-identical structures. In this paper, we propose a deep learning approach to predict the actual electromagnetic (EM) responses of each target meta-atom placed in a large array with near-field coupling effects taken into account. The predicting neural network takes the physical specifications of the target meta-atom and its neighbors as input, and calculates its phase and amplitude in milliseconds. This approach can be applied to explain metasurfaces' performance deterioration caused by mutual coupling and further used to optimize their efficiencies once combined with optimization algorithms. To demonstrate the efficacy of this methodology, we obtain large improvements in efficiency for a beam deflector and a metalens over the conventional design approach. Moreover, we show the correlations between a metasurface's performance and its design errors caused by mutual coupling are not bound to certain specifications (materials, shapes, etc.). As such, we envision that this approach can be readily applied to explore the mutual coupling effects and improve the performance of various metasurface designs.
A Freeform Dielectric Metasurface Modeling Approach Based on Deep Neural Networks
Jan 01, 2020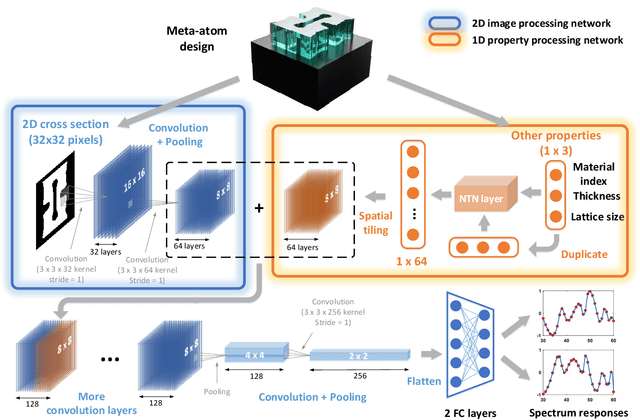
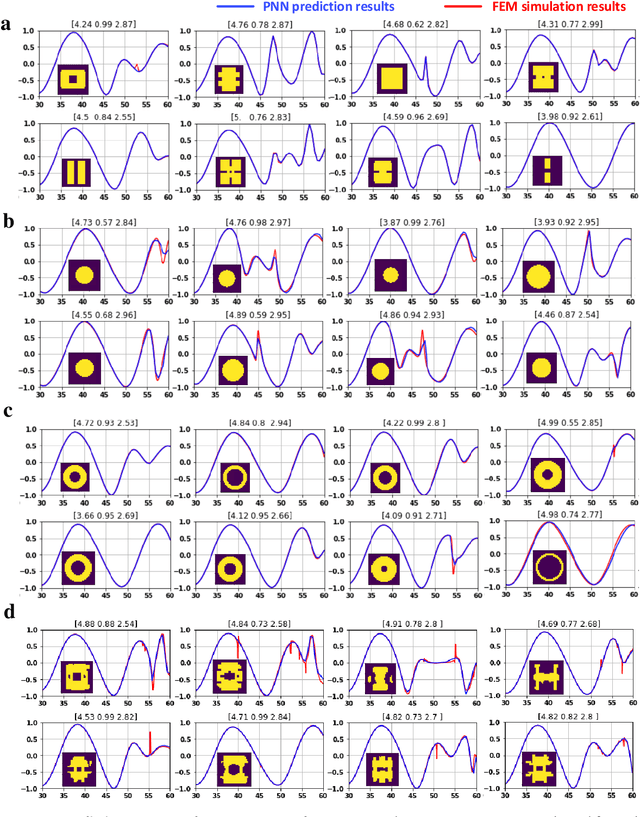
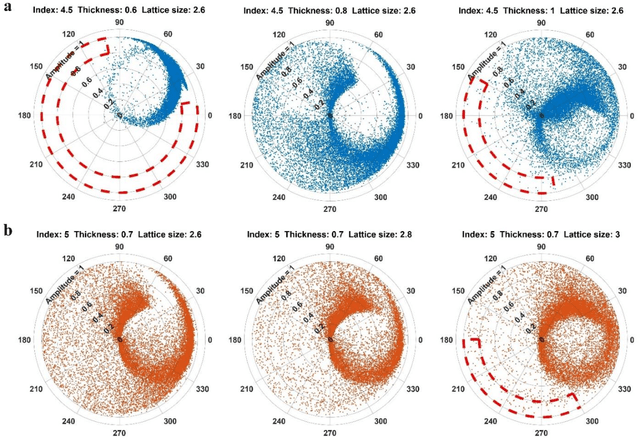
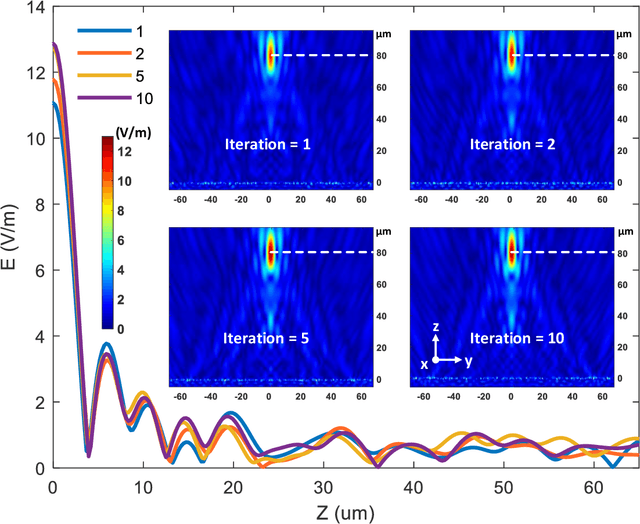
Metasurfaces have shown promising potentials in shaping optical wavefronts while remaining compact compared to bulky geometric optics devices. Design of meta-atoms, the fundamental building blocks of metasurfaces, relies on trial-and-error method to achieve target electromagnetic responses. This process includes the characterization of an enormous amount of different meta-atom designs with different physical and geometric parameters, which normally demands huge computational resources. In this paper, a deep learning-based metasurface/meta-atom modeling approach is introduced to significantly reduce the characterization time while maintaining accuracy. Based on a convolutional neural network (CNN) structure, the proposed deep learning network is able to model meta-atoms with free-form 2D patterns and different lattice sizes, material refractive indexes and thicknesses. Moreover, the presented approach features the capability to predict meta-atoms' wide spectrum responses in the timescale of milliseconds, which makes it attractive for applications such as fast meta-atom/metasurface on-demand designs and optimizations.
Controllable Length Control Neural Encoder-Decoder via Reinforcement Learning
Sep 17, 2019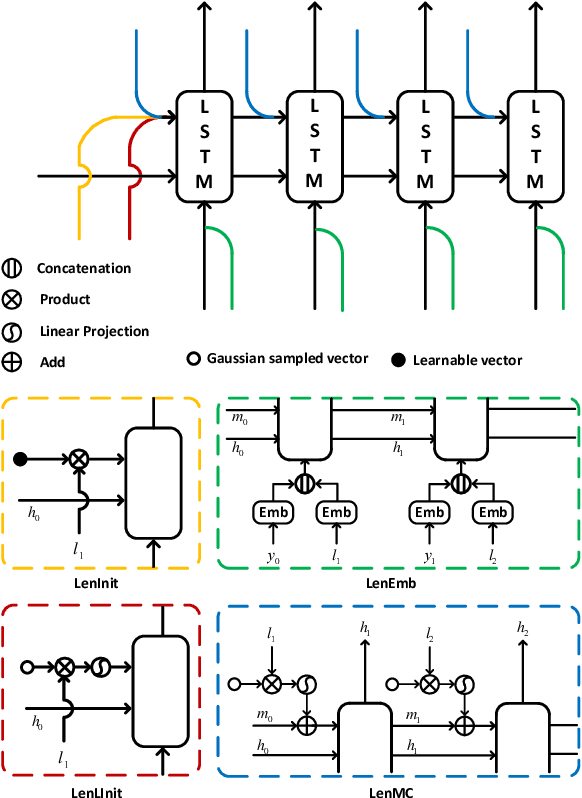

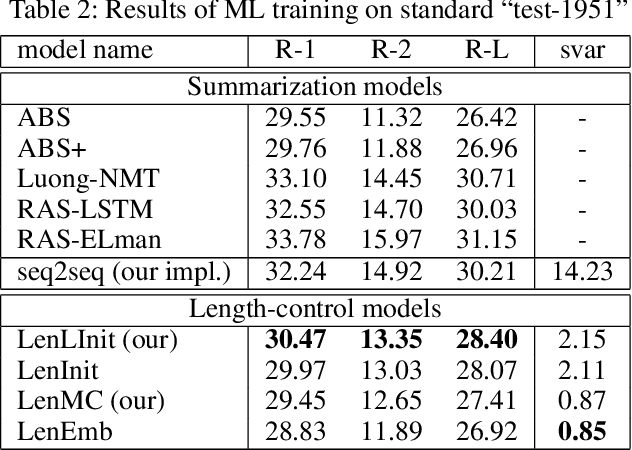
Controlling output length in neural language generation is valuable in many scenarios, especially for the tasks that have length constraints. A model with stronger length control capacity can produce sentences with more specific length, however, it usually sacrifices semantic accuracy of the generated sentences. Here, we denote a concept of Controllable Length Control (CLC) for the trade-off between length control capacity and semantic accuracy of the language generation model. More specifically, CLC is to alter length control capacity of the model so as to generate sentence with corresponding quality. This is meaningful in real applications when length control capacity and outputs quality are requested with different priorities, or to overcome unstability of length control during model training. In this paper, we propose two reinforcement learning (RL) methods to adjust the trade-off between length control capacity and semantic accuracy of length control models. Results show that our RL methods improve scores across a wide range of target lengths and achieve the goal of CLC. Additionally, two models LenMC and LenLInit modified on previous length-control models are proposed to obtain better performance in summarization task while still maintain the ability to control length.
Generative Multi-Functional Meta-Atom and Metasurface Design Networks
Aug 13, 2019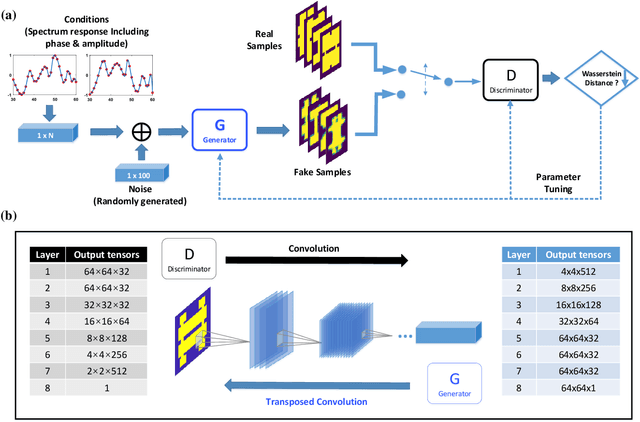
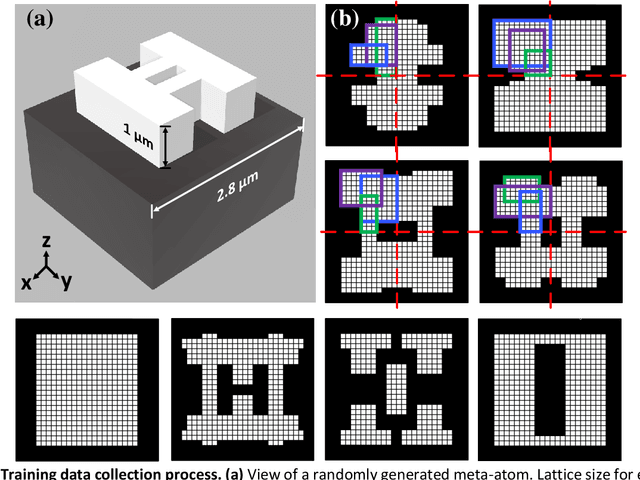
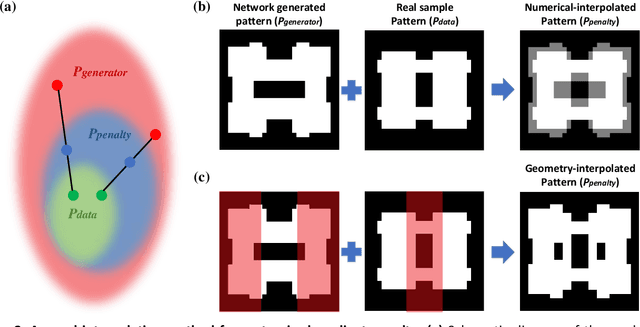
Metasurfaces are being widely investigated and adopted for their promising performances in manipulating optical wavefronts and their potential for integrating multi-functionalities into one flat optical device. A key challenge in metasurface design is the non-intuitive design process that produces models and patterns from specific design requirements (commonly electromagnetic responses). A complete exploration of all design spaces can produce optimal designs but is unrealistic considering the massive amount of computation power required to explore large parameter spaces. Meanwhile, machine learning techniques, especially generative adversarial networks, have proven to be an effective solution to non-intuitive design tasks. In this paper, we present a novel conditional generative network that can generate meta-atom/metasurface designs based on different performance requirements. Compared to conventional trial-and-error or iterative optimization design methods, this new methodology is capable of producing on-demand freeform designs on a one-time calculation basis. More importantly, an increased complexity of design goals doesn't introduce further complexity into the network structure or the training process, which makes this approach suitable for multi-functional device designs. Compared to previous deep learning-based metasurface approaches, our network structure is extremely robust to train and converge, and is readily expanded to many multi-functional metasurface devices, including metasurface filters, lenses and holograms.
A Novel Modeling Approach for All-Dielectric Metasurfaces Using Deep Neural Networks
Jun 08, 2019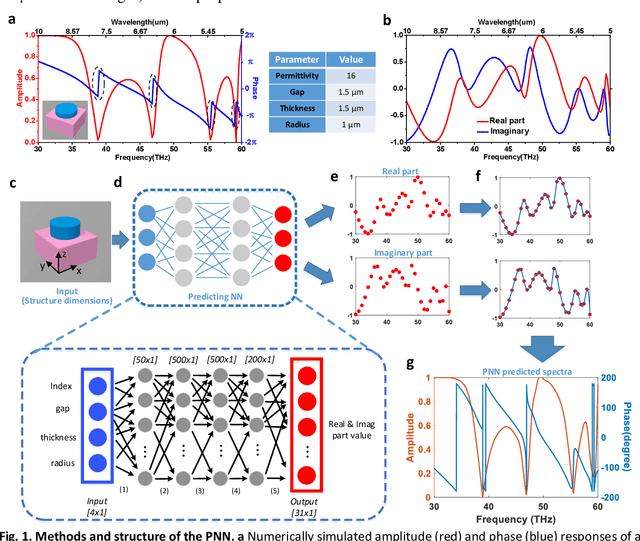
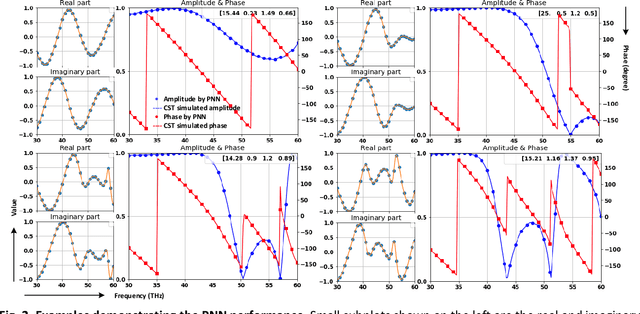
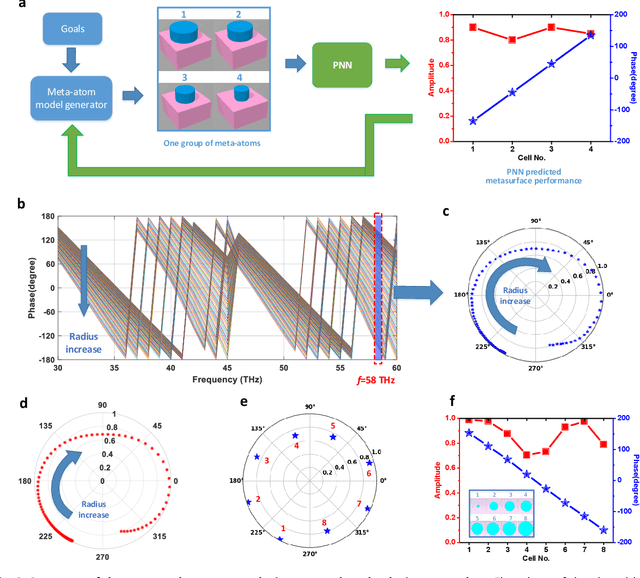
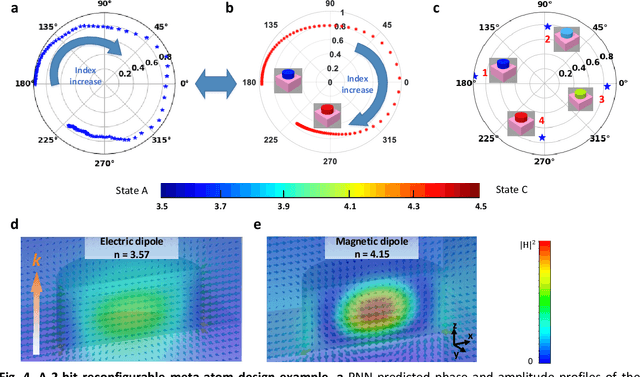
Metasurfaces have become a promising means for manipulating optical wavefronts in flat and high-performance optical devices. Conventional metasurface device design relies on trial-and-error methods to obtain target electromagnetic (EM) response, an approach that demands significant efforts to investigate the enormous number of possible meta-atom structures. In this paper, a deep neural network approach is introduced that significantly improves on both speed and accuracy compared to techniques currently used to assemble metasurface-based devices. Our neural network approach overcomes three key challenges that have limited previous neural-network-based design schemes: input/output vector dimensional mismatch, accurate EM-wave phase prediction, as well as adaptation to 3-D dielectric structures, and can be generically applied to a wide variety of metasurface device designs across the entire electromagnetic spectrum. Using this new methodology, examples of neural networks capable of producing on-demand designs for meta-atoms, metasurface filters, and phase-change reconfigurable metasurfaces are demonstrated.
Classification of normal/abnormal heart sound recordings based on multi-domain features and back propagation neural network
Oct 17, 2018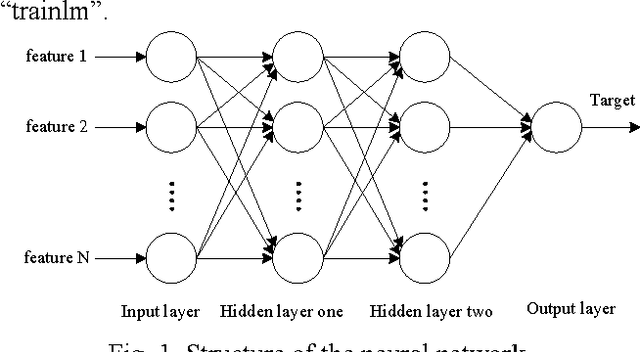

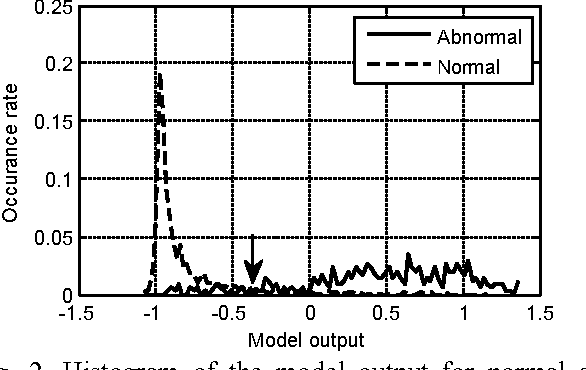
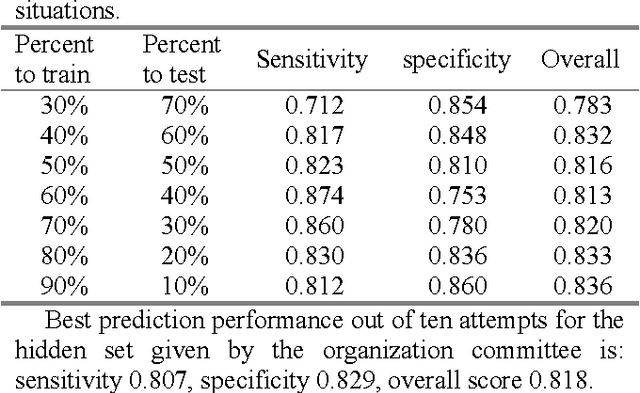
This paper aims to classify a single PCG recording as normal or abnormal for computer-aided diagnosis. The proposed framework for this challenge has four steps: preprocessing, feature extraction, training and validation. In the preprocessing step, a recording is segmented into four states, i.e., the first heart sound, systolic interval, the second heart sound, and diastolic interval by the Springer Segmentation algorithm. In the feature extraction step, the authors extract 324 features from multi-domains to perform classification. A back propagation neural network is used as predication model. The optimal threshold for distinguishing normal and abnormal is determined by the statistics of model output for both normal and abnormal. The performance of the proposed predictor tested by the six training sets is sensitivity 0.812 and specificity 0.860 (overall accuracy is 0.836). However, the performance reduces to sensitivity 0.807 and specificity 0.829 (overall accuracy is 0.818) for the hidden test set.
* 4 pages
Modeling Loosely Annotated Images with Imagined Annotations
May 29, 2008
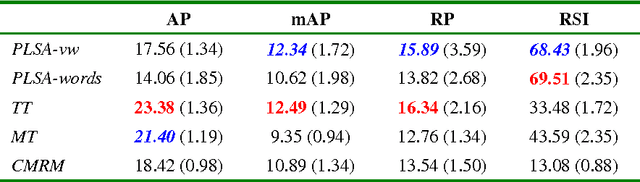
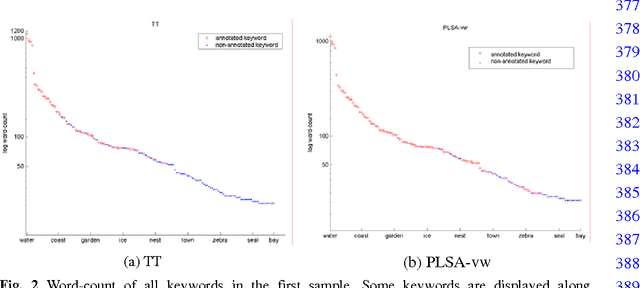
In this paper, we present an approach to learning latent semantic analysis models from loosely annotated images for automatic image annotation and indexing. The given annotation in training images is loose due to: (1) ambiguous correspondences between visual features and annotated keywords; (2) incomplete lists of annotated keywords. The second reason motivates us to enrich the incomplete annotation in a simple way before learning topic models. In particular, some imagined keywords are poured into the incomplete annotation through measuring similarity between keywords. Then, both given and imagined annotations are used to learning probabilistic topic models for automatically annotating new images. We conduct experiments on a typical Corel dataset of images and loose annotations, and compare the proposed method with state-of-the-art discrete annotation methods (using a set of discrete blobs to represent an image). The proposed method improves word-driven probability Latent Semantic Analysis (PLSA-words) up to a comparable performance with the best discrete annotation method, while a merit of PLSA-words is still kept, i.e., a wider semantic range.