 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConcatenated Masked Autoencoders as Spatial-Temporal Learner
Nov 02, 2023
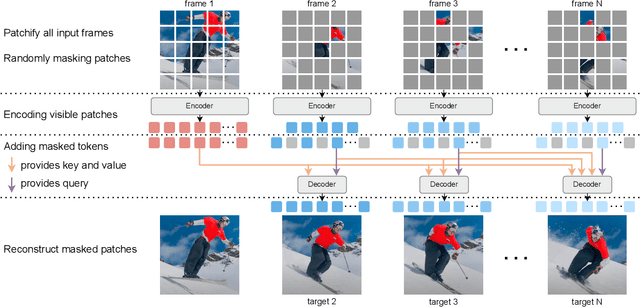
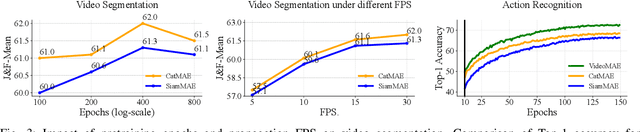

Learning representations from videos requires understanding continuous motion and visual correspondences between frames. In this paper, we introduce the Concatenated Masked Autoencoders (CatMAE) as a spatial-temporal learner for self-supervised video representation learning. For the input sequence of video frames, CatMAE keeps the initial frame unchanged while applying substantial masking (95%) to subsequent frames. The encoder in CatMAE is responsible for encoding visible patches for each frame individually; subsequently, for each masked frame, the decoder leverages visible patches from both previous and current frames to reconstruct the original image. Our proposed method enables the model to estimate the motion information between visible patches, match the correspondences between preceding and succeeding frames, and ultimately learn the evolution of scenes. Furthermore, we propose a new data augmentation strategy, Video-Reverse (ViRe), which uses reversed video frames as the model's reconstruction targets. This further encourages the model to utilize continuous motion details and correspondences to complete the reconstruction, thereby enhancing the model's capabilities. Compared to the most advanced pre-training methods, CatMAE achieves a leading level in video segmentation tasks and action recognition tasks.