 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeControllable Length Control Neural Encoder-Decoder via Reinforcement Learning
Sep 17, 2019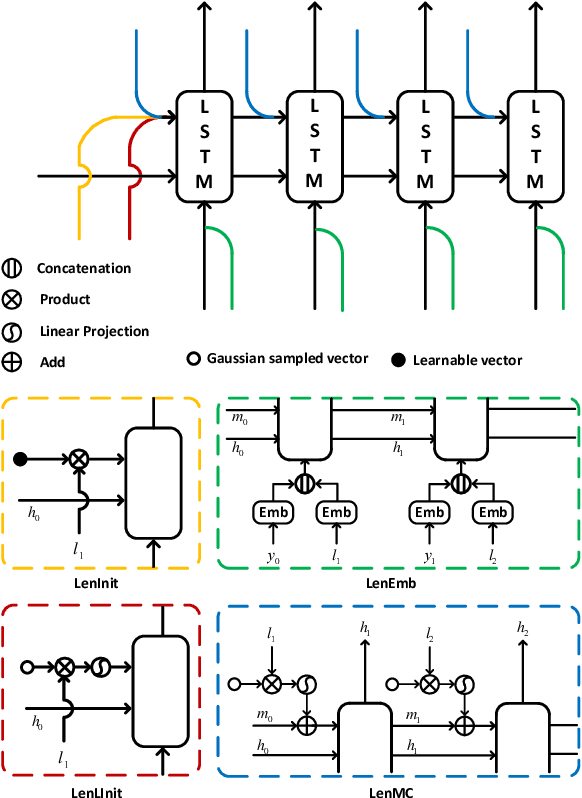

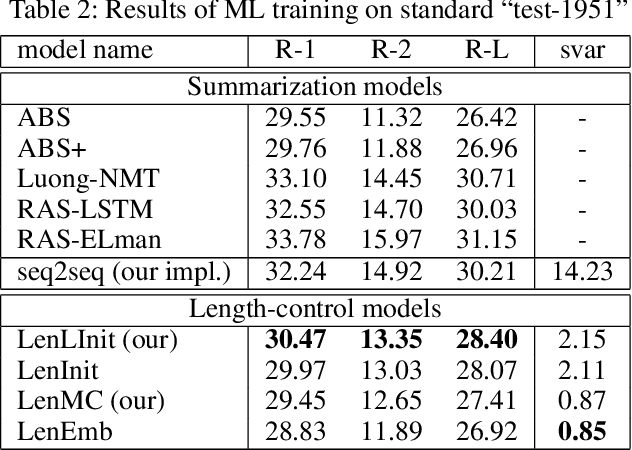
Controlling output length in neural language generation is valuable in many scenarios, especially for the tasks that have length constraints. A model with stronger length control capacity can produce sentences with more specific length, however, it usually sacrifices semantic accuracy of the generated sentences. Here, we denote a concept of Controllable Length Control (CLC) for the trade-off between length control capacity and semantic accuracy of the language generation model. More specifically, CLC is to alter length control capacity of the model so as to generate sentence with corresponding quality. This is meaningful in real applications when length control capacity and outputs quality are requested with different priorities, or to overcome unstability of length control during model training. In this paper, we propose two reinforcement learning (RL) methods to adjust the trade-off between length control capacity and semantic accuracy of length control models. Results show that our RL methods improve scores across a wide range of target lengths and achieve the goal of CLC. Additionally, two models LenMC and LenLInit modified on previous length-control models are proposed to obtain better performance in summarization task while still maintain the ability to control length.
Hybrid Function Sparse Representation towards Image Super Resolution
Jun 11, 2019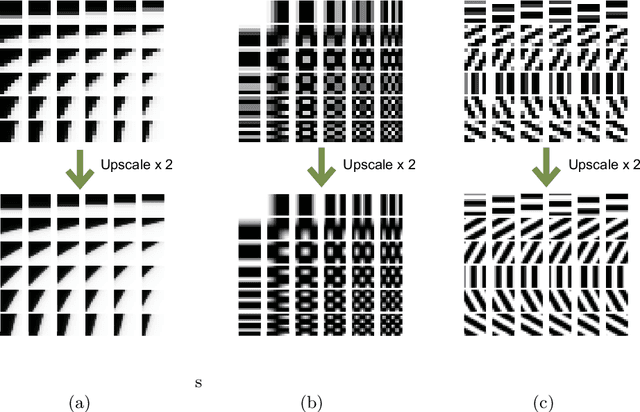
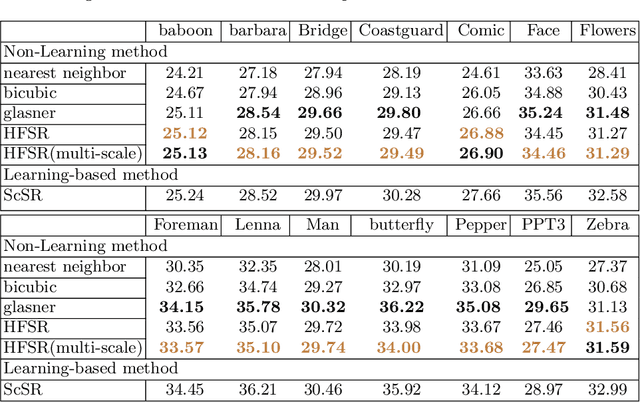
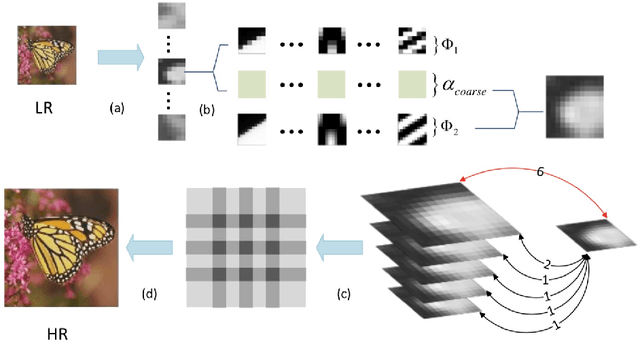

Sparse representation with training-based dictionary has been shown successful on super resolution(SR) but still have some limitations. Based on the idea of making the magnification of function curve without losing its fidelity, we proposed a function based dictionary on sparse representation for super resolution, called hybrid function sparse representation (HFSR). The dictionary we designed is directly generated by preset hybrid functions without additional training, which can be scaled to any size as is required due to its scalable property. We mixed approximated Heaviside function (AHF), sine function and DCT function as the dictionary. Multi-scale refinement is then proposed to utilize the scalable property of the dictionary to improve the results. In addition, a reconstruct strategy is adopted to deal with the overlaps. The experiments on Set14 SR dataset show that our method has an excellent performance particularly with regards to images containing rich details and contexts compared with non-learning based state-of-the art methods.