 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHELLaMA: LLaMA-based Table to Text Generation by Highlighting the Important Evidence
Nov 15, 2023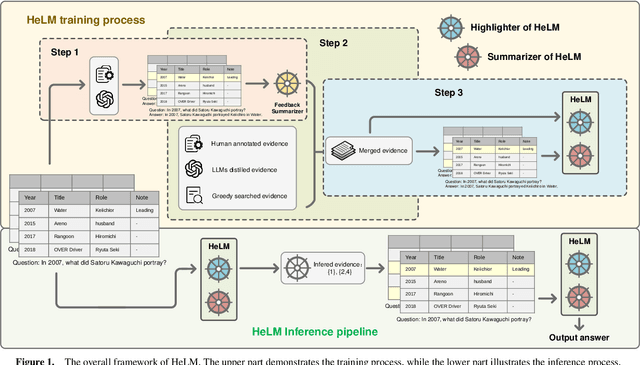
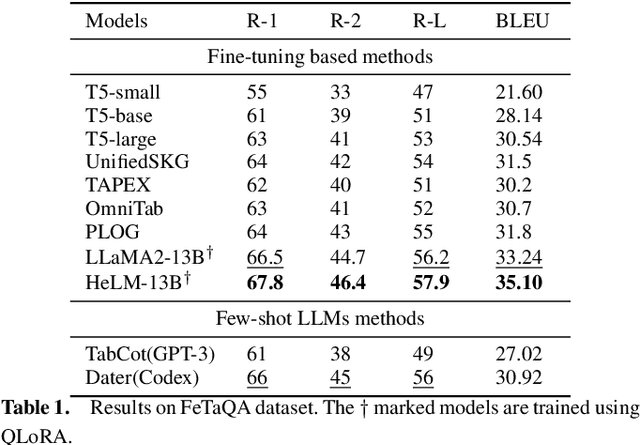

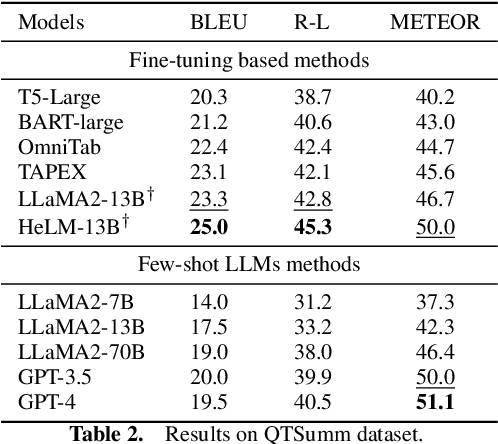
Large models have demonstrated significant progress across various domains, particularly in tasks related to text generation. In the domain of Table to Text, many Large Language Model (LLM)-based methods currently resort to modifying prompts to invoke public APIs, incurring potential costs and information leaks. With the advent of open-source large models, fine-tuning LLMs has become feasible. In this study, we conducted parameter-efficient fine-tuning on the LLaMA2 model. Distinguishing itself from previous fine-tuning-based table-to-text methods, our approach involves injecting reasoning information into the input by emphasizing table-specific row data. Our model consists of two modules: 1) a table reasoner that identifies relevant row evidence, and 2) a table summarizer that generates sentences based on the highlighted table. To facilitate this, we propose a search strategy to construct reasoning labels for training the table reasoner. On both the FetaQA and QTSumm datasets, our approach achieved state-of-the-art results. Additionally, we observed that highlighting input tables significantly enhances the model's performance and provides valuable interpretability.
Inspire the Large Language Model by External Knowledge on BioMedical Named Entity Recognition
Sep 21, 2023



Large language models (LLMs) have demonstrated dominating performance in many NLP tasks, especially on generative tasks. However, they often fall short in some information extraction tasks, particularly those requiring domain-specific knowledge, such as Biomedical Named Entity Recognition (NER). In this paper, inspired by Chain-of-thought, we leverage the LLM to solve the Biomedical NER step-by-step: break down the NER task into entity span extraction and entity type determination. Additionally, for entity type determination, we inject entity knowledge to address the problem that LLM's lack of domain knowledge when predicting entity category. Experimental results show a significant improvement in our two-step BioNER approach compared to previous few-shot LLM baseline. Additionally, the incorporation of external knowledge significantly enhances entity category determination performance.
DMNER: Biomedical Entity Recognition by Detection and Matching
Jul 05, 2023
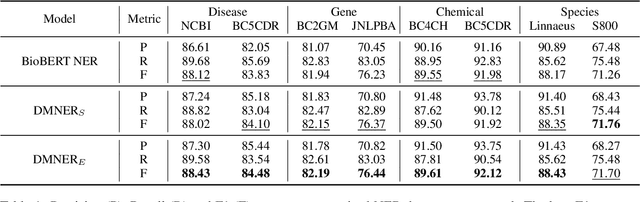
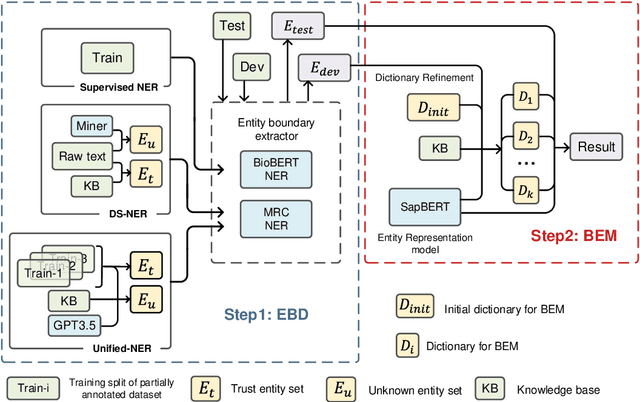
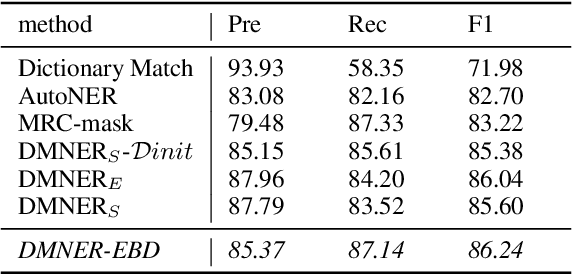
Biomedical named entity recognition (BNER) serves as the foundation for numerous biomedical text mining tasks. Unlike general NER, BNER require a comprehensive grasp of the domain, and incorporating external knowledge beyond training data poses a significant challenge. In this study, we propose a novel BNER framework called DMNER. By leveraging existing entity representation models SAPBERT, we tackle BNER as a two-step process: entity boundary detection and biomedical entity matching. DMNER exhibits applicability across multiple NER scenarios: 1) In supervised NER, we observe that DMNER effectively rectifies the output of baseline NER models, thereby further enhancing performance. 2) In distantly supervised NER, combining MRC and AutoNER as span boundary detectors enables DMNER to achieve satisfactory results. 3) For training NER by merging multiple datasets, we adopt a framework similar to DS-NER but additionally leverage ChatGPT to obtain high-quality phrases in the training. Through extensive experiments conducted on 10 benchmark datasets, we demonstrate the versatility and effectiveness of DMNER.
GoSum: Extractive Summarization of Long Documents by Reinforcement Learning and Graph Organized discourse state
Nov 18, 2022



Handling long texts with structural information and excluding redundancy between summary sentences are essential in extractive document summarization. In this work, we propose GoSum, a novel reinforcement-learning-based extractive model for long-paper summarization. GoSum encodes states by building a heterogeneous graph from different discourse levels for each input document. We evaluate the model on two datasets of scientific articles summarization: PubMed and arXiv where it outperforms all extractive summarization models and most of the strong abstractive baselines.
Controllable Length Control Neural Encoder-Decoder via Reinforcement Learning
Sep 17, 2019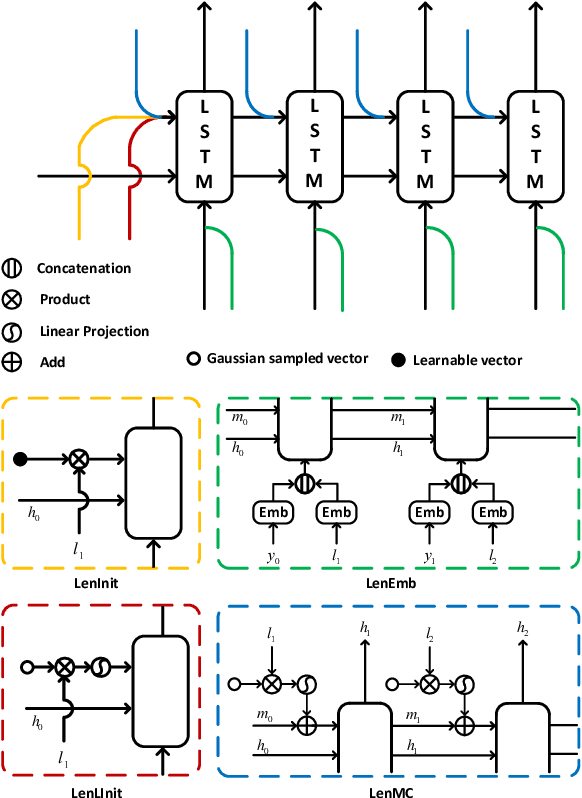

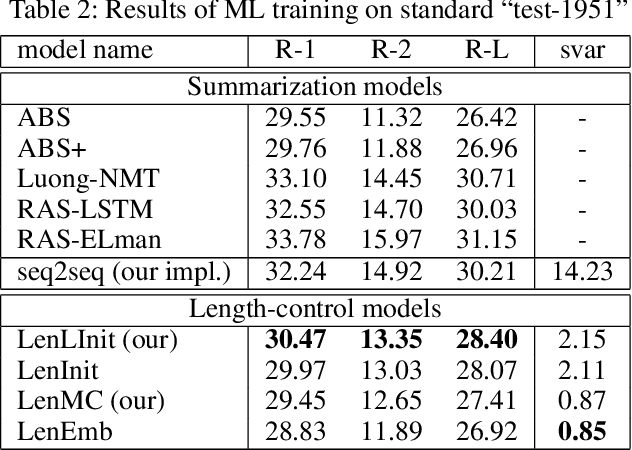
Controlling output length in neural language generation is valuable in many scenarios, especially for the tasks that have length constraints. A model with stronger length control capacity can produce sentences with more specific length, however, it usually sacrifices semantic accuracy of the generated sentences. Here, we denote a concept of Controllable Length Control (CLC) for the trade-off between length control capacity and semantic accuracy of the language generation model. More specifically, CLC is to alter length control capacity of the model so as to generate sentence with corresponding quality. This is meaningful in real applications when length control capacity and outputs quality are requested with different priorities, or to overcome unstability of length control during model training. In this paper, we propose two reinforcement learning (RL) methods to adjust the trade-off between length control capacity and semantic accuracy of length control models. Results show that our RL methods improve scores across a wide range of target lengths and achieve the goal of CLC. Additionally, two models LenMC and LenLInit modified on previous length-control models are proposed to obtain better performance in summarization task while still maintain the ability to control length.
Hybrid Function Sparse Representation towards Image Super Resolution
Jun 11, 2019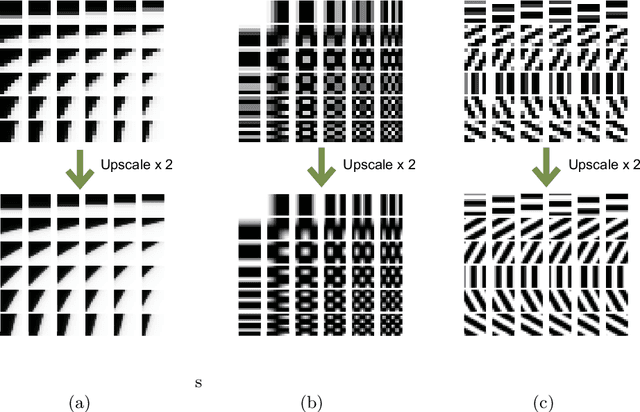
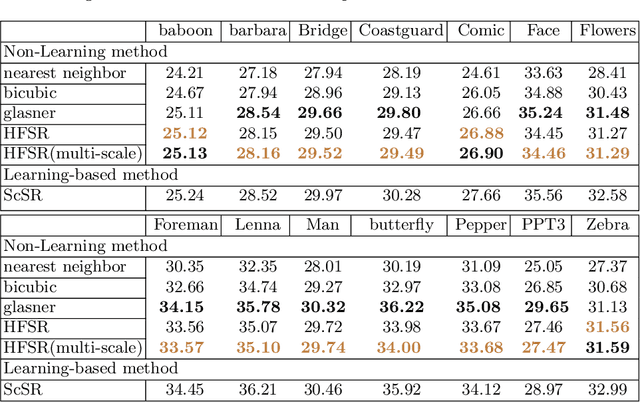
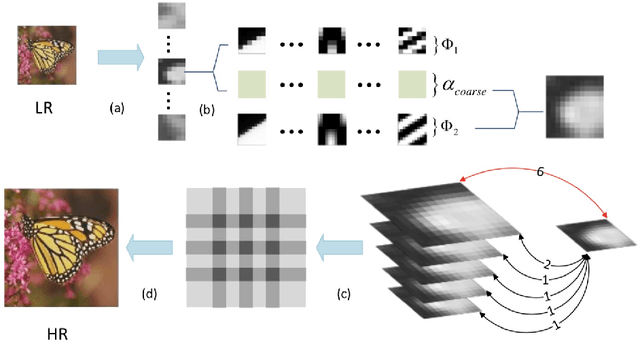

Sparse representation with training-based dictionary has been shown successful on super resolution(SR) but still have some limitations. Based on the idea of making the magnification of function curve without losing its fidelity, we proposed a function based dictionary on sparse representation for super resolution, called hybrid function sparse representation (HFSR). The dictionary we designed is directly generated by preset hybrid functions without additional training, which can be scaled to any size as is required due to its scalable property. We mixed approximated Heaviside function (AHF), sine function and DCT function as the dictionary. Multi-scale refinement is then proposed to utilize the scalable property of the dictionary to improve the results. In addition, a reconstruct strategy is adopted to deal with the overlaps. The experiments on Set14 SR dataset show that our method has an excellent performance particularly with regards to images containing rich details and contexts compared with non-learning based state-of-the art methods.