 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHELLaMA: LLaMA-based Table to Text Generation by Highlighting the Important Evidence
Nov 15, 2023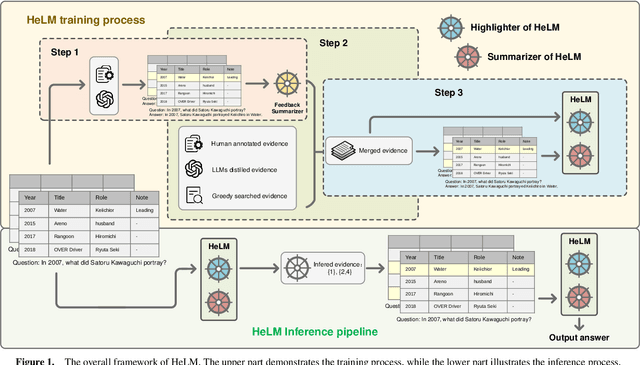
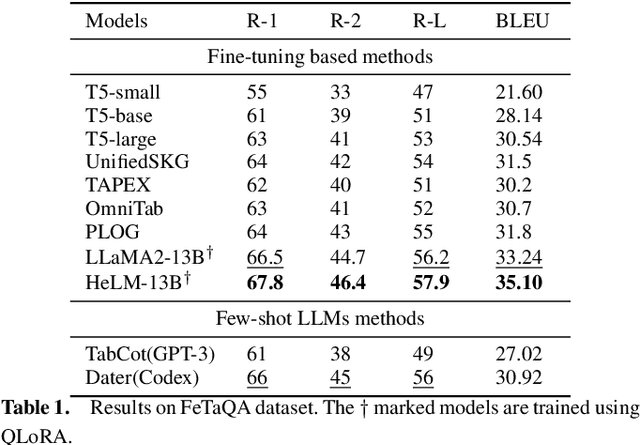

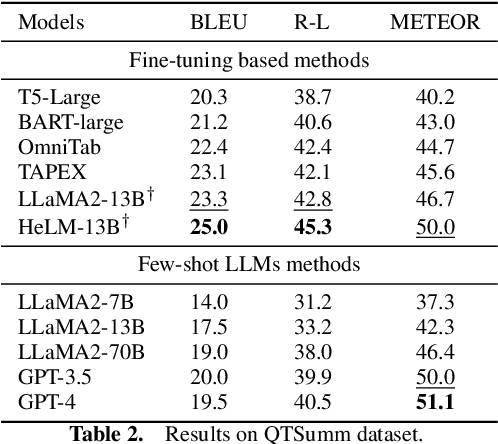
Large models have demonstrated significant progress across various domains, particularly in tasks related to text generation. In the domain of Table to Text, many Large Language Model (LLM)-based methods currently resort to modifying prompts to invoke public APIs, incurring potential costs and information leaks. With the advent of open-source large models, fine-tuning LLMs has become feasible. In this study, we conducted parameter-efficient fine-tuning on the LLaMA2 model. Distinguishing itself from previous fine-tuning-based table-to-text methods, our approach involves injecting reasoning information into the input by emphasizing table-specific row data. Our model consists of two modules: 1) a table reasoner that identifies relevant row evidence, and 2) a table summarizer that generates sentences based on the highlighted table. To facilitate this, we propose a search strategy to construct reasoning labels for training the table reasoner. On both the FetaQA and QTSumm datasets, our approach achieved state-of-the-art results. Additionally, we observed that highlighting input tables significantly enhances the model's performance and provides valuable interpretability.
LatEval: An Interactive LLMs Evaluation Benchmark with Incomplete Information from Lateral Thinking Puzzles
Aug 21, 2023



With the continuous evolution and refinement of LLMs, they are endowed with impressive logical reasoning or vertical thinking capabilities. But can they think out of the box? Do they possess proficient lateral thinking abilities? Following the setup of Lateral Thinking Puzzles, we propose a novel evaluation benchmark, LatEval, which assesses the model's lateral thinking within an interactive framework. In our benchmark, we challenge LLMs with 2 aspects: the quality of questions posed by the model and the model's capability to integrate information for problem-solving. We find that nearly all LLMs struggle with employing lateral thinking during interactions. For example, even the most advanced model, GPT-4, exhibits the advantage to some extent, yet still maintain a noticeable gap when compared to human. This evaluation benchmark provides LLMs with a highly challenging and distinctive task that is crucial to an effective AI assistant.
SARG: A Novel Semi Autoregressive Generator for Multi-turn Incomplete Utterance Restoration
Aug 20, 2020
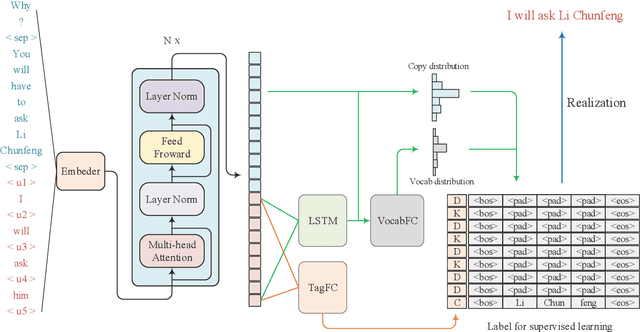
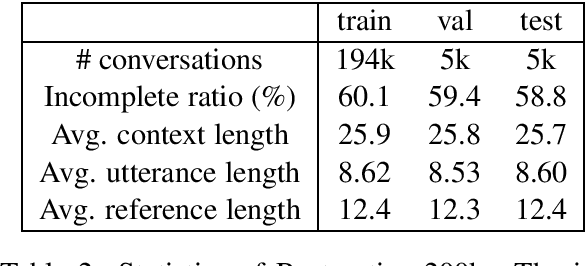
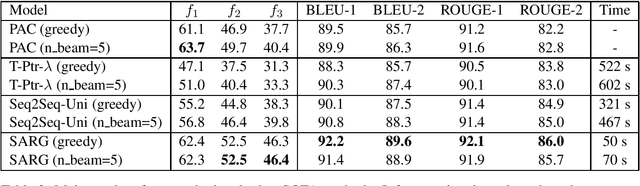
Dialogue systems in the open domain have achieved great success due to large conversation data and the development of deep learning, but multi-turn scenarios are still a challenge because of the frequent coreference and information omission. In this paper, we investigate the incomplete utterance restoration since it has brought general improvement over multi-turn dialogue systems in recent studies. Inspired by the autoregression for generation and the sequence labeling for text editing, we propose a novel semi autoregressive generator (SARG) with the high efficiency and flexibility. Moreover, experiments on Restoration-200k show that our proposed model significantly outperforms the state-of-the-art models with faster inference speed.