 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Native Multimodal Modeling: A Roadmap
May 25, 2026Multimodal modeling represents a vital step from modality-agnostic reasoning toward world modeling. While early approaches predominantly rely on late-fusion that assembles encoders and frozen language backbones with output heads, recent efforts have shifted the paradigm toward native multimodal modeling (NMM) with the intrinsic integration of modalities for superior multimodal performance. Despite its potential, the design space of native architectures remains insufficiently defined. In this paper, we present the community with a formalized roadmap for this transition. Specifically, we formally define the architectural nativity, distinguishing mid-fusion and early-fusion from non-native paradigms. We further organize the existing native models through the lens of input-output duality into three categories: (i) Multi-to-Text for cross-modal comprehension with text-only output; (ii) Multi-to-Target for scenario-oriented generation, e.g., image, audio and video generation, and (iii) Multi-to-Multi for unified modeling with symmetric input-output. We deliver a comprehensive and industrial-grade investigation into the transition toward the definitive NMM framework, where understanding and generation seamlessly coexist within a unified transformer paradigm. We systematically unpack the end-to-end pipeline from industrial perspectives from architectural coordination, massive data curation, to full-stack training recipes, inference & deployment, and the comprehensive evaluation for truly native modeling.
SMASH: Mastering Scalable Whole-Body Skills for Humanoid Ping-Pong with Egocentric Vision
Apr 01, 2026Existing humanoid table tennis systems remain limited by their reliance on external sensing and their inability to achieve agile whole-body coordination for precise task execution. These limitations stem from two core challenges: achieving low-latency and robust onboard egocentric perception under fast robot motion, and obtaining sufficiently diverse task-aligned strike motions for learning precise yet natural whole-body behaviors. In this work, we present \methodname, a modular system for agile humanoid table tennis that unifies scalable whole-body skill learning with onboard egocentric perception, eliminating the need for external cameras during deployment. Our work advances prior humanoid table-tennis systems in three key aspects. First, we achieve agile and precise ball interaction with tightly coordinated whole-body control, rather than relying on decoupled upper- and lower-body behaviors. This enables the system to exhibit diverse strike motions, including explosive whole-body smashes and low crouching shots. Second, by augmenting and diversifying strike motions with a generative model, our framework benefits from scalable motion priors and produces natural, robust striking behaviors across a wide workspace. Third, to the best of our knowledge, we demonstrate the first humanoid table-tennis system capable of consecutive strikes using onboard sensing alone, despite the challenges of low-latency perception, ego-motion-induced instability, and limited field of view. Extensive real-world experiments demonstrate stable and precise ball exchanges under high-speed conditions, validating scalable, perception-driven whole-body skill learning for dynamic humanoid interaction tasks.
Cognitive Mismatch in Multimodal Large Language Models for Discrete Symbol Understanding
Mar 19, 2026While Multimodal Large Language Models (MLLMs) have achieved remarkable success in interpreting natural scenes, their ability to process discrete symbols -- the fundamental building blocks of human cognition -- remains a critical open question. Unlike continuous visual data, symbols such as mathematical formulas, chemical structures, and linguistic characters require precise, deeper interpretation. This paper introduces a comprehensive benchmark to evaluate how top-tier MLLMs navigate these "discrete semantic spaces" across five domains: language, culture, mathematics, physics, and chemistry. Our investigation uncovers a counterintuitive phenomenon: models often fail at basic symbol recognition yet succeed in complex reasoning tasks, suggesting they rely on linguistic probability rather than true visual perception. By exposing this "cognitive mismatch", we highlight a significant gap in current AI capabilities: the struggle to truly perceive and understand the symbolic languages that underpin scientific discovery and abstract thought. This work offers a roadmap for developing more rigorous, human-aligned intelligent systems.
Deep Tabular Research via Continual Experience-Driven Execution
Mar 12, 2026Large language models often struggle with complex long-horizon analytical tasks over unstructured tables, which typically feature hierarchical and bidirectional headers and non-canonical layouts. We formalize this challenge as Deep Tabular Research (DTR), requiring multi-step reasoning over interdependent table regions. To address DTR, we propose a novel agentic framework that treats tabular reasoning as a closed-loop decision-making process. We carefully design a coupled query and table comprehension for path decision making and operational execution. Specifically, (i) DTR first constructs a hierarchical meta graph to capture bidirectional semantics, mapping natural language queries into an operation-level search space; (ii) To navigate this space, we introduce an expectation-aware selection policy that prioritizes high-utility execution paths; (iii) Crucially, historical execution outcomes are synthesized into a siamese structured memory, i.e., parameterized updates and abstracted texts, enabling continual refinement. Extensive experiments on challenging unstructured tabular benchmarks verify the effectiveness and highlight the necessity of separating strategic planning from low-level execution for long-horizon tabular reasoning.
EgoHumanoid: Unlocking In-the-Wild Loco-Manipulation with Robot-Free Egocentric Demonstration
Feb 10, 2026Human demonstrations offer rich environmental diversity and scale naturally, making them an appealing alternative to robot teleoperation. While this paradigm has advanced robot-arm manipulation, its potential for the more challenging, data-hungry problem of humanoid loco-manipulation remains largely unexplored. We present EgoHumanoid, the first framework to co-train a vision-language-action policy using abundant egocentric human demonstrations together with a limited amount of robot data, enabling humanoids to perform loco-manipulation across diverse real-world environments. To bridge the embodiment gap between humans and robots, including discrepancies in physical morphology and viewpoint, we introduce a systematic alignment pipeline spanning from hardware design to data processing. A portable system for scalable human data collection is developed, and we establish practical collection protocols to improve transferability. At the core of our human-to-humanoid alignment pipeline lies two key components. The view alignment reduces visual domain discrepancies caused by camera height and perspective variation. The action alignment maps human motions into a unified, kinematically feasible action space for humanoid control. Extensive real-world experiments demonstrate that incorporating robot-free egocentric data significantly outperforms robot-only baselines by 51\%, particularly in unseen environments. Our analysis further reveals which behaviors transfer effectively and the potential for scaling human data.
TangramPuzzle: Evaluating Multimodal Large Language Models with Compositional Spatial Reasoning
Jan 23, 2026Multimodal Large Language Models (MLLMs) have achieved remarkable progress in visual recognition and semantic understanding. Nevertheless, their ability to perform precise compositional spatial reasoning remains largely unexplored. Existing benchmarks often involve relatively simple tasks and rely on semantic approximations or coarse relative positioning, while their evaluation metrics are typically limited and lack rigorous mathematical formulations. To bridge this gap, we introduce TangramPuzzle, a geometry-grounded benchmark designed to evaluate compositional spatial reasoning through the lens of the classic Tangram game. We propose the Tangram Construction Expression (TCE), a symbolic geometric framework that grounds tangram assemblies in exact, machine-verifiable coordinate specifications, to mitigate the ambiguity of visual approximation. We design two complementary tasks: Outline Prediction, which demands inferring global shapes from local components, and End-to-End Code Generation, which requires solving inverse geometric assembly problems. We conduct extensive evaluation experiments on advanced open-source and proprietary models, revealing an interesting insight: MLLMs tend to prioritize matching the target silhouette while neglecting geometric constraints, leading to distortions or deformations of the pieces.
EvoConfig: Self-Evolving Multi-Agent Systems for Efficient Autonomous Environment Configuration
Jan 23, 2026A reliable executable environment is the foundation for ensuring that large language models solve software engineering tasks. Due to the complex and tedious construction process, large-scale configuration is relatively inefficient. However, most methods always overlook fine-grained analysis of the actions performed by the agent, making it difficult to handle complex errors and resulting in configuration failures. To address this bottleneck, we propose EvoConfig, an efficient environment configuration framework that optimizes multi-agent collaboration to build correct runtime environments. EvoConfig features an expert diagnosis module for fine-grained post-execution analysis, and a self-evolving mechanism that lets expert agents self-feedback and dynamically adjust error-fixing priorities in real time. Empirically, EvoConfig matches the previous state-of-the-art Repo2Run on Repo2Run's 420 repositories, while delivering clear gains on harder cases: on the more challenging Envbench, EvoConfig achieves a 78.1% success rate, outperforming Repo2Run by 7.1%. Beyond end-to-end success, EvoConfig also demonstrates stronger debugging competence, achieving higher accuracy in error identification and producing more effective repair recommendations than existing methods.
Youtu-LLM: Unlocking the Native Agentic Potential for Lightweight Large Language Models
Dec 31, 2025We introduce Youtu-LLM, a lightweight yet powerful language model that harmonizes high computational efficiency with native agentic intelligence. Unlike typical small models that rely on distillation, Youtu-LLM (1.96B) is pre-trained from scratch to systematically cultivate reasoning and planning capabilities. The key technical advancements are as follows: (1) Compact Architecture with Long-Context Support: Built on a dense Multi-Latent Attention (MLA) architecture with a novel STEM-oriented vocabulary, Youtu-LLM supports a 128k context window. This design enables robust long-context reasoning and state tracking within a minimal memory footprint, making it ideal for long-horizon agent and reasoning tasks. (2) Principled "Commonsense-STEM-Agent" Curriculum: We curated a massive corpus of approximately 11T tokens and implemented a multi-stage training strategy. By progressively shifting the pre-training data distribution from general commonsense to complex STEM and agentic tasks, we ensure the model acquires deep cognitive abilities rather than superficial alignment. (3) Scalable Agentic Mid-training: Specifically for the agentic mid-training, we employ diverse data construction schemes to synthesize rich and varied trajectories across math, coding, and tool-use domains. This high-quality data enables the model to internalize planning and reflection behaviors effectively. Extensive evaluations show that Youtu-LLM sets a new state-of-the-art for sub-2B LLMs. On general benchmarks, it achieves competitive performance against larger models, while on agent-specific tasks, it significantly surpasses existing SOTA baselines, demonstrating that lightweight models can possess strong intrinsic agentic capabilities.
SpecRouter: Adaptive Routing for Multi-Level Speculative Decoding in Large Language Models
May 12, 2025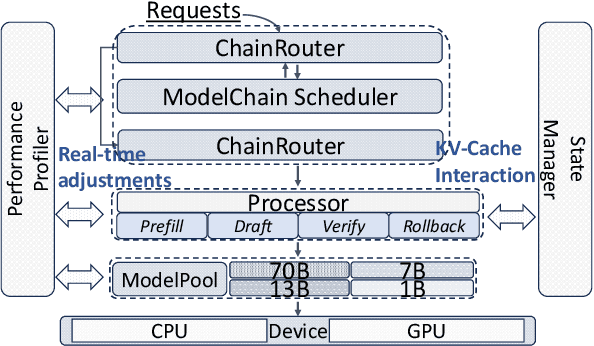
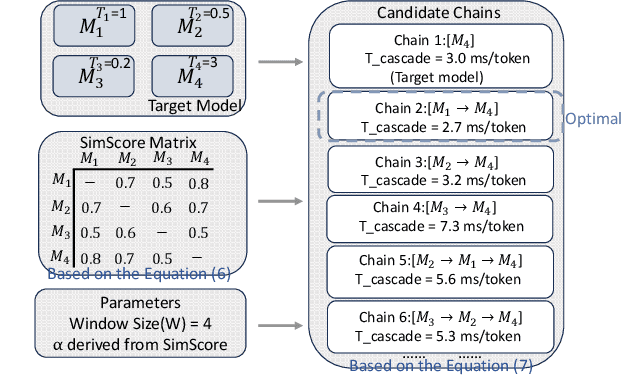
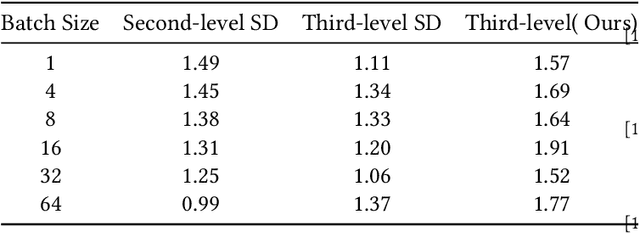
Large Language Models (LLMs) present a critical trade-off between inference quality and computational cost: larger models offer superior capabilities but incur significant latency, while smaller models are faster but less powerful. Existing serving strategies often employ fixed model scales or static two-stage speculative decoding, failing to dynamically adapt to the varying complexities of user requests or fluctuations in system performance. This paper introduces \systemname{}, a novel framework that reimagines LLM inference as an adaptive routing problem solved through multi-level speculative decoding. \systemname{} dynamically constructs and optimizes inference "paths" (chains of models) based on real-time feedback, addressing the limitations of static approaches. Our contributions are threefold: (1) An \textbf{adaptive model chain scheduling} mechanism that leverages performance profiling (execution times) and predictive similarity metrics (derived from token distribution divergence) to continuously select the optimal sequence of draft and verifier models, minimizing predicted latency per generated token. (2) A \textbf{multi-level collaborative verification} framework where intermediate models within the selected chain can validate speculative tokens, reducing the verification burden on the final, most powerful target model. (3) A \textbf{synchronized state management} system providing efficient, consistent KV cache handling across heterogeneous models in the chain, including precise, low-overhead rollbacks tailored for asynchronous batch processing inherent in multi-level speculation. Preliminary experiments demonstrate the validity of our method.
From Token to Line: Enhancing Code Generation with a Long-Term Perspective
Apr 10, 2025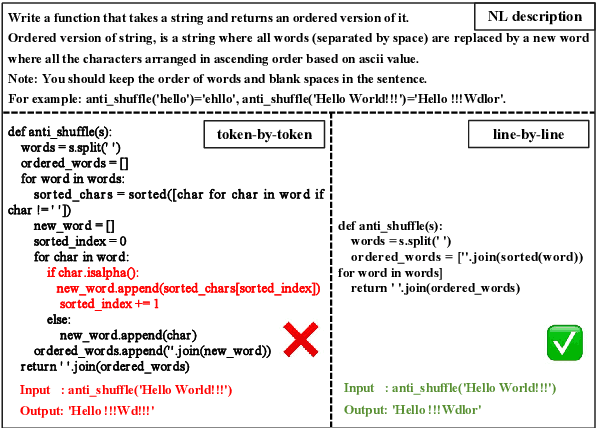
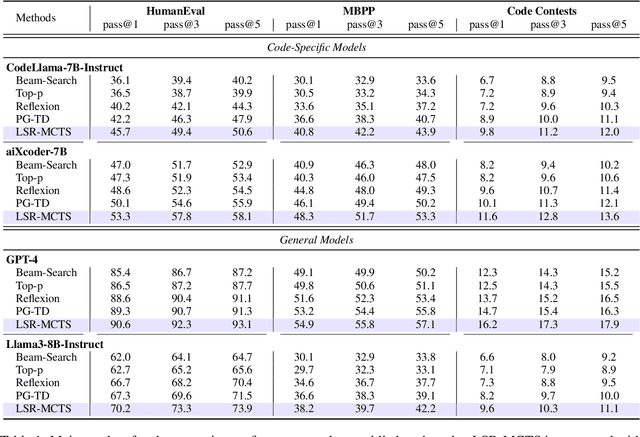
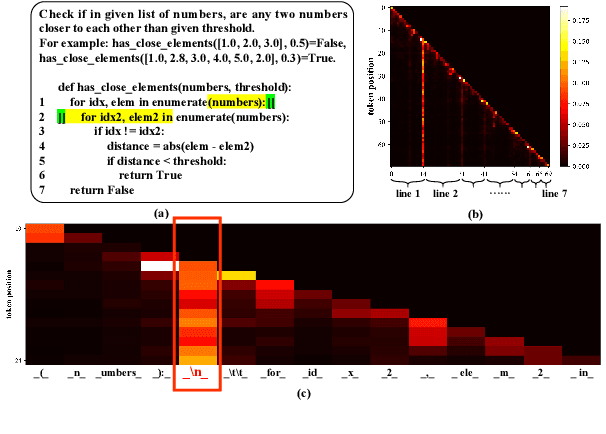
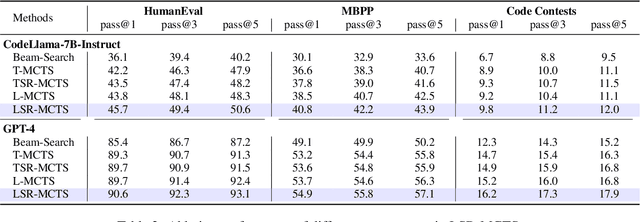
The emergence of large language models (LLMs) has significantly promoted the development of code generation task, sparking a surge in pertinent literature. Current research is hindered by redundant generation results and a tendency to overfit local patterns in the short term. Although existing studies attempt to alleviate the issue by adopting a multi-token prediction strategy, there remains limited focus on choosing the appropriate processing length for generations. By analyzing the attention between tokens during the generation process of LLMs, it can be observed that the high spikes of the attention scores typically appear at the end of lines. This insight suggests that it is reasonable to treat each line of code as a fundamental processing unit and generate them sequentially. Inspired by this, we propose the \textbf{LSR-MCTS} algorithm, which leverages MCTS to determine the code line-by-line and select the optimal path. Further, we integrate a self-refine mechanism at each node to enhance diversity and generate higher-quality programs through error correction. Extensive experiments and comprehensive analyses on three public coding benchmarks demonstrate that our method outperforms the state-of-the-art performance approaches.