 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLandscape-aware Automated Algorithm Design: An Efficient Framework for Real-world Optimization
Feb 04, 2026The advent of Large Language Models (LLMs) has opened new frontiers in automated algorithm design, giving rise to numerous powerful methods. However, these approaches retain critical limitations: they require extensive evaluation of the target problem to guide the search process, making them impractical for real-world optimization tasks, where each evaluation consumes substantial computational resources. This research proposes an innovative and efficient framework that decouples algorithm discovery from high-cost evaluation. Our core innovation lies in combining a Genetic Programming (GP) function generator with an LLM-driven evolutionary algorithm designer. The evolutionary direction of the GP-based function generator is guided by the similarity between the landscape characteristics of generated proxy functions and those of real-world problems, ensuring that algorithms discovered via proxy functions exhibit comparable performance on real-world problems. Our method enables deep exploration of the algorithmic space before final validation while avoiding costly real-world evaluations. We validated the framework's efficacy across multiple real-world problems, demonstrating its ability to discover high-performance algorithms while substantially reducing expensive evaluations. This approach shows a path to apply LLM-based automated algorithm design to computationally intensive real-world optimization challenges.
Out-of-Distribution Generalization for Neural Physics Solvers
Jan 27, 2026Neural physics solvers are increasingly used in scientific discovery, given their potential for rapid in silico insights into physical, materials, or biological systems and their long-time evolution. However, poor generalization beyond their training support limits exploration of novel designs and long-time horizon predictions. We introduce NOVA, a route to generalizable neural physics solvers that can provide rapid, accurate solutions to scenarios even under distributional shifts in partial differential equation parameters, geometries and initial conditions. By learning physics-aligned representations from an initial sparse set of scenarios, NOVA consistently achieves 1-2 orders of magnitude lower out-of-distribution errors than data-driven baselines across complex, nonlinear problems including heat transfer, diffusion-reaction and fluid flow. We further showcase NOVA's dual impact on stabilizing long-time dynamical rollouts and improving generative design through application to the simulation of nonlinear Turing systems and fluidic chip optimization. Unlike neural physics solvers that are constrained to retrieval and/or emulation within an a priori space, NOVA enables reliable extrapolation beyond known regimes, a key capability given the need for exploration of novel hypothesis spaces in scientific discovery
Code Copycat Conundrum: Demystifying Repetition in LLM-based Code Generation
Apr 17, 2025Despite recent advances in Large Language Models (LLMs) for code generation, the quality of LLM-generated code still faces significant challenges. One significant issue is code repetition, which refers to the model's tendency to generate structurally redundant code, resulting in inefficiencies and reduced readability. To address this, we conduct the first empirical study to investigate the prevalence and nature of repetition across 19 state-of-the-art code LLMs using three widely-used benchmarks. Our study includes both quantitative and qualitative analyses, revealing that repetition is pervasive and manifests at various granularities and extents, including character, statement, and block levels. We further summarize a taxonomy of 20 repetition patterns. Building on our findings, we propose DeRep, a rule-based technique designed to detect and mitigate repetition in generated code. We evaluate DeRep using both open-source benchmarks and in an industrial setting. Our results demonstrate that DeRep significantly outperforms baselines in reducing repetition (with an average improvements of 91.3%, 93.5%, and 79.9% in rep-3, rep-line, and sim-line metrics) and enhancing code quality (with a Pass@1 increase of 208.3% over greedy search). Furthermore, integrating DeRep improves the performance of existing repetition mitigation methods, with Pass@1 improvements ranging from 53.7% to 215.7%.
From Token to Line: Enhancing Code Generation with a Long-Term Perspective
Apr 10, 2025
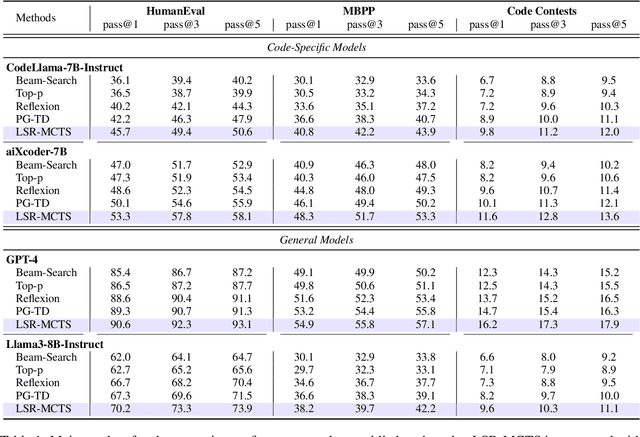
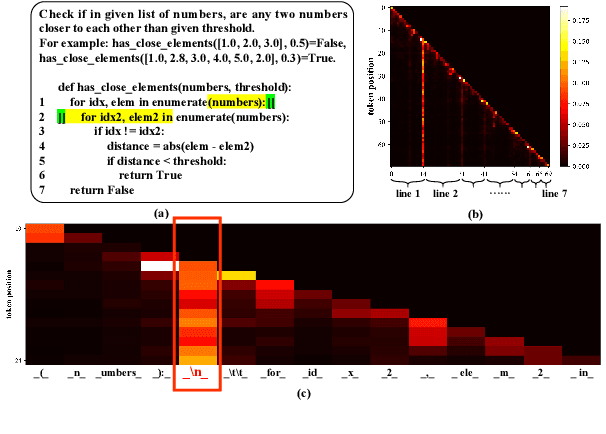
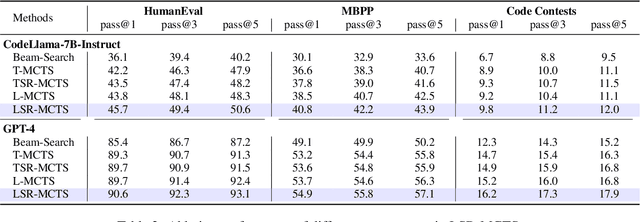
The emergence of large language models (LLMs) has significantly promoted the development of code generation task, sparking a surge in pertinent literature. Current research is hindered by redundant generation results and a tendency to overfit local patterns in the short term. Although existing studies attempt to alleviate the issue by adopting a multi-token prediction strategy, there remains limited focus on choosing the appropriate processing length for generations. By analyzing the attention between tokens during the generation process of LLMs, it can be observed that the high spikes of the attention scores typically appear at the end of lines. This insight suggests that it is reasonable to treat each line of code as a fundamental processing unit and generate them sequentially. Inspired by this, we propose the \textbf{LSR-MCTS} algorithm, which leverages MCTS to determine the code line-by-line and select the optimal path. Further, we integrate a self-refine mechanism at each node to enhance diversity and generate higher-quality programs through error correction. Extensive experiments and comprehensive analyses on three public coding benchmarks demonstrate that our method outperforms the state-of-the-art performance approaches.
Revisiting Classification Taxonomy for Grammatical Errors
Feb 18, 2025Grammatical error classification plays a crucial role in language learning systems, but existing classification taxonomies often lack rigorous validation, leading to inconsistencies and unreliable feedback. In this paper, we revisit previous classification taxonomies for grammatical errors by introducing a systematic and qualitative evaluation framework. Our approach examines four aspects of a taxonomy, i.e., exclusivity, coverage, balance, and usability. Then, we construct a high-quality grammatical error classification dataset annotated with multiple classification taxonomies and evaluate them grounding on our proposed evaluation framework. Our experiments reveal the drawbacks of existing taxonomies. Our contributions aim to improve the precision and effectiveness of error analysis, providing more understandable and actionable feedback for language learners.
Deep Code Search with Naming-Agnostic Contrastive Multi-View Learning
Aug 18, 2024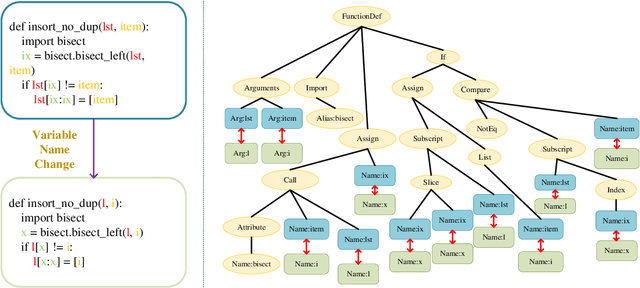
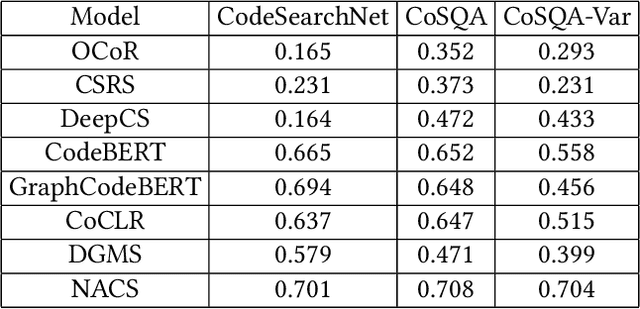
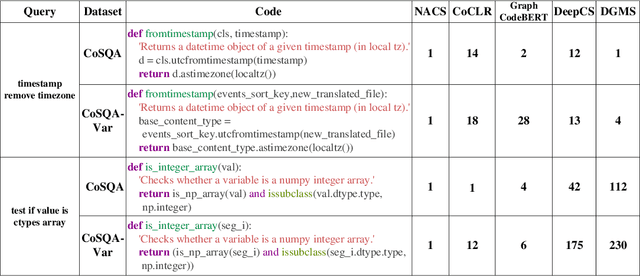

Software development is a repetitive task, as developers usually reuse or get inspiration from existing implementations. Code search, which refers to the retrieval of relevant code snippets from a codebase according to the developer's intent that has been expressed as a query, has become increasingly important in the software development process. Due to the success of deep learning in various applications, a great number of deep learning based code search approaches have sprung up and achieved promising results. However, developers may not follow the same naming conventions and the same variable may have different variable names in different implementations, bringing a challenge to deep learning based code search methods that rely on explicit variable correspondences to understand source code. To overcome this challenge, we propose a naming-agnostic code search method (NACS) based on contrastive multi-view code representation learning. NACS strips information bound to variable names from Abstract Syntax Tree (AST), the representation of the abstract syntactic structure of source code, and focuses on capturing intrinsic properties solely from AST structures. We use semantic-level and syntax-level augmentation techniques to prepare realistically rational data and adopt contrastive learning to design a graph-view modeling component in NACS to enhance the understanding of code snippets. We further model ASTs in a path view to strengthen the graph-view modeling component through multi-view learning. Extensive experiments show that NACS provides superior code search performance compared to baselines and NACS can be adapted to help existing code search methods overcome the impact of different naming conventions.
ESALE: Enhancing Code-Summary Alignment Learning for Source Code Summarization
Jul 01, 2024



(Source) code summarization aims to automatically generate succinct natural language summaries for given code snippets. Such summaries play a significant role in promoting developers to understand and maintain code. Inspired by neural machine translation, deep learning-based code summarization techniques widely adopt an encoder-decoder framework, where the encoder transforms given code snippets into context vectors, and the decoder decodes context vectors into summaries. Recently, large-scale pre-trained models for source code are equipped with encoders capable of producing general context vectors and have achieved substantial improvements on code summarization. However, although they are usually trained mainly on code-focused tasks and can capture general code features, they still fall short in capturing specific features that need to be summarized. This paper proposes a novel approach to improve code summarization based on summary-focused tasks. Specifically, we exploit a multi-task learning paradigm to train the encoder on three summary-focused tasks to enhance its ability to learn code-summary alignment, including unidirectional language modeling (ULM), masked language modeling (MLM), and action word prediction (AWP). Unlike pre-trained models that mainly predict masked tokens in code snippets, we design ULM and MLM to predict masked words in summaries. Intuitively, predicting words based on given code snippets would help learn the code-summary alignment. Additionally, we introduce the domain-specific task AWP to enhance the ability of the encoder to learn the alignment between action words and code snippets. The extensive experiments on four datasets demonstrate that our approach, called ESALE significantly outperforms baselines in all three widely used metrics, including BLEU, METEOR, and ROUGE-L.
EXCGEC: A Benchmark of Edit-wise Explainable Chinese Grammatical Error Correction
Jul 01, 2024



Existing studies explore the explainability of Grammatical Error Correction (GEC) in a limited scenario, where they ignore the interaction between corrections and explanations. To bridge the gap, this paper introduces the task of EXplainable GEC (EXGEC), which focuses on the integral role of both correction and explanation tasks. To facilitate the task, we propose EXCGEC, a tailored benchmark for Chinese EXGEC consisting of 8,216 explanation-augmented samples featuring the design of hybrid edit-wise explanations. We benchmark several series of LLMs in multiple settings, covering post-explaining and pre-explaining. To promote the development of the task, we introduce a comprehensive suite of automatic metrics and conduct human evaluation experiments to demonstrate the human consistency of the automatic metrics for free-text explanations. All the codes and data will be released after the review.
Code Search Debiasing:Improve Search Results beyond Overall Ranking Performance
Nov 25, 2023Code search engine is an essential tool in software development. Many code search methods have sprung up, focusing on the overall ranking performance of code search. In this paper, we study code search from another perspective by analyzing the bias of code search models. Biased code search engines provide poor user experience, even though they show promising overall performance. Due to different development conventions (e.g., prefer long queries or abbreviations), some programmers will find the engine useful, while others may find it hard to get desirable search results. To mitigate biases, we develop a general debiasing framework that employs reranking to calibrate search results. It can be easily plugged into existing engines and handle new code search biases discovered in the future. Experiments show that our framework can effectively reduce biases. Meanwhile, the overall ranking performance of code search gets improved after debiasing.