 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvances and Frontiers of LLM-based Issue Resolution in Software Engineering: A Comprehensive Survey
Jan 15, 2026Issue resolution, a complex Software Engineering (SWE) task integral to real-world development, has emerged as a compelling challenge for artificial intelligence. The establishment of benchmarks like SWE-bench revealed this task as profoundly difficult for large language models, thereby significantly accelerating the evolution of autonomous coding agents. This paper presents a systematic survey of this emerging domain. We begin by examining data construction pipelines, covering automated collection and synthesis approaches. We then provide a comprehensive analysis of methodologies, spanning training-free frameworks with their modular components to training-based techniques, including supervised fine-tuning and reinforcement learning. Subsequently, we discuss critical analyses of data quality and agent behavior, alongside practical applications. Finally, we identify key challenges and outline promising directions for future research. An open-source repository is maintained at https://github.com/DeepSoftwareAnalytics/Awesome-Issue-Resolution to serve as a dynamic resource in this field.
ShortCoder: Knowledge-Augmented Syntax Optimization for Token-Efficient Code Generation
Jan 14, 2026Code generation tasks aim to automate the conversion of user requirements into executable code, significantly reducing manual development efforts and enhancing software productivity. The emergence of large language models (LLMs) has significantly advanced code generation, though their efficiency is still impacted by certain inherent architectural constraints. Each token generation necessitates a complete inference pass, requiring persistent retention of contextual information in memory and escalating resource consumption. While existing research prioritizes inference-phase optimizations such as prompt compression and model quantization, the generation phase remains underexplored. To tackle these challenges, we propose a knowledge-infused framework named ShortCoder, which optimizes code generation efficiency while preserving semantic equivalence and readability. In particular, we introduce: (1) ten syntax-level simplification rules for Python, derived from AST-preserving transformations, achieving 18.1% token reduction without functional compromise; (2) a hybrid data synthesis pipeline integrating rule-based rewriting with LLM-guided refinement, producing ShorterCodeBench, a corpus of validated tuples of original code and simplified code with semantic consistency; (3) a fine-tuning strategy that injects conciseness awareness into the base LLMs. Extensive experimental results demonstrate that ShortCoder consistently outperforms state-of-the-art methods on HumanEval, achieving an improvement of 18.1%-37.8% in generation efficiency over previous methods while ensuring the performance of code generation.
Code Copycat Conundrum: Demystifying Repetition in LLM-based Code Generation
Apr 17, 2025Despite recent advances in Large Language Models (LLMs) for code generation, the quality of LLM-generated code still faces significant challenges. One significant issue is code repetition, which refers to the model's tendency to generate structurally redundant code, resulting in inefficiencies and reduced readability. To address this, we conduct the first empirical study to investigate the prevalence and nature of repetition across 19 state-of-the-art code LLMs using three widely-used benchmarks. Our study includes both quantitative and qualitative analyses, revealing that repetition is pervasive and manifests at various granularities and extents, including character, statement, and block levels. We further summarize a taxonomy of 20 repetition patterns. Building on our findings, we propose DeRep, a rule-based technique designed to detect and mitigate repetition in generated code. We evaluate DeRep using both open-source benchmarks and in an industrial setting. Our results demonstrate that DeRep significantly outperforms baselines in reducing repetition (with an average improvements of 91.3%, 93.5%, and 79.9% in rep-3, rep-line, and sim-line metrics) and enhancing code quality (with a Pass@1 increase of 208.3% over greedy search). Furthermore, integrating DeRep improves the performance of existing repetition mitigation methods, with Pass@1 improvements ranging from 53.7% to 215.7%.
How Should I Build A Benchmark?
Jan 18, 2025Various benchmarks have been proposed to assess the performance of large language models (LLMs) in different coding scenarios. We refer to them as code-related benchmarks. However, there are no systematic guidelines by which such a benchmark should be developed to ensure its quality, reliability, and reproducibility. We propose How2Bench, which is comprised of a 55- 55-criteria checklist as a set of guidelines to govern the development of code-related benchmarks comprehensively. Using HOW2BENCH, we profiled 274 benchmarks released within the past decade and found concerning issues. Nearly 70% of the benchmarks did not take measures for data quality assurance; over 10% did not even open source or only partially open source. Many highly cited benchmarks have loopholes, including duplicated samples, incorrect reference codes/tests/prompts, and unremoved sensitive/confidential information. Finally, we conducted a human study involving 49 participants, which revealed significant gaps in awareness of the importance of data quality, reproducibility, and transparency.
Beyond Functional Correctness: Investigating Coding Style Inconsistencies in Large Language Models
Jun 29, 2024Large language models (LLMs) have brought a paradigm shift to the field of code generation, offering the potential to enhance the software development process. However, previous research mainly focuses on the accuracy of code generation, while coding style differences between LLMs and human developers remain under-explored. In this paper, we empirically analyze the differences in coding style between the code generated by mainstream Code LLMs and the code written by human developers, and summarize coding style inconsistency taxonomy. Specifically, we first summarize the types of coding style inconsistencies by manually analyzing a large number of generation results. We then compare the code generated by Code LLMs with the code written by human programmers in terms of readability, conciseness, and robustness. The results reveal that LLMs and developers have different coding styles. Additionally, we study the possible causes of these inconsistencies and provide some solutions to alleviate the problem.
Vul-RAG: Enhancing LLM-based Vulnerability Detection via Knowledge-level RAG
Jun 17, 2024

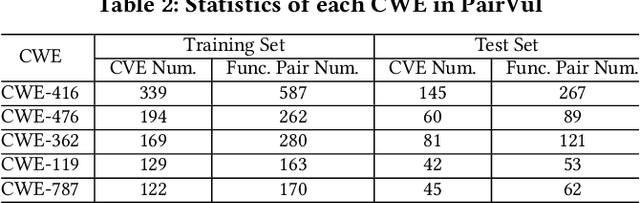
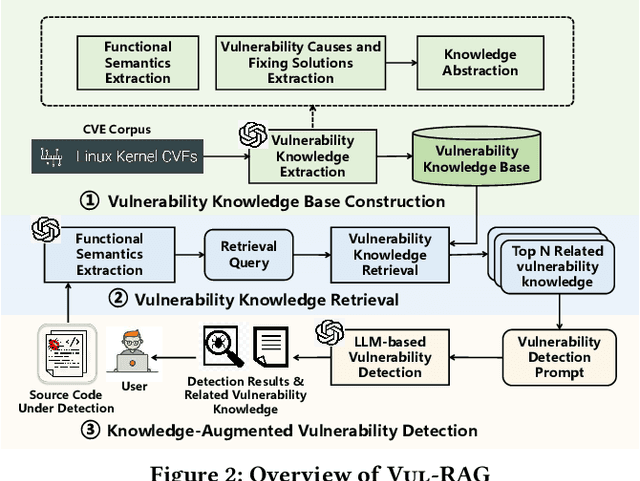
Vulnerability detection is essential for software quality assurance. In recent years, deep learning models (especially large language models) have shown promise in vulnerability detection. In this work, we propose a novel LLM-based vulnerability detection technique Vul-RAG, which leverages knowledge-level retrieval-augmented generation (RAG) framework to detect vulnerability for the given code in three phases. First, Vul-RAG constructs a vulnerability knowledge base by extracting multi-dimension knowledge via LLMs from existing CVE instances; second, for a given code snippet, Vul-RAG} retrieves the relevant vulnerability knowledge from the constructed knowledge base based on functional semantics; third, Vul-RAG leverages LLMs to check the vulnerability of the given code snippet by reasoning the presence of vulnerability causes and fixing solutions of the retrieved vulnerability knowledge. Our evaluation of Vul-RAG on our constructed benchmark PairVul shows that Vul-RAG substantially outperforms all baselines by 12.96\%/110\% relative improvement in accuracy/pairwise-accuracy. In addition, our user study shows that the vulnerability knowledge generated by Vul-RAG can serve as high-quality explanations which can improve the manual detection accuracy from 0.60 to 0.77.
Resolving Crash Bugs via Large Language Models: An Empirical Study
Dec 16, 2023Crash bugs cause unexpected program behaviors or even termination, requiring high-priority resolution. However, manually resolving crash bugs is challenging and labor-intensive, and researchers have proposed various techniques for their automated localization and repair. ChatGPT, a recent large language model (LLM), has garnered significant attention due to its exceptional performance across various domains. This work performs the first investigation into ChatGPT's capability in resolve real-world crash bugs, focusing on its effectiveness in both localizing and repairing code-related and environment-related crash bugs. Specifically, we initially assess ChatGPT's fundamental ability to resolve crash bugs with basic prompts in a single iteration. We observe that ChatGPT performs better at resolving code-related crash bugs compared to environment-related ones, and its primary challenge in resolution lies in inaccurate localization. Additionally, we explore ChatGPT's potential with various advanced prompts. Furthermore, by stimulating ChatGPT's self-planning, it methodically investigates each potential crash-causing environmental factor through proactive inquiry, ultimately identifying the root cause of the crash. Based on our findings, we propose IntDiagSolver, an interaction methodology designed to facilitate precise crash bug resolution through continuous interaction with LLMs. Evaluating IntDiagSolver on multiple LLMs reveals consistent enhancement in the accuracy of crash bug resolution, including ChatGPT, Claude, and CodeLlama.
ClassEval: A Manually-Crafted Benchmark for Evaluating LLMs on Class-level Code Generation
Aug 14, 2023



In this work, we make the first attempt to evaluate LLMs in a more challenging code generation scenario, i.e. class-level code generation. We first manually construct the first class-level code generation benchmark ClassEval of 100 class-level Python code generation tasks with approximately 500 person-hours. Based on it, we then perform the first study of 11 state-of-the-art LLMs on class-level code generation. Based on our results, we have the following main findings. First, we find that all existing LLMs show much worse performance on class-level code generation compared to on standalone method-level code generation benchmarks like HumanEval; and the method-level coding ability cannot equivalently reflect the class-level coding ability among LLMs. Second, we find that GPT-4 and GPT-3.5 still exhibit dominate superior than other LLMs on class-level code generation, and the second-tier models includes Instruct-Starcoder, Instruct-Codegen, and Wizardcoder with very similar performance. Third, we find that generating the entire class all at once (i.e. holistic generation strategy) is the best generation strategy only for GPT-4 and GPT-3.5, while method-by-method generation (i.e. incremental and compositional) is better strategies for the other models with limited ability of understanding long instructions and utilizing the middle information. Lastly, we find the limited model ability of generating method-dependent code and discuss the frequent error types in generated classes. Our benchmark is available at https://github.com/FudanSELab/ClassEval.
Evaluating Instruction-Tuned Large Language Models on Code Comprehension and Generation
Aug 02, 2023



In this work, we evaluate 10 open-source instructed LLMs on four representative code comprehension and generation tasks. We have the following main findings. First, for the zero-shot setting, instructed LLMs are very competitive on code comprehension and generation tasks and sometimes even better than small SOTA models specifically fine-tuned on each downstream task. We also find that larger instructed LLMs are not always better on code-related tasks. Second, for the few-shot setting, we find that adding demonstration examples substantially helps instructed LLMs perform better on most code comprehension and generation tasks; however, the examples would sometimes induce unstable or even worse performance. Furthermore, we find widely-used BM25-based shot selection strategy significantly outperforms the basic random selection or fixed selection only on generation problems. Third, for the fine-tuning setting, we find that fine-tuning could further improve the model performance on downstream code comprehension and generation tasks compared to the zero-shot/one-shot performance. In addition, after being fine-tuned on the same downstream task dataset, instructed LLMs outperform both the small SOTA models and similar-scaled LLMs without instruction tuning. Based on our findings, we further present practical implications on model and usage recommendation, performance and cost trade-offs, and future direction.