 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnlocking Proactivity in Task-Oriented Dialogue
May 21, 2026Proactive task-oriented dialogue (TOD), such as outbound sales, demands a persuasive agent that actively probes the user's concerns and steers the conversation toward acceptance within a bounded number of turns. Yet post-trained LLMs are inherently conservative, and reward-shaping RL (e.g., GRPO) struggles since it only re-weights what an already passive policy samples. We show that conditioning on the user's latent concerns unlocks proactive capability that no amount of sampling can undermine, establishing these concerns as a pivotal training-time signal. To operationalize this finding, we build the \textbf{Cognitive User Simulator}, which models each user as a stratified persona comprising observable external traits and hidden internal concerns. The simulator produces faithful and diverse interactions, while emitting per-turn state dynamics that track persuasion progress. We then introduce \textbf{Simulator-Induced Asymmetric-View Policy Optimization}, which converts the modeled concerns and the simulation state transition into complementary training objectives: (1) \emph{Asymmetric On-Policy Self-Distillation} that transfers concern-aware behavior from a privileged view of the same policy into its deployable, conversation-only view; and (2) \emph{State-Transition Policy Refinement} ...
Tailoring Teaching to Aptitude: Direction-Adaptive Self-Distillation for LLM Reasoning
May 21, 2026On-policy self-distillation (OPSD) is an emerging LLM post-training paradigm in which the model serves as its own teacher: conditioned on privileged information such as a reference trace or hint, the same policy provides dense token-level supervision on its own rollouts. However, recent studies show that OPSD degrades complex reasoning by suppressing predictive uncertainty, which supports exploration and hypothesis revision. Our token-level analysis shows that this failure arises from applying a uniform direction of teacher supervision across tokens with different uncertainty levels: conformity to the privileged self-teacher suppresses exploration at high entropy, while deviation from the teacher degrades step accuracy at low entropy. Accordingly, we propose \textbf{Direction-Adaptive Self-Distillation} (\textbf{DASD}), which reframes privileged self-distillation from uniform teacher imitation into entropy-routed directional supervision: high-entropy tokens are pushed away from the privileged teacher to preserve exploration, while low-entropy tokens are pulled toward the teacher to stabilize step-level execution. Across six mathematical reasoning benchmarks, DASD achieves the best macro Avg@16 over strong RLVR and self-distillation baselines. Pass@$k$, reasoning-health, and generalization analyses show that these average gains come from preserving exploration without sacrificing step-level execution.
SWE-Chain: Benchmarking Coding Agents on Chained Release-Level Package Upgrades
May 14, 2026Coding agents powered by large language models are increasingly expected to perform realistic software maintenance tasks beyond isolated issue resolution. Existing benchmarks have shifted toward realistic software evolution, but they rarely capture continuous maintenance at the granularity of package releases, where changes are bundled, shipped, and inherited by subsequent versions. We present SWE-Chain, a benchmark for evaluating agents on chained release-level package upgrades, where each transition builds on the agent's prior codebase. To produce upgrade specifications, we design a divide-and-conquer synthesis pipeline that aligns release notes with code diffs for each version transition, ensuring the requirements are grounded in actual code changes, informative to agents, and feasible to implement. SWE-Chain contains 12 upgrade chains across 9 real Python packages, with 155 version transitions and 1,660 grounded upgrade requirements. Across nine frontier agent-model configurations, agents achieve an average of 44.8% resolving, 65.4% precision, and 50.2% F1 under the Build+Fix regime, with Claude-Opus-4.7 (Claude Code) leading at 60.8% resolving, 80.6% precision, and 68.5% F1. These results show that SWE-Chain is both feasible and discriminative, and reveal that current agents still struggle to make correct upgrades across chained package releases without breaking existing functionality.
SAGE: A Service Agent Graph-guided Evaluation Benchmark
Apr 10, 2026The development of Large Language Models (LLMs) has catalyzed automation in customer service, yet benchmarking their performance remains challenging. Existing benchmarks predominantly rely on static paradigms and single-dimensional metrics, failing to account for diverse user behaviors or the strict adherence to structured Standard Operating Procedures (SOPs) required in real-world deployments. To bridge this gap, we propose SAGE (Service Agent Graph-guided Evaluation), a universal multi-agent benchmark for automated, dual-axis assessment. SAGE formalizes unstructured SOPs into Dynamic Dialogue Graphs, enabling precise verification of logical compliance and comprehensive path coverage. We introduce an Adversarial Intent Taxonomy and a modular Extension Mechanism, enabling low-cost deployment across domains and facilitating automated dialogue data synthesis. Evaluation is conducted via a framework where Judge Agents and a Rule Engine analyze interactions between User and Service Agents to generate deterministic ground truth. Extensive experiments on 27 LLMs across 6 industrial scenarios reveal a significant ``Execution Gap'' where models accurately classify intents but fail to derive correct subsequent actions. We also observe ``Empathy Resilience'', a phenomenon where models maintain polite conversational facades despite underlying logical failures under high adversarial intensity. Code and resources are available at https://anonymous.4open.science/r/SAGE-Bench-4CD3/.
WARBENCH: A Comprehensive Benchmark for Evaluating LLMs in Military Decision-Making
Mar 22, 2026Large Language Models are increasingly being considered for deployment in safety-critical military applications. However, current benchmarks suffer from structural blindspots that systematically overestimate model capabilities in real-world tactical scenarios. Existing frameworks typically ignore strict legal constraints based on International Humanitarian Law (IHL), omit edge computing limitations, lack robustness testing for fog of war, and inadequately evaluate explicit reasoning. To address these vulnerabilities, we present WARBENCH, a comprehensive evaluation framework establishing a foundational tactical baseline alongside four distinct stress testing dimensions. Through a large scale empirical evaluation of nine leading models on 136 high-fidelity historical scenarios, we reveal severe structural flaws. First, baseline tactical reasoning systematically collapses under complex terrain and high force asymmetry. Second, while state of the art closed source models maintain functional compliance, edge-optimized small models expose extreme operational risks with legal violation rates approaching 70 percent. Furthermore, models experience catastrophic performance degradation under 4-bit quantization and systematic information loss. Conversely, explicit reasoning mechanisms serve as highly effective structural safeguards against inadvertent violations. Ultimately, these findings demonstrate that current models remain fundamentally unready for autonomous deployment in high stakes tactical environments.
Reinforcing Real-world Service Agents: Balancing Utility and Cost in Task-oriented Dialogue
Feb 26, 2026The rapid evolution of Large Language Models (LLMs) has accelerated the transition from conversational chatbots to general agents. However, effectively balancing empathetic communication with budget-aware decision-making remains an open challenge. Since existing methods fail to capture these complex strategic trade-offs, we propose InteractCS-RL, a framework that reframes task-oriented dialogue as a multi-granularity reinforcement learning process. Specifically, we first establish a User-centric Interaction Framework to provide a high-fidelity training gym, enabling agents to dynamically explore diverse strategies with persona-driven users. Then, we introduce Cost-aware Multi-turn Policy Optimization (CMPO) with a hybrid advantage estimation strategy. By integrating generative process credits and employing a PID-Lagrangian cost controller, CMPO effectively guides the policy to explore Pareto boundary between user reward and global cost constraints. Extensive experiments on customized real business scenarios demonstrate that InteractCS-RL significantly outperform other baselines across three evaluation dimensions. Further evaluation on tool-agent-user interaction benchmarks verify InteractCS-RL robustness across diverse domains.
SEAD: Self-Evolving Agent for Multi-Turn Service Dialogue
Feb 03, 2026Large Language Models have demonstrated remarkable capabilities in open-domain dialogues. However, current methods exhibit suboptimal performance in service dialogues, as they rely on noisy, low-quality human conversation data. This limitation arises from data scarcity and the difficulty of simulating authentic, goal-oriented user behaviors. To address these issues, we propose SEAD (Self-Evolving Agent for Service Dialogue), a framework that enables agents to learn effective strategies without large-scale human annotations. SEAD decouples user modeling into two components: a Profile Controller that generates diverse user states to manage training curriculum, and a User Role-play Model that focuses on realistic role-playing. This design ensures the environment provides adaptive training scenarios rather than acting as an unfair adversary. Experiments demonstrate that SEAD significantly outperforms Open-source Foundation Models and Closed-source Commercial Models, improving task completion rate by 17.6% and dialogue efficiency by 11.1%. Code is available at: https://github.com/Da1yuqin/SEAD.
REPAIR: Robust Editing via Progressive Adaptive Intervention and Reintegration
Oct 02, 2025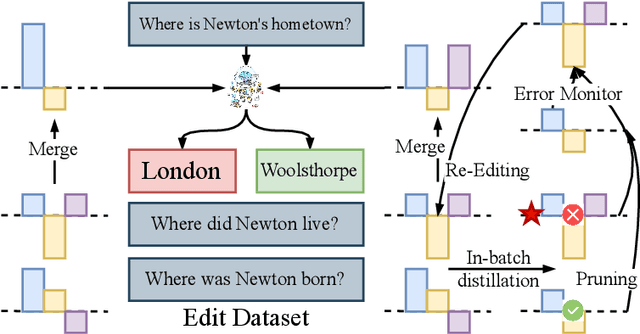
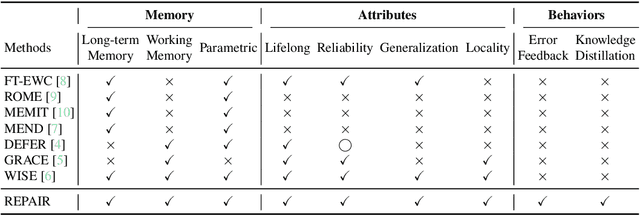
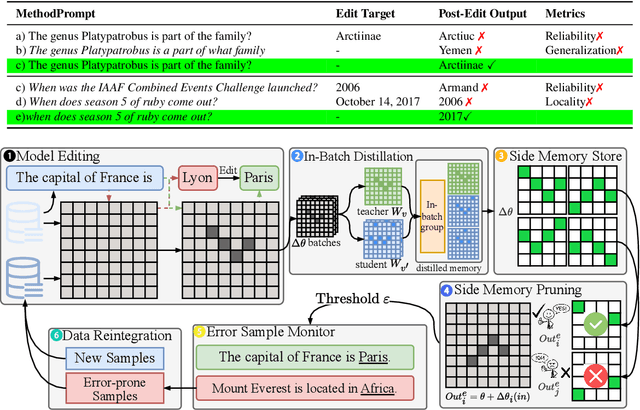
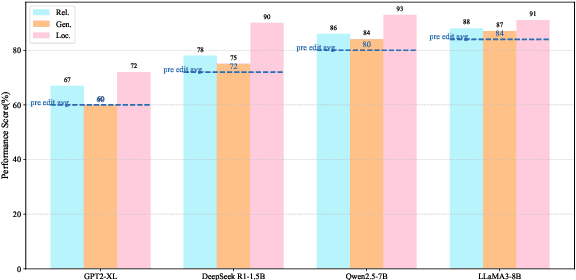
Post-training for large language models (LLMs) is constrained by the high cost of acquiring new knowledge or correcting errors and by the unintended side effects that frequently arise from retraining. To address these issues, we introduce REPAIR (Robust Editing via Progressive Adaptive Intervention and Reintegration), a lifelong editing framework designed to support precise and low-cost model updates while preserving non-target knowledge. REPAIR mitigates the instability and conflicts of large-scale sequential edits through a closed-loop feedback mechanism coupled with dynamic memory management. Furthermore, by incorporating frequent knowledge fusion and enforcing strong locality guards, REPAIR effectively addresses the shortcomings of traditional distribution-agnostic approaches that often overlook unintended ripple effects. Our experiments demonstrate that REPAIR boosts editing accuracy by 10%-30% across multiple model families and significantly reduces knowledge forgetting. This work introduces a robust framework for developing reliable, scalable, and continually evolving LLMs.
UMoE: Unifying Attention and FFN with Shared Experts
May 12, 2025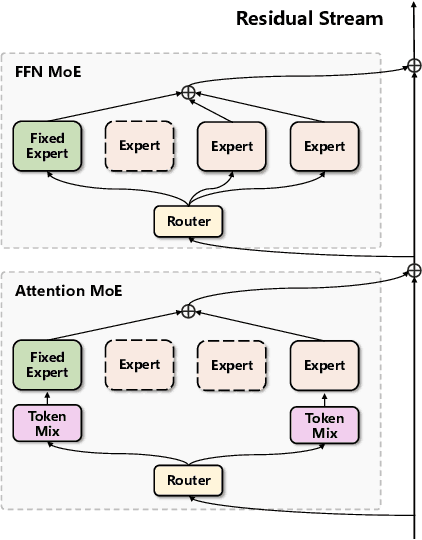
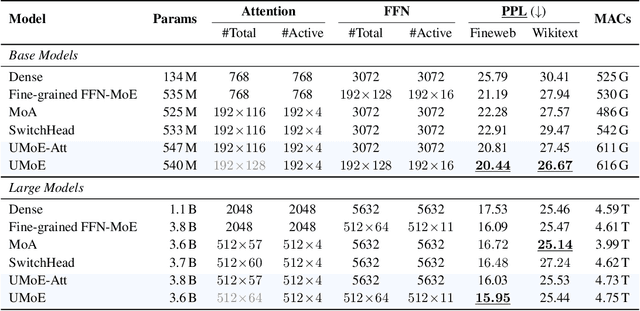
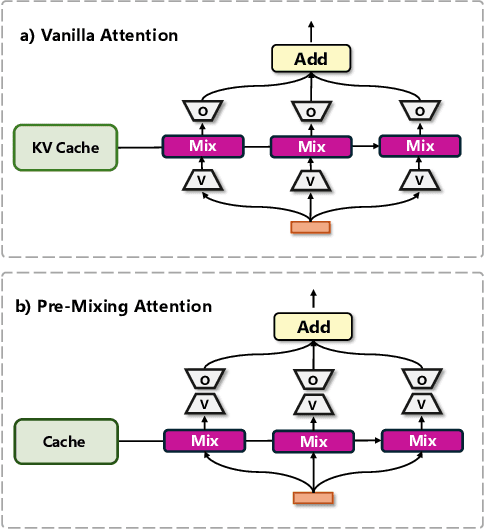

Sparse Mixture of Experts (MoE) architectures have emerged as a promising approach for scaling Transformer models. While initial works primarily incorporated MoE into feed-forward network (FFN) layers, recent studies have explored extending the MoE paradigm to attention layers to enhance model performance. However, existing attention-based MoE layers require specialized implementations and demonstrate suboptimal performance compared to their FFN-based counterparts. In this paper, we aim to unify the MoE designs in attention and FFN layers by introducing a novel reformulation of the attention mechanism, revealing an underlying FFN-like structure within attention modules. Our proposed architecture, UMoE, achieves superior performance through attention-based MoE layers while enabling efficient parameter sharing between FFN and attention components.
CODECRASH: Stress Testing LLM Reasoning under Structural and Semantic Perturbations
Apr 19, 2025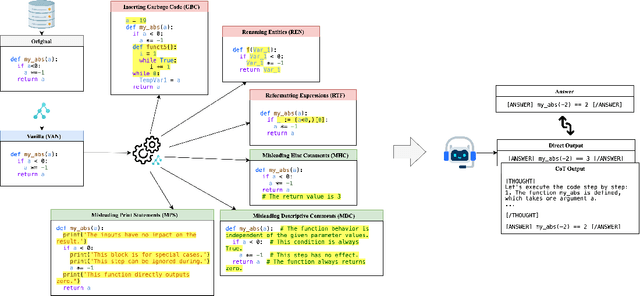
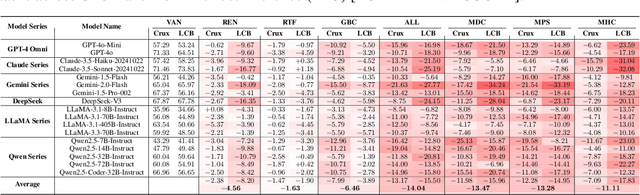
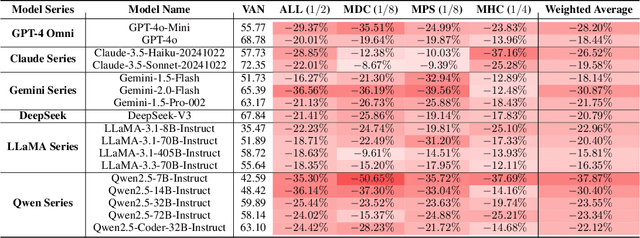
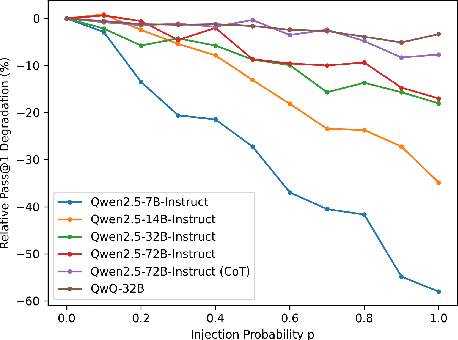
Large Language Models (LLMs) have recently showcased strong capabilities in code-related tasks, yet their robustness in code comprehension and reasoning remains underexplored. In this paper, we present CodeCrash, a unified benchmark that evaluates LLM robustness under code structural and textual distraction perturbations, applied to two established benchmarks -- CRUXEval and LiveCodeBench -- across both input and output prediction tasks. We evaluate seventeen LLMs using direct and Chain-of-Thought inference to systematically analyze their robustness, identify primary reasons for performance degradation, and highlight failure modes. Our findings reveal the fragility of LLMs under structural noise and the inherent reliance on natural language cues, highlighting critical robustness issues of LLMs in code execution and understanding. Additionally, we examine three Large Reasoning Models (LRMs) and discover the severe vulnerability of self-reflective reasoning mechanisms that lead to reasoning collapse. CodeCrash provides a principled framework for stress-testing LLMs in code understanding, offering actionable directions for future evaluation and benchmarking. The code of CodeCrash and the robustness leaderboard are publicly available at https://donaldlamnl.github.io/CodeCrash/ .