 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSplit and Merge: Aligning Position Biases in Large Language Model based Evaluators
Paper and Code


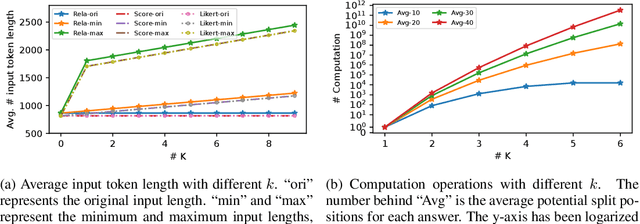

Large language models (LLMs) have shown promise as automated evaluators for assessing the quality of answers generated by AI systems. However, these LLM-based evaluators exhibit position bias, or inconsistency, when used to evaluate candidate answers in pairwise comparisons, favoring either the first or second answer regardless of content. To address this limitation, we propose PORTIA, an alignment-based system designed to mimic human comparison strategies to calibrate position bias in a lightweight yet effective manner. Specifically, PORTIA splits the answers into multiple segments, aligns similar content across candidate answers, and then merges them back into a single prompt for evaluation by LLMs. We conducted extensive experiments with six diverse LLMs to evaluate 11,520 answer pairs. Our results show that PORTIA markedly enhances the consistency rates for all the models and comparison forms tested, achieving an average relative improvement of 47.46%. Remarkably, PORTIA enables less advanced GPT models to achieve 88% agreement with the state-of-the-art GPT-4 model at just 10% of the cost. Furthermore, it rectifies around 80% of the position bias instances within the GPT-4 model, elevating its consistency rate up to 98%. Subsequent human evaluations indicate that the PORTIA-enhanced GPT-3.5 model can even surpass the standalone GPT-4 in terms of alignment with human evaluators. These findings highlight PORTIA's ability to correct position bias, improve LLM consistency, and boost performance while keeping cost-efficiency. This represents a valuable step toward a more reliable and scalable use of LLMs for automated evaluations across diverse applications.