 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Should I Build A Benchmark?
Jan 18, 2025Various benchmarks have been proposed to assess the performance of large language models (LLMs) in different coding scenarios. We refer to them as code-related benchmarks. However, there are no systematic guidelines by which such a benchmark should be developed to ensure its quality, reliability, and reproducibility. We propose How2Bench, which is comprised of a 55- 55-criteria checklist as a set of guidelines to govern the development of code-related benchmarks comprehensively. Using HOW2BENCH, we profiled 274 benchmarks released within the past decade and found concerning issues. Nearly 70% of the benchmarks did not take measures for data quality assurance; over 10% did not even open source or only partially open source. Many highly cited benchmarks have loopholes, including duplicated samples, incorrect reference codes/tests/prompts, and unremoved sensitive/confidential information. Finally, we conducted a human study involving 49 participants, which revealed significant gaps in awareness of the importance of data quality, reproducibility, and transparency.
Towards Biologically Plausible Computing: A Comprehensive Comparison
Jun 23, 2024



Backpropagation is a cornerstone algorithm in training neural networks for supervised learning, which uses a gradient descent method to update network weights by minimizing the discrepancy between actual and desired outputs. Despite its pivotal role in propelling deep learning advancements, the biological plausibility of backpropagation is questioned due to its requirements for weight symmetry, global error computation, and dual-phase training. To address this long-standing challenge, many studies have endeavored to devise biologically plausible training algorithms. However, a fully biologically plausible algorithm for training multilayer neural networks remains elusive, and interpretations of biological plausibility vary among researchers. In this study, we establish criteria for biological plausibility that a desirable learning algorithm should meet. Using these criteria, we evaluate a range of existing algorithms considered to be biologically plausible, including Hebbian learning, spike-timing-dependent plasticity, feedback alignment, target propagation, predictive coding, forward-forward algorithm, perturbation learning, local losses, and energy-based learning. Additionally, we empirically evaluate these algorithms across diverse network architectures and datasets. We compare the feature representations learned by these algorithms with brain activity recorded by non-invasive devices under identical stimuli, aiming to identify which algorithm can most accurately replicate brain activity patterns. We are hopeful that this study could inspire the development of new biologically plausible algorithms for training multilayer networks, thereby fostering progress in both the fields of neuroscience and machine learning.
Promoting Data and Model Privacy in Federated Learning through Quantized LoRA
Jun 16, 2024Conventional federated learning primarily aims to secure the privacy of data distributed across multiple edge devices, with the global model dispatched to edge devices for parameter updates during the learning process. However, the development of large language models (LLMs) requires substantial data and computational resources, rendering them valuable intellectual properties for their developers and owners. To establish a mechanism that protects both data and model privacy in a federated learning context, we introduce a method that just needs to distribute a quantized version of the model's parameters during training. This method enables accurate gradient estimations for parameter updates while preventing clients from accessing a model whose performance is comparable to the centrally hosted one. Moreover, we combine this quantization strategy with LoRA, a popular and parameter-efficient fine-tuning method, to significantly reduce communication costs in federated learning. The proposed framework, named \textsc{FedLPP}, successfully ensures both data and model privacy in the federated learning context. Additionally, the learned central model exhibits good generalization and can be trained in a resource-efficient manner.
Decoding Continuous Character-based Language from Non-invasive Brain Recordings
Mar 19, 2024Deciphering natural language from brain activity through non-invasive devices remains a formidable challenge. Previous non-invasive decoders either require multiple experiments with identical stimuli to pinpoint cortical regions and enhance signal-to-noise ratios in brain activity, or they are limited to discerning basic linguistic elements such as letters and words. We propose a novel approach to decoding continuous language from single-trial non-invasive fMRI recordings, in which a three-dimensional convolutional network augmented with information bottleneck is developed to automatically identify responsive voxels to stimuli, and a character-based decoder is designed for the semantic reconstruction of continuous language characterized by inherent character structures. The resulting decoder can produce intelligible textual sequences that faithfully capture the meaning of perceived speech both within and across subjects, while existing decoders exhibit significantly inferior performance in cross-subject contexts. The ability to decode continuous language from single trials across subjects demonstrates the promising applications of non-invasive language brain-computer interfaces in both healthcare and neuroscience.
Advancing Parameter Efficiency in Fine-tuning via Representation Editing
Feb 28, 2024Parameter Efficient Fine-Tuning (PEFT) has gained significant attention for its ability to achieve competitive results while updating only a small subset of trainable parameters. Despite the promising performance of current PEFT methods, they present challenges in hyperparameter selection, such as determining the rank of LoRA or Adapter, or specifying the length of soft prompts. In addressing these challenges, we propose a novel approach to fine-tuning neural models, termed Representation EDiting (RED), which scales and biases the representation produced at each layer. RED substantially reduces the number of trainable parameters by a factor of $25,700$ compared to full parameter fine-tuning, and by a factor of $32$ compared to LoRA. Remarkably, RED achieves comparable or superior results to full parameter fine-tuning and other PEFT methods. Extensive experiments were conducted across models of varying architectures and scales, including RoBERTa, GPT-2, T5, and Llama-2, and the results demonstrate the efficiency and efficacy of RED, positioning it as a promising PEFT approach for large neural models.
Aligning Large Language Models with Human Preferences through Representation Engineering
Dec 26, 2023



Aligning large language models (LLMs) with human preferences is crucial for enhancing their utility in terms of helpfulness, truthfulness, safety, harmlessness, and interestingness. Existing methods for achieving this alignment often involves employing reinforcement learning from human feedback (RLHF) to fine-tune LLMs based on human labels assessing the relative quality of model responses. Nevertheless, RLHF is susceptible to instability during fine-tuning and presents challenges in implementation.Drawing inspiration from the emerging field of representation engineering (RepE), this study aims to identify relevant representations for high-level human preferences embedded in patterns of activity within an LLM, and achieve precise control of model behavior by transforming its representations. This novel approach, denoted as Representation Alignment from Human Feedback (RAHF), proves to be effective, computationally efficient, and easy to implement.Extensive experiments demonstrate the efficacy of RAHF in not only capturing but also manipulating representations to align with a broad spectrum of human preferences or values, rather than being confined to a singular concept or function (e.g. honesty or bias). RAHF's versatility in accommodating diverse human preferences shows its potential for advancing LLM performance.
SpikeBERT: A Language Spikformer Trained with Two-Stage Knowledge Distillation from BERT
Aug 30, 2023
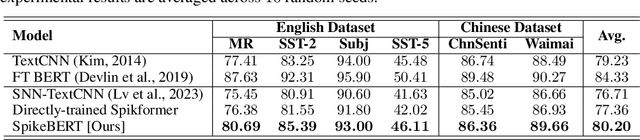


Spiking neural networks (SNNs) offer a promising avenue to implement deep neural networks in a more energy-efficient way. However, the network architectures of existing SNNs for language tasks are too simplistic, and deep architectures have not been fully explored, resulting in a significant performance gap compared to mainstream transformer-based networks such as BERT. To this end, we improve a recently-proposed spiking transformer (i.e., Spikformer) to make it possible to process language tasks and propose a two-stage knowledge distillation method for training it, which combines pre-training by distilling knowledge from BERT with a large collection of unlabelled texts and fine-tuning with task-specific instances via knowledge distillation again from the BERT fine-tuned on the same training examples. Through extensive experimentation, we show that the models trained with our method, named SpikeBERT, outperform state-of-the-art SNNs and even achieve comparable results to BERTs on text classification tasks for both English and Chinese with much less energy consumption.