 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Continual Pre-training Through Seamless Data Packing
May 29, 2025



Continual pre-training has demonstrated significant potential in enhancing model performance, particularly in domain-specific scenarios. The most common approach for packing data before continual pre-training involves concatenating input texts and splitting them into fixed-length sequences. While straightforward and efficient, this method often leads to excessive truncation and context discontinuity, which can hinder model performance. To address these issues, we explore the potential of data engineering to enhance continual pre-training, particularly its impact on model performance and efficiency. We propose Seamless Packing (SP), a novel data packing strategy aimed at preserving contextual information more effectively and enhancing model performance. Our approach employs a sliding window technique in the first stage that synchronizes overlapping tokens across consecutive sequences, ensuring better continuity and contextual coherence. In the second stage, we adopt a First-Fit-Decreasing algorithm to pack shorter texts into bins slightly larger than the target sequence length, thereby minimizing padding and truncation. Empirical evaluations across various model architectures and corpus domains demonstrate the effectiveness of our method, outperforming baseline method in 99% of all settings. Code is available at https://github.com/Infernus-WIND/Seamless-Packing.
Controlling Avatar Diffusion with Learnable Gaussian Embedding
Mar 20, 2025Recent advances in diffusion models have made significant progress in digital human generation. However, most existing models still struggle to maintain 3D consistency, temporal coherence, and motion accuracy. A key reason for these shortcomings is the limited representation ability of commonly used control signals(e.g., landmarks, depth maps, etc.). In addition, the lack of diversity in identity and pose variations in public datasets further hinders progress in this area. In this paper, we analyze the shortcomings of current control signals and introduce a novel control signal representation that is optimizable, dense, expressive, and 3D consistent. Our method embeds a learnable neural Gaussian onto a parametric head surface, which greatly enhances the consistency and expressiveness of diffusion-based head models. Regarding the dataset, we synthesize a large-scale dataset with multiple poses and identities. In addition, we use real/synthetic labels to effectively distinguish real and synthetic data, minimizing the impact of imperfections in synthetic data on the generated head images. Extensive experiments show that our model outperforms existing methods in terms of realism, expressiveness, and 3D consistency. Our code, synthetic datasets, and pre-trained models will be released in our project page: https://ustc3dv.github.io/Learn2Control/
Searching for Best Practices in Retrieval-Augmented Generation
Jul 01, 2024



Retrieval-augmented generation (RAG) techniques have proven to be effective in integrating up-to-date information, mitigating hallucinations, and enhancing response quality, particularly in specialized domains. While many RAG approaches have been proposed to enhance large language models through query-dependent retrievals, these approaches still suffer from their complex implementation and prolonged response times. Typically, a RAG workflow involves multiple processing steps, each of which can be executed in various ways. Here, we investigate existing RAG approaches and their potential combinations to identify optimal RAG practices. Through extensive experiments, we suggest several strategies for deploying RAG that balance both performance and efficiency. Moreover, we demonstrate that multimodal retrieval techniques can significantly enhance question-answering capabilities about visual inputs and accelerate the generation of multimodal content using a "retrieval as generation" strategy.
Decoding Continuous Character-based Language from Non-invasive Brain Recordings
Mar 19, 2024Deciphering natural language from brain activity through non-invasive devices remains a formidable challenge. Previous non-invasive decoders either require multiple experiments with identical stimuli to pinpoint cortical regions and enhance signal-to-noise ratios in brain activity, or they are limited to discerning basic linguistic elements such as letters and words. We propose a novel approach to decoding continuous language from single-trial non-invasive fMRI recordings, in which a three-dimensional convolutional network augmented with information bottleneck is developed to automatically identify responsive voxels to stimuli, and a character-based decoder is designed for the semantic reconstruction of continuous language characterized by inherent character structures. The resulting decoder can produce intelligible textual sequences that faithfully capture the meaning of perceived speech both within and across subjects, while existing decoders exhibit significantly inferior performance in cross-subject contexts. The ability to decode continuous language from single trials across subjects demonstrates the promising applications of non-invasive language brain-computer interfaces in both healthcare and neuroscience.
FlashAvatar: High-Fidelity Digital Avatar Rendering at 300FPS
Dec 03, 2023We propose FlashAvatar, a novel and lightweight 3D animatable avatar representation that could reconstruct a digital avatar from a short monocular video sequence in minutes and render high-fidelity photo-realistic images at 300FPS on a consumer-grade GPU. To achieve this, we maintain a uniform 3D Gaussian field embedded in the surface of a parametric face model and learn extra spatial offset to model non-surface regions and subtle facial details. While full use of geometric priors can capture high-frequency facial details and preserve exaggerated expressions, proper initialization can help reduce the number of Gaussians, thus enabling super-fast rendering speed. Extensive experimental results demonstrate that FlashAvatar outperforms existing works regarding visual quality and personalized details and is almost an order of magnitude faster in rendering speed. Project page: https://ustc3dv.github.io/FlashAvatar/
CosAvatar: Consistent and Animatable Portrait Video Tuning with Text Prompt
Nov 30, 2023Recently, text-guided digital portrait editing has attracted more and more attentions. However, existing methods still struggle to maintain consistency across time, expression, and view or require specific data prerequisites. To solve these challenging problems, we propose CosAvatar, a high-quality and user-friendly framework for portrait tuning. With only monocular video and text instructions as input, we can produce animatable portraits with both temporal and 3D consistency. Different from methods that directly edit in the 2D domain, we employ a dynamic NeRF-based 3D portrait representation to model both the head and torso. We alternate between editing the video frames' dataset and updating the underlying 3D portrait until the edited frames reach 3D consistency. Additionally, we integrate the semantic portrait priors to enhance the edited results, allowing precise modifications in specified semantic areas. Extensive results demonstrate that our proposed method can not only accurately edit portrait styles or local attributes based on text instructions but also support expressive animation driven by a source video.
IntrinsicNGP: Intrinsic Coordinate based Hash Encoding for Human NeRF
Mar 09, 2023Recently, many works have been proposed to utilize the neural radiance field for novel view synthesis of human performers. However, most of these methods require hours of training, making them difficult for practical use. To address this challenging problem, we propose IntrinsicNGP, which can train from scratch and achieve high-fidelity results in few minutes with videos of a human performer. To achieve this target, we introduce a continuous and optimizable intrinsic coordinate rather than the original explicit Euclidean coordinate in the hash encoding module of instant-NGP. With this novel intrinsic coordinate, IntrinsicNGP can aggregate inter-frame information for dynamic objects with the help of proxy geometry shapes. Moreover, the results trained with the given rough geometry shapes can be further refined with an optimizable offset field based on the intrinsic coordinate.Extensive experimental results on several datasets demonstrate the effectiveness and efficiency of IntrinsicNGP. We also illustrate our approach's ability to edit the shape of reconstructed subjects.
Reconstructing Personalized Semantic Facial NeRF Models From Monocular Video
Oct 12, 2022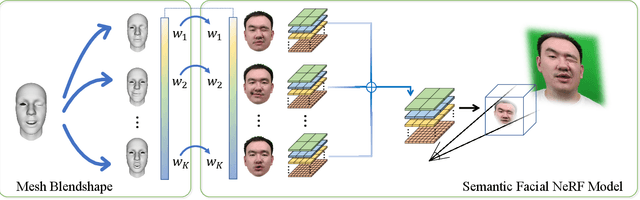

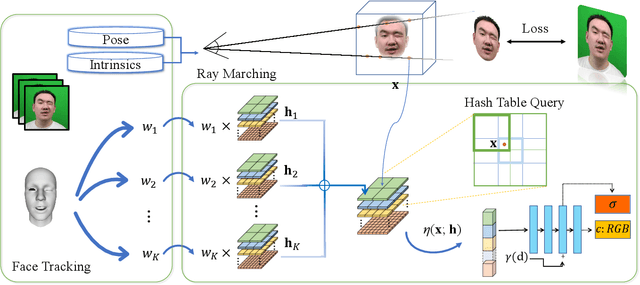
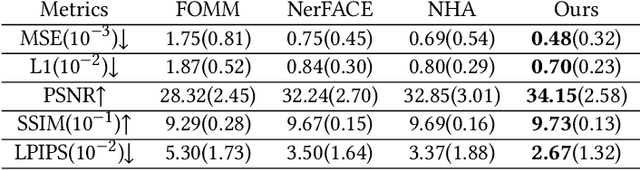
We present a novel semantic model for human head defined with neural radiance field. The 3D-consistent head model consist of a set of disentangled and interpretable bases, and can be driven by low-dimensional expression coefficients. Thanks to the powerful representation ability of neural radiance field, the constructed model can represent complex facial attributes including hair, wearings, which can not be represented by traditional mesh blendshape. To construct the personalized semantic facial model, we propose to define the bases as several multi-level voxel fields. With a short monocular RGB video as input, our method can construct the subject's semantic facial NeRF model with only ten to twenty minutes, and can render a photo-realistic human head image in tens of miliseconds with a given expression coefficient and view direction. With this novel representation, we apply it to many tasks like facial retargeting and expression editing. Experimental results demonstrate its strong representation ability and training/inference speed. Demo videos and released code are provided in our project page: https://ustc3dv.github.io/NeRFBlendShape/
* Accepted by SIGGRAPH Asia 2022 (Journal Track). Project page: https://ustc3dv.github.io/NeRFBlendShape/
Community Trend Prediction on Heterogeneous Graph in E-commerce
Feb 24, 2022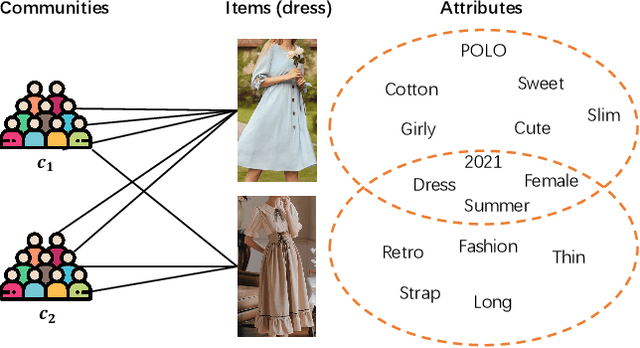
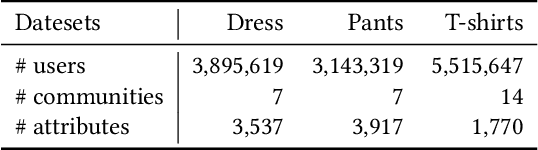
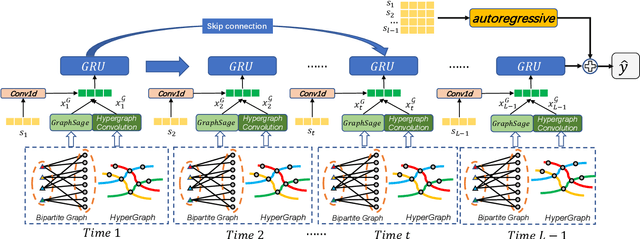
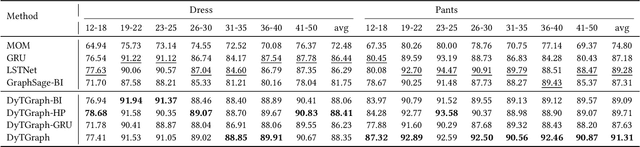
In online shopping, ever-changing fashion trends make merchants need to prepare more differentiated products to meet the diversified demands, and e-commerce platforms need to capture the market trend with a prophetic vision. For the trend prediction, the attribute tags, as the essential description of items, can genuinely reflect the decision basis of consumers. However, few existing works explore the attribute trend in the specific community for e-commerce. In this paper, we focus on the community trend prediction on the item attribute and propose a unified framework that combines the dynamic evolution of two graph patterns to predict the attribute trend in a specific community. Specifically, we first design a communityattribute bipartite graph at each time step to learn the collaboration of different communities. Next, we transform the bipartite graph into a hypergraph to exploit the associations of different attribute tags in one community. Lastly, we introduce a dynamic evolution component based on the recurrent neural networks to capture the fashion trend of attribute tags. Extensive experiments on three real-world datasets in a large e-commerce platform show the superiority of the proposed approach over several strong alternatives and demonstrate the ability to discover the community trend in advance.