 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCosAvatar: Consistent and Animatable Portrait Video Tuning with Text Prompt
Nov 30, 2023Recently, text-guided digital portrait editing has attracted more and more attentions. However, existing methods still struggle to maintain consistency across time, expression, and view or require specific data prerequisites. To solve these challenging problems, we propose CosAvatar, a high-quality and user-friendly framework for portrait tuning. With only monocular video and text instructions as input, we can produce animatable portraits with both temporal and 3D consistency. Different from methods that directly edit in the 2D domain, we employ a dynamic NeRF-based 3D portrait representation to model both the head and torso. We alternate between editing the video frames' dataset and updating the underlying 3D portrait until the edited frames reach 3D consistency. Additionally, we integrate the semantic portrait priors to enhance the edited results, allowing precise modifications in specified semantic areas. Extensive results demonstrate that our proposed method can not only accurately edit portrait styles or local attributes based on text instructions but also support expressive animation driven by a source video.
MetaHead: An Engine to Create Realistic Digital Head
Apr 03, 2023



Collecting and labeling training data is one important step for learning-based methods because the process is time-consuming and biased. For face analysis tasks, although some generative models can be used to generate face data, they can only achieve a subset of generation diversity, reconstruction accuracy, 3D consistency, high-fidelity visual quality, and easy editability. One recent related work is the graphics-based generative method, but it can only render low realism head with high computation cost. In this paper, we propose MetaHead, a unified and full-featured controllable digital head engine, which consists of a controllable head radiance field(MetaHead-F) to super-realistically generate or reconstruct view-consistent 3D controllable digital heads and a generic top-down image generation framework LabelHead to generate digital heads consistent with the given customizable feature labels. Experiments validate that our controllable digital head engine achieves the state-of-the-art generation visual quality and reconstruction accuracy. Moreover, the generated labeled data can assist real training data and significantly surpass the labeled data generated by graphics-based methods in terms of training effect.
Reconstructing Personalized Semantic Facial NeRF Models From Monocular Video
Oct 12, 2022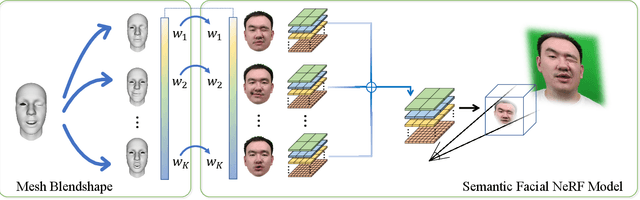

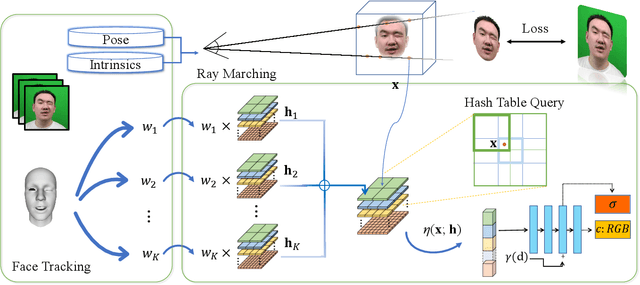
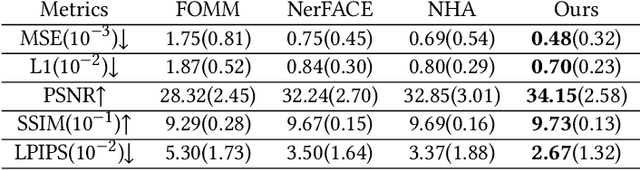
We present a novel semantic model for human head defined with neural radiance field. The 3D-consistent head model consist of a set of disentangled and interpretable bases, and can be driven by low-dimensional expression coefficients. Thanks to the powerful representation ability of neural radiance field, the constructed model can represent complex facial attributes including hair, wearings, which can not be represented by traditional mesh blendshape. To construct the personalized semantic facial model, we propose to define the bases as several multi-level voxel fields. With a short monocular RGB video as input, our method can construct the subject's semantic facial NeRF model with only ten to twenty minutes, and can render a photo-realistic human head image in tens of miliseconds with a given expression coefficient and view direction. With this novel representation, we apply it to many tasks like facial retargeting and expression editing. Experimental results demonstrate its strong representation ability and training/inference speed. Demo videos and released code are provided in our project page: https://ustc3dv.github.io/NeRFBlendShape/
* Accepted by SIGGRAPH Asia 2022 (Journal Track). Project page: https://ustc3dv.github.io/NeRFBlendShape/