 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReconstructing Quantitative Cerebral Perfusion Images Directly From Measured Sinogram Data Acquired Using C-arm Cone-Beam CT
Dec 06, 2024



To shorten the door-to-puncture time for better treating patients with acute ischemic stroke, it is highly desired to obtain quantitative cerebral perfusion images using C-arm cone-beam computed tomography (CBCT) equipped in the interventional suite. However, limited by the slow gantry rotation speed, the temporal resolution and temporal sampling density of typical C-arm CBCT are much poorer than those of multi-detector-row CT in the diagnostic imaging suite. The current quantitative perfusion imaging includes two cascaded steps: time-resolved image reconstruction and perfusion parametric estimation. For time-resolved image reconstruction, the technical challenge imposed by poor temporal resolution and poor sampling density causes inaccurate quantification of the temporal variation of cerebral artery and tissue attenuation values. For perfusion parametric estimation, it remains a technical challenge to appropriately design the handcrafted regularization for better solving the associated deconvolution problem. These two challenges together prevent obtaining quantitatively accurate perfusion images using C-arm CBCT. The purpose of this work is to simultaneously address these two challenges by combining the two cascaded steps into a single joint optimization problem and reconstructing quantitative perfusion images directly from the measured sinogram data. In the developed direct cerebral perfusion parametric image reconstruction technique, TRAINER in short, the quantitative perfusion images have been represented as a subject-specific conditional generative model trained under the constraint of the time-resolved CT forward model, perfusion convolutional model, and the subject's own measured sinogram data. Results shown in this paper demonstrated that using TRAINER, quantitative cerebral perfusion images can be accurately obtained using C-arm CBCT in the interventional suite.
One Shot, One Talk: Whole-body Talking Avatar from a Single Image
Dec 02, 2024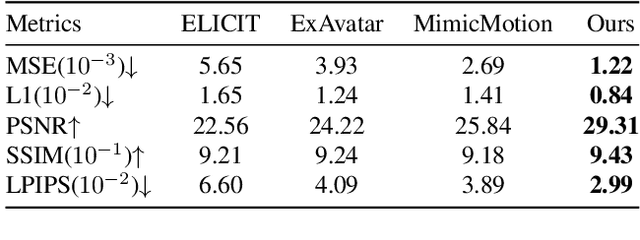
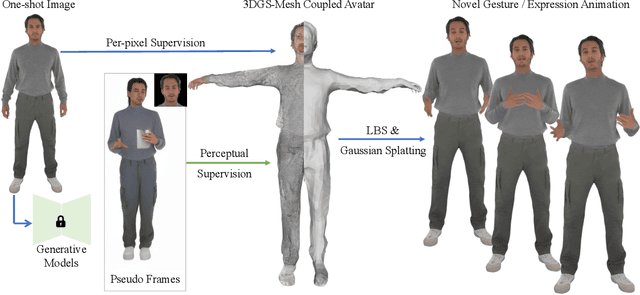
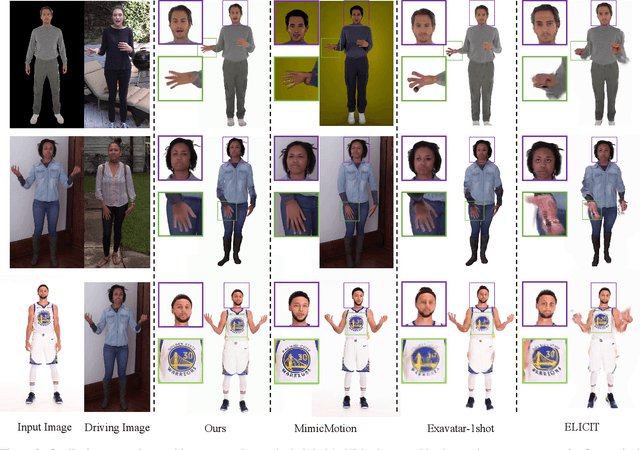

Building realistic and animatable avatars still requires minutes of multi-view or monocular self-rotating videos, and most methods lack precise control over gestures and expressions. To push this boundary, we address the challenge of constructing a whole-body talking avatar from a single image. We propose a novel pipeline that tackles two critical issues: 1) complex dynamic modeling and 2) generalization to novel gestures and expressions. To achieve seamless generalization, we leverage recent pose-guided image-to-video diffusion models to generate imperfect video frames as pseudo-labels. To overcome the dynamic modeling challenge posed by inconsistent and noisy pseudo-videos, we introduce a tightly coupled 3DGS-mesh hybrid avatar representation and apply several key regularizations to mitigate inconsistencies caused by imperfect labels. Extensive experiments on diverse subjects demonstrate that our method enables the creation of a photorealistic, precisely animatable, and expressive whole-body talking avatar from just a single image.
Convex Approximation of Probabilistic Reachable Sets from Small Samples Using Self-supervised Neural Networks
Nov 21, 2024



Probabilistic Reachable Set (PRS) plays a crucial role in many fields of autonomous systems, yet efficiently generating PRS remains a significant challenge. This paper presents a learning approach to generating 2-dimensional PRS for states in a dynamic system. Traditional methods such as Hamilton-Jacobi reachability analysis, Monte Carlo, and Gaussian process classification face significant computational challenges or require detailed dynamics information, limiting their applicability in realistic situations. Existing data-driven methods may lack accuracy. To overcome these limitations, we propose leveraging neural networks, commonly used in imitation learning and computer vision, to imitate expert methods to generate PRS approximations. We trained the neural networks using a multi-label, self-supervised learning approach. We selected the fine-tuned convex approximation method as the expert to create expert PRS. Additionally, we continued sampling from the distribution to obtain a diverse array of sample sets. Given a small sample set, the trained neural networks can replicate the PRS approximation generated by the expert method, while the generation speed is much faster.
Transformer-based Heuristic for Advanced Air Mobility Planning
Nov 21, 2024



Safety is extremely important for urban flights of autonomous Unmanned Aerial Vehicles (UAVs). Risk-aware path planning is one of the most effective methods to guarantee the safety of UAVs. This type of planning can be represented as a Constrained Shortest Path (CSP) problem, which seeks to find the shortest route that meets a predefined safety constraint. Solving CSP problems is NP-hard, presenting significant computational challenges. Although traditional methods can accurately solve CSP problems, they tend to be very slow. Previously, we introduced an additional safety dimension to the traditional A* algorithm, known as ASD A*, to effectively handle Constrained Shortest Path (CSP) problems. Then, we developed a custom learning-based heuristic using transformer-based neural networks, which significantly reduced computational load and enhanced the performance of the ASD A* algorithm. In this paper, we expand our dataset to include more risk maps and tasks, improve the proposed model, and increase its performance. We also introduce a new heuristic strategy and a novel neural network, which enhance the overall effectiveness of our approach.
Landing Trajectory Prediction for UAS Based on Generative Adversarial Network
Nov 21, 2024



Models for trajectory prediction are an essential component of many advanced air mobility studies. These models help aircraft detect conflict and plan avoidance maneuvers, which is especially important in Unmanned Aircraft systems (UAS) landing management due to the congested airspace near vertiports. In this paper, we propose a landing trajectory prediction model for UAS based on Generative Adversarial Network (GAN). The GAN is a prestigious neural network that has been developed for many years. In previous research, GAN has achieved many state-of-the-art results in many generation tasks. The GAN consists of one neural network generator and a neural network discriminator. Because of the learning capacity of the neural networks, the generator is capable to understand the features of the sample trajectory. The generator takes the previous trajectory as input and outputs some random status of a flight. According to the results of the experiences, the proposed model can output more accurate predictions than the baseline method(GMR) in various datasets. To evaluate the proposed model, we also create a real UAV landing dataset that includes more than 2600 trajectories of drone control manually by real pilots.
Data-driven Probabilistic Trajectory Learning with High Temporal Resolution in Terminal Airspace
Sep 25, 2024



Predicting flight trajectories is a research area that holds significant merit. In this paper, we propose a data-driven learning framework, that leverages the predictive and feature extraction capabilities of the mixture models and seq2seq-based neural networks while addressing prevalent challenges caused by error propagation and dimensionality reduction. After training with this framework, the learned model can improve long-step prediction accuracy significantly given the past trajectories and the context information. The accuracy and effectiveness of the approach are evaluated by comparing the predicted trajectories with the ground truth. The results indicate that the proposed method has outperformed the state-of-the-art predicting methods on a terminal airspace flight trajectory dataset. The trajectories generated by the proposed method have a higher temporal resolution(1 timestep per second vs 0.1 timestep per second) and are closer to the ground truth.
Learning-accelerated A* Search for Risk-aware Path Planning
Sep 18, 2024Safety is a critical concern for urban flights of autonomous Unmanned Aerial Vehicles. In populated environments, risk should be accounted for to produce an effective and safe path, known as risk-aware path planning. Risk-aware path planning can be modeled as a Constrained Shortest Path (CSP) problem, aiming to identify the shortest possible route that adheres to specified safety thresholds. CSP is NP-hard and poses significant computational challenges. Although many traditional methods can solve it accurately, all of them are very slow. Our method introduces an additional safety dimension to the traditional A* (called ASD A*), enabling A* to handle CSP. Furthermore, we develop a custom learning-based heuristic using transformer-based neural networks, which significantly reduces the computational load and improves the performance of the ASD A* algorithm. The proposed method is well-validated with both random and realistic simulation scenarios.
* AIAA SCITECH 2024 Forum
FlashAvatar: High-Fidelity Digital Avatar Rendering at 300FPS
Dec 03, 2023We propose FlashAvatar, a novel and lightweight 3D animatable avatar representation that could reconstruct a digital avatar from a short monocular video sequence in minutes and render high-fidelity photo-realistic images at 300FPS on a consumer-grade GPU. To achieve this, we maintain a uniform 3D Gaussian field embedded in the surface of a parametric face model and learn extra spatial offset to model non-surface regions and subtle facial details. While full use of geometric priors can capture high-frequency facial details and preserve exaggerated expressions, proper initialization can help reduce the number of Gaussians, thus enabling super-fast rendering speed. Extensive experimental results demonstrate that FlashAvatar outperforms existing works regarding visual quality and personalized details and is almost an order of magnitude faster in rendering speed. Project page: https://ustc3dv.github.io/FlashAvatar/
Mini-PointNetPlus: a local feature descriptor in deep learning model for 3d environment perception
Jul 25, 2023Common deep learning models for 3D environment perception often use pillarization/voxelization methods to convert point cloud data into pillars/voxels and then process it with a 2D/3D convolutional neural network (CNN). The pioneer work PointNet has been widely applied as a local feature descriptor, a fundamental component in deep learning models for 3D perception, to extract features of a point cloud. This is achieved by using a symmetric max-pooling operator which provides unique pillar/voxel features. However, by ignoring most of the points, the max-pooling operator causes an information loss, which reduces the model performance. To address this issue, we propose a novel local feature descriptor, mini-PointNetPlus, as an alternative for plug-and-play to PointNet. Our basic idea is to separately project the data points to the individual features considered, each leading to a permutation invariant. Thus, the proposed descriptor transforms an unordered point cloud to a stable order. The vanilla PointNet is proved to be a special case of our mini-PointNetPlus. Due to fully utilizing the features by the proposed descriptor, we demonstrate in experiment a considerable performance improvement for 3D perception.
Reconstructing Personalized Semantic Facial NeRF Models From Monocular Video
Oct 12, 2022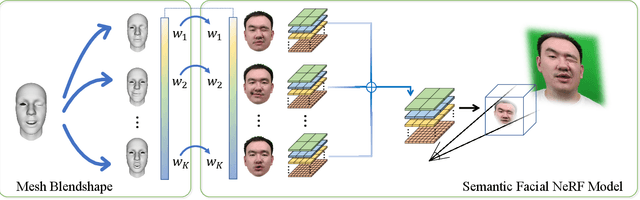

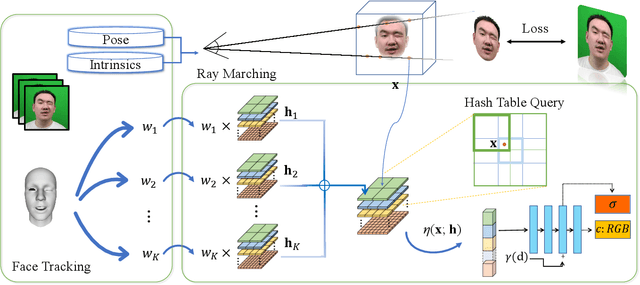
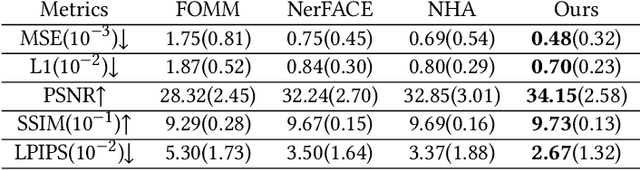
We present a novel semantic model for human head defined with neural radiance field. The 3D-consistent head model consist of a set of disentangled and interpretable bases, and can be driven by low-dimensional expression coefficients. Thanks to the powerful representation ability of neural radiance field, the constructed model can represent complex facial attributes including hair, wearings, which can not be represented by traditional mesh blendshape. To construct the personalized semantic facial model, we propose to define the bases as several multi-level voxel fields. With a short monocular RGB video as input, our method can construct the subject's semantic facial NeRF model with only ten to twenty minutes, and can render a photo-realistic human head image in tens of miliseconds with a given expression coefficient and view direction. With this novel representation, we apply it to many tasks like facial retargeting and expression editing. Experimental results demonstrate its strong representation ability and training/inference speed. Demo videos and released code are provided in our project page: https://ustc3dv.github.io/NeRFBlendShape/
* Accepted by SIGGRAPH Asia 2022 (Journal Track). Project page: https://ustc3dv.github.io/NeRFBlendShape/