 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHead-Aware Visual Cropping: Enhancing Fine-Grained VQA with Attention-Guided Subimage
Jan 30, 2026Multimodal Large Language Models (MLLMs) show strong performance in Visual Question Answering (VQA) but remain limited in fine-grained reasoning due to low-resolution inputs and noisy attention aggregation. We propose \textbf{Head Aware Visual Cropping (HAVC)}, a training-free method that improves visual grounding by leveraging a selectively refined subset of attention heads. HAVC first filters heads through an OCR-based diagnostic task, ensuring that only those with genuine grounding ability are retained. At inference, these heads are further refined using spatial entropy for stronger spatial concentration and gradient sensitivity for predictive contribution. The fused signals produce a reliable Visual Cropping Guidance Map, which highlights the most task-relevant region and guides the cropping of a subimage subsequently provided to the MLLM together with the image-question pair. Extensive experiments on multiple fine-grained VQA benchmarks demonstrate that HAVC consistently outperforms state-of-the-art cropping strategies, achieving more precise localization, stronger visual grounding, providing a simple yet effective strategy for enhancing precision in MLLMs.
Landing Trajectory Prediction for UAS Based on Generative Adversarial Network
Nov 21, 2024



Models for trajectory prediction are an essential component of many advanced air mobility studies. These models help aircraft detect conflict and plan avoidance maneuvers, which is especially important in Unmanned Aircraft systems (UAS) landing management due to the congested airspace near vertiports. In this paper, we propose a landing trajectory prediction model for UAS based on Generative Adversarial Network (GAN). The GAN is a prestigious neural network that has been developed for many years. In previous research, GAN has achieved many state-of-the-art results in many generation tasks. The GAN consists of one neural network generator and a neural network discriminator. Because of the learning capacity of the neural networks, the generator is capable to understand the features of the sample trajectory. The generator takes the previous trajectory as input and outputs some random status of a flight. According to the results of the experiences, the proposed model can output more accurate predictions than the baseline method(GMR) in various datasets. To evaluate the proposed model, we also create a real UAV landing dataset that includes more than 2600 trajectories of drone control manually by real pilots.
Learning-accelerated A* Search for Risk-aware Path Planning
Sep 18, 2024

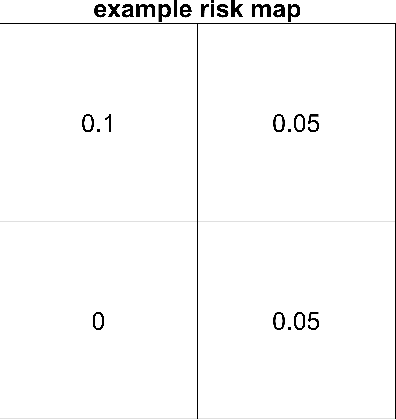
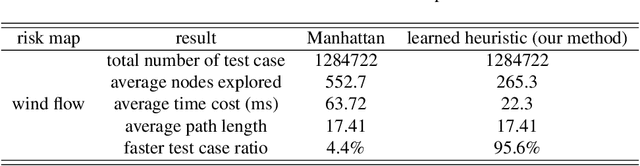
Safety is a critical concern for urban flights of autonomous Unmanned Aerial Vehicles. In populated environments, risk should be accounted for to produce an effective and safe path, known as risk-aware path planning. Risk-aware path planning can be modeled as a Constrained Shortest Path (CSP) problem, aiming to identify the shortest possible route that adheres to specified safety thresholds. CSP is NP-hard and poses significant computational challenges. Although many traditional methods can solve it accurately, all of them are very slow. Our method introduces an additional safety dimension to the traditional A* (called ASD A*), enabling A* to handle CSP. Furthermore, we develop a custom learning-based heuristic using transformer-based neural networks, which significantly reduces the computational load and improves the performance of the ASD A* algorithm. The proposed method is well-validated with both random and realistic simulation scenarios.
* AIAA SCITECH 2024 Forum
DARL1N: Distributed multi-Agent Reinforcement Learning with One-hop Neighbors
Feb 18, 2022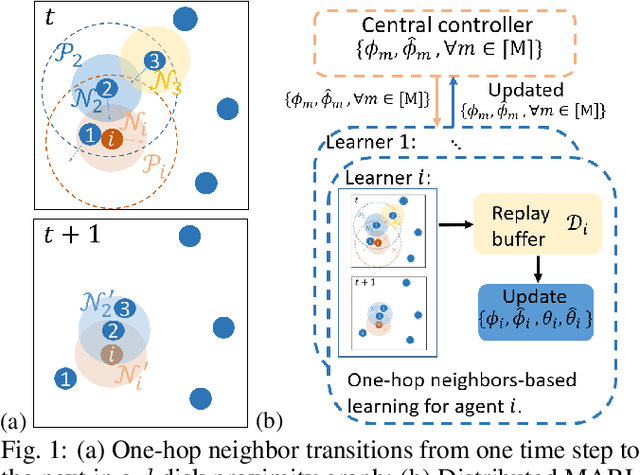

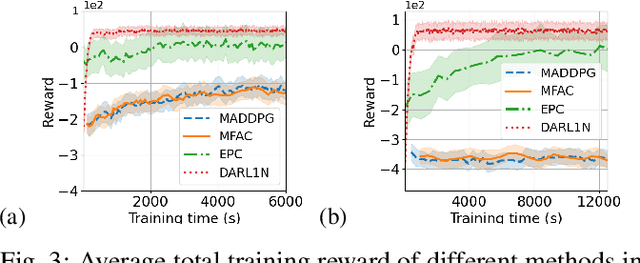
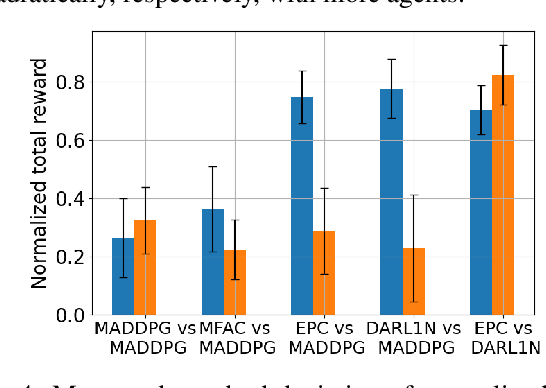
Most existing multi-agent reinforcement learning (MARL) methods are limited in the scale of problems they can handle. Particularly, with the increase of the number of agents, their training costs grow exponentially. In this paper, we address this limitation by introducing a scalable MARL method called Distributed multi-Agent Reinforcement Learning with One-hop Neighbors (DARL1N). DARL1N is an off-policy actor-critic method that breaks the curse of dimensionality by decoupling the global interactions among agents and restricting information exchanges to one-hop neighbors. Each agent optimizes its action value and policy functions over a one-hop neighborhood, significantly reducing the learning complexity, yet maintaining expressiveness by training with varying numbers and states of neighbors. This structure allows us to formulate a distributed learning framework to further speed up the training procedure. Comparisons with state-of-the-art MARL methods show that DARL1N significantly reduces training time without sacrificing policy quality and is scalable as the number of agents increases.
Risk-bounded Path Planning for Urban Air Mobility Operations under Uncertainty
Sep 10, 2021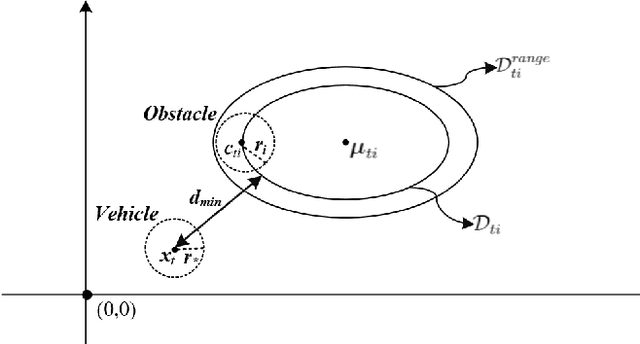
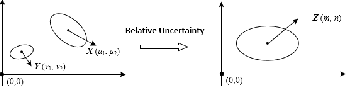
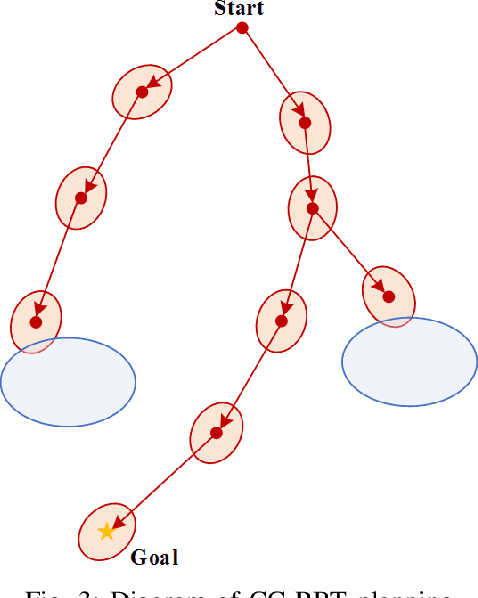
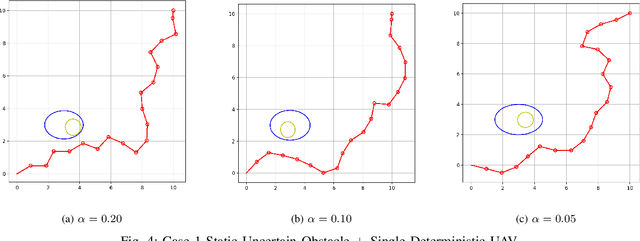
Collision avoidance is an essential concern for the autonomous operations of aerial vehicles in dynamic and uncertain urban environments. This paper introduces a risk-bounded path planning algorithm for unmanned aerial vehicles (UAVs) operating in such environments. This algorithm advances the rapidly-exploring random tree (RRT) with chance constraints to generate probabilistically guaranteed collision-free paths that are robust to vehicle and environmental obstacle uncertainties. Assuming all uncertainties follow Gaussian distributions, the chance constraints are established through converting dynamic and probabilistic constraints into equivalent static and deterministic constraints. By incorporating chance constraints into the RRT algorithm, the proposed algorithm not only inherits the computational advantage of sampling-based algorithms but also guarantees a probabilistically feasible flying zone at every time step. Simulation results show the promising performance of the proposed algorithm.
Multi-Agent Reinforcement Learning Based Coded Computation for Mobile Ad Hoc Computing
Apr 15, 2021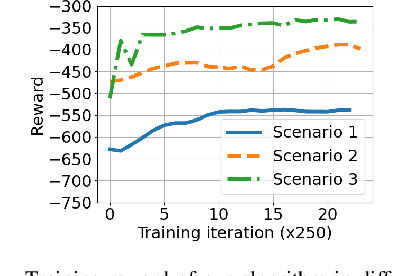
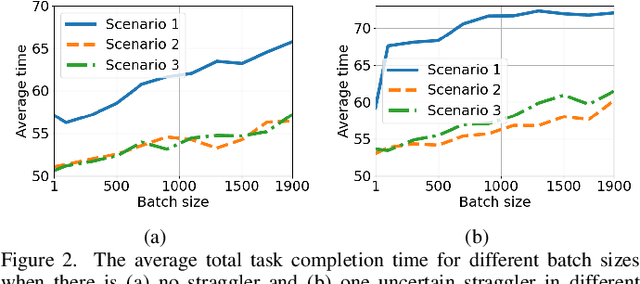
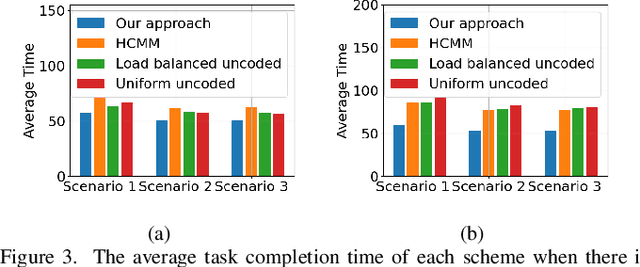
Mobile ad hoc computing (MAHC), which allows mobile devices to directly share their computing resources, is a promising solution to address the growing demands for computing resources required by mobile devices. However, offloading a computation task from a mobile device to other mobile devices is a challenging task due to frequent topology changes and link failures because of node mobility, unstable and unknown communication environments, and the heterogeneous nature of these devices. To address these challenges, in this paper, we introduce a novel coded computation scheme based on multi-agent reinforcement learning (MARL), which has many promising features such as adaptability to network changes, high efficiency and robustness to uncertain system disturbances, consideration of node heterogeneity, and decentralized load allocation. Comprehensive simulation studies demonstrate that the proposed approach can outperform state-of-the-art distributed computing schemes.
Coding for Distributed Multi-Agent Reinforcement Learning
Jan 07, 2021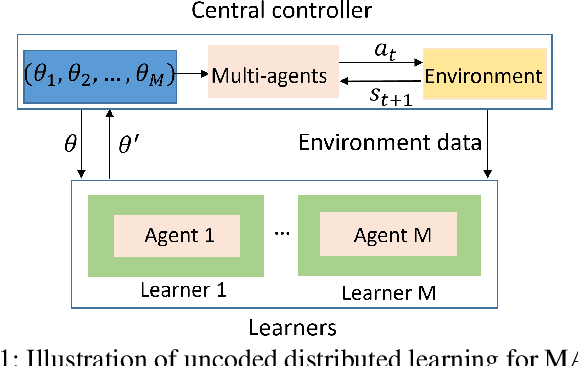
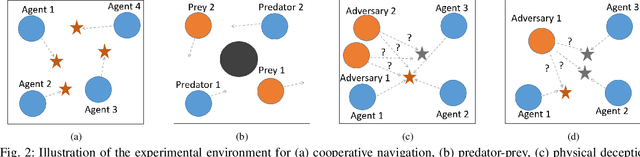
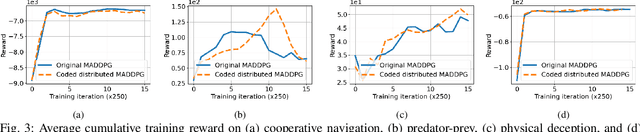

This paper aims to mitigate straggler effects in synchronous distributed learning for multi-agent reinforcement learning (MARL) problems. Stragglers arise frequently in a distributed learning system, due to the existence of various system disturbances such as slow-downs or failures of compute nodes and communication bottlenecks. To resolve this issue, we propose a coded distributed learning framework, which speeds up the training of MARL algorithms in the presence of stragglers, while maintaining the same accuracy as the centralized approach. As an illustration, a coded distributed version of the multi-agent deep deterministic policy gradient(MADDPG) algorithm is developed and evaluated. Different coding schemes, including maximum distance separable (MDS)code, random sparse code, replication-based code, and regular low density parity check (LDPC) code are also investigated. Simulations in several multi-robot problems demonstrate the promising performance of the proposed framework.