 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDARL1N: Distributed multi-Agent Reinforcement Learning with One-hop Neighbors
Feb 18, 2022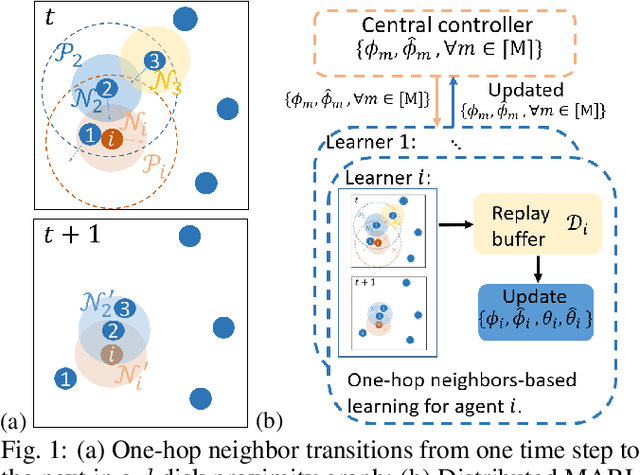

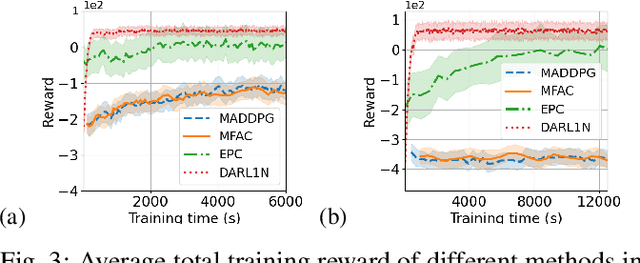
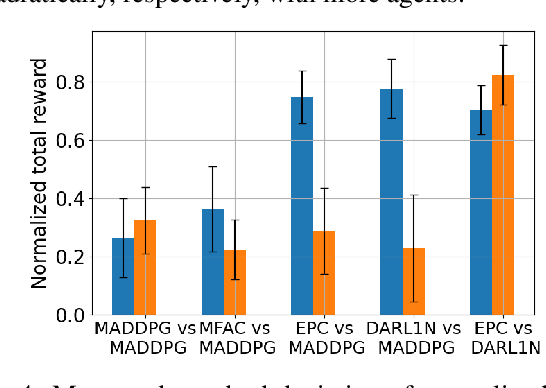
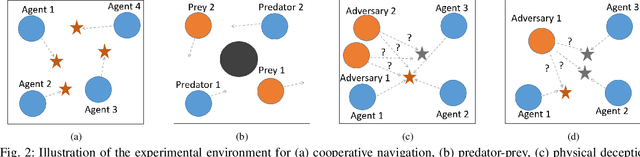
Most existing multi-agent reinforcement learning (MARL) methods are limited in the scale of problems they can handle. Particularly, with the increase of the number of agents, their training costs grow exponentially. In this paper, we address this limitation by introducing a scalable MARL method called Distributed multi-Agent Reinforcement Learning with One-hop Neighbors (DARL1N). DARL1N is an off-policy actor-critic method that breaks the curse of dimensionality by decoupling the global interactions among agents and restricting information exchanges to one-hop neighbors. Each agent optimizes its action value and policy functions over a one-hop neighborhood, significantly reducing the learning complexity, yet maintaining expressiveness by training with varying numbers and states of neighbors. This structure allows us to formulate a distributed learning framework to further speed up the training procedure. Comparisons with state-of-the-art MARL methods show that DARL1N significantly reduces training time without sacrificing policy quality and is scalable as the number of agents increases.
Multi-Agent Reinforcement Learning Based Coded Computation for Mobile Ad Hoc Computing
Apr 15, 2021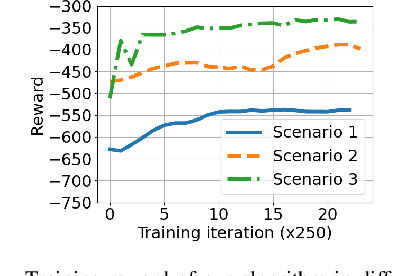
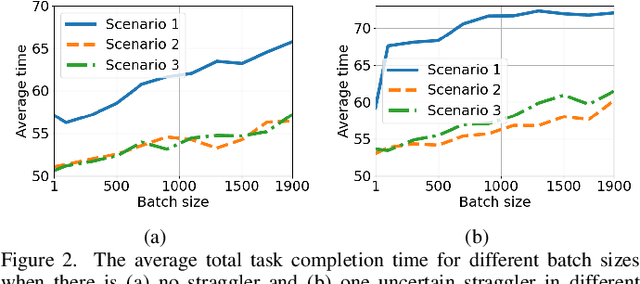
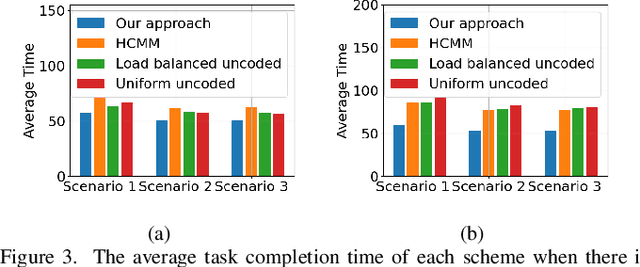
Mobile ad hoc computing (MAHC), which allows mobile devices to directly share their computing resources, is a promising solution to address the growing demands for computing resources required by mobile devices. However, offloading a computation task from a mobile device to other mobile devices is a challenging task due to frequent topology changes and link failures because of node mobility, unstable and unknown communication environments, and the heterogeneous nature of these devices. To address these challenges, in this paper, we introduce a novel coded computation scheme based on multi-agent reinforcement learning (MARL), which has many promising features such as adaptability to network changes, high efficiency and robustness to uncertain system disturbances, consideration of node heterogeneity, and decentralized load allocation. Comprehensive simulation studies demonstrate that the proposed approach can outperform state-of-the-art distributed computing schemes.
Coding for Distributed Multi-Agent Reinforcement Learning
Jan 07, 2021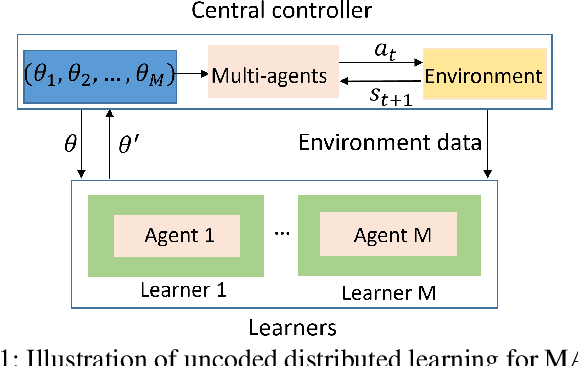
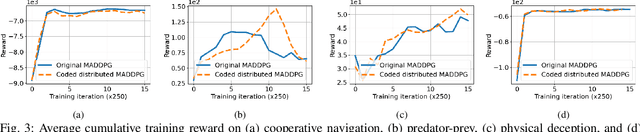

This paper aims to mitigate straggler effects in synchronous distributed learning for multi-agent reinforcement learning (MARL) problems. Stragglers arise frequently in a distributed learning system, due to the existence of various system disturbances such as slow-downs or failures of compute nodes and communication bottlenecks. To resolve this issue, we propose a coded distributed learning framework, which speeds up the training of MARL algorithms in the presence of stragglers, while maintaining the same accuracy as the centralized approach. As an illustration, a coded distributed version of the multi-agent deep deterministic policy gradient(MADDPG) algorithm is developed and evaluated. Different coding schemes, including maximum distance separable (MDS)code, random sparse code, replication-based code, and regular low density parity check (LDPC) code are also investigated. Simulations in several multi-robot problems demonstrate the promising performance of the proposed framework.