 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeERIENet: An Efficient RAW Image Enhancement Network under Low-Light Environment
Dec 17, 2025RAW images have shown superior performance than sRGB images in many image processing tasks, especially for low-light image enhancement. However, most existing methods for RAW-based low-light enhancement usually sequentially process multi-scale information, which makes it difficult to achieve lightweight models and high processing speeds. Besides, they usually ignore the green channel superiority of RAW images, and fail to achieve better reconstruction performance with good use of green channel information. In this work, we propose an efficient RAW Image Enhancement Network (ERIENet), which parallelly processes multi-scale information with efficient convolution modules, and takes advantage of rich information in green channels to guide the reconstruction of images. Firstly, we introduce an efficient multi-scale fully-parallel architecture with a novel channel-aware residual dense block to extract feature maps, which reduces computational costs and achieves real-time processing speed. Secondly, we introduce a green channel guidance branch to exploit the rich information within the green channels of the input RAW image. It increases the quality of reconstruction results with few parameters and computations. Experiments on commonly used low-light image enhancement datasets show that ERIENet outperforms state-of-the-art methods in enhancing low-light RAW images with higher effiency. It also achieves an optimal speed of over 146 frame-per-second (FPS) for 4K-resolution images on a single NVIDIA GeForce RTX 3090 with 24G memory.
Advances in Automated Fetal Brain MRI Segmentation and Biometry: Insights from the FeTA 2024 Challenge
May 05, 2025



Accurate fetal brain tissue segmentation and biometric analysis are essential for studying brain development in utero. The FeTA Challenge 2024 advanced automated fetal brain MRI analysis by introducing biometry prediction as a new task alongside tissue segmentation. For the first time, our diverse multi-centric test set included data from a new low-field (0.55T) MRI dataset. Evaluation metrics were also expanded to include the topology-specific Euler characteristic difference (ED). Sixteen teams submitted segmentation methods, most of which performed consistently across both high- and low-field scans. However, longitudinal trends indicate that segmentation accuracy may be reaching a plateau, with results now approaching inter-rater variability. The ED metric uncovered topological differences that were missed by conventional metrics, while the low-field dataset achieved the highest segmentation scores, highlighting the potential of affordable imaging systems when paired with high-quality reconstruction. Seven teams participated in the biometry task, but most methods failed to outperform a simple baseline that predicted measurements based solely on gestational age, underscoring the challenge of extracting reliable biometric estimates from image data alone. Domain shift analysis identified image quality as the most significant factor affecting model generalization, with super-resolution pipelines also playing a substantial role. Other factors, such as gestational age, pathology, and acquisition site, had smaller, though still measurable, effects. Overall, FeTA 2024 offers a comprehensive benchmark for multi-class segmentation and biometry estimation in fetal brain MRI, underscoring the need for data-centric approaches, improved topological evaluation, and greater dataset diversity to enable clinically robust and generalizable AI tools.
Towards Effective Top-N Hamming Search via Bipartite Graph Contrastive Hashing
Aug 17, 2024



Searching on bipartite graphs serves as a fundamental task for various real-world applications, such as recommendation systems, database retrieval, and document querying. Conventional approaches rely on similarity matching in continuous Euclidean space of vectorized node embeddings. To handle intensive similarity computation efficiently, hashing techniques for graph-structured data have emerged as a prominent research direction. However, despite the retrieval efficiency in Hamming space, previous studies have encountered catastrophic performance decay. To address this challenge, we investigate the problem of hashing with Graph Convolutional Network for effective Top-N search. Our findings indicate the learning effectiveness of incorporating hashing techniques within the exploration of bipartite graph reception fields, as opposed to simply treating hashing as post-processing to output embeddings. To further enhance the model performance, we advance upon these findings and propose Bipartite Graph Contrastive Hashing (BGCH+). BGCH+ introduces a novel dual augmentation approach to both intermediate information and hash code outputs in the latent feature spaces, thereby producing more expressive and robust hash codes within a dual self-supervised learning paradigm. Comprehensive empirical analyses on six real-world benchmarks validate the effectiveness of our dual feature contrastive learning in boosting the performance of BGCH+ compared to existing approaches.
Improving Chinese Character Representation with Formation Tree
Apr 19, 2024Learning effective representations for Chinese characters presents unique challenges, primarily due to the vast number of characters and their continuous growth, which requires models to handle an expanding category space. Additionally, the inherent sparsity of character usage complicates the generalization of learned representations. Prior research has explored radical-based sequences to overcome these issues, achieving progress in recognizing unseen characters. However, these approaches fail to fully exploit the inherent tree structure of such sequences. To address these limitations and leverage established data properties, we propose Formation Tree-CLIP (FT-CLIP). This model utilizes formation trees to represent characters and incorporates a dedicated tree encoder, significantly improving performance in both seen and unseen character recognition tasks. We further introduce masking for to both character images and tree nodes, enabling efficient and effective training. This approach accelerates training significantly (by a factor of 2 or more) while enhancing accuracy. Extensive experiments show that processing characters through formation trees aligns better with their inherent properties than direct sequential methods, significantly enhancing the generality and usability of the representations.
Practitioners' Challenges and Perceptions of CI Build Failure Predictions at Atlassian
Feb 15, 2024



Continuous Integration (CI) build failures could significantly impact the software development process and teams, such as delaying the release of new features and reducing developers' productivity. In this work, we report on an empirical study that investigates CI build failures throughout product development at Atlassian. Our quantitative analysis found that the repository dimension is the key factor influencing CI build failures. In addition, our qualitative survey revealed that Atlassian developers perceive CI build failures as challenging issues in practice. Furthermore, we found that the CI build prediction can not only provide proactive insight into CI build failures but also facilitate the team's decision-making. Our study sheds light on the challenges and expectations involved in integrating CI build prediction tools into the Bitbucket environment, providing valuable insights for enhancing CI processes.
LLM-Twin: Mini-Giant Model-driven Beyond 5G Digital Twin Networking Framework with Semantic Secure Communication and Computation
Dec 17, 2023Beyond 5G networks provide solutions for next-generation communications, especially digital twins networks (DTNs) have gained increasing popularity for bridging physical space and digital space. However, current DTNs networking frameworks pose a number of challenges especially when applied in scenarios that require high communication efficiency and multimodal data processing. First, current DTNs frameworks are unavoidable regarding high resource consumption and communication congestion because of original bit-level communication and high-frequency computation, especially distributed learning-based DTNs. Second, current machine learning models for DTNs are domain-specific (e.g. E-health), making it difficult to handle DT scenarios with multimodal data processing requirements. Last but not least, current security schemes for DTNs, such as blockchain, introduce additional overheads that impair the efficiency of DTNs. To address the above challenges, we propose a large language model (LLM) empowered DTNs networking framework, LLM-Twin. First, we design the mini-giant model collaboration scheme to achieve efficient deployment of LLM in DTNs, since LLM are naturally conducive to processing multimodal data. Then, we design a semantic-level high-efficiency, and secure communication model for DTNs. The feasibility of LLM-Twin is demonstrated by numerical experiments and case studies. To our knowledge, this is the first to propose LLM-based semantic-level digital twin networking framework.
MetaHead: An Engine to Create Realistic Digital Head
Apr 03, 2023



Collecting and labeling training data is one important step for learning-based methods because the process is time-consuming and biased. For face analysis tasks, although some generative models can be used to generate face data, they can only achieve a subset of generation diversity, reconstruction accuracy, 3D consistency, high-fidelity visual quality, and easy editability. One recent related work is the graphics-based generative method, but it can only render low realism head with high computation cost. In this paper, we propose MetaHead, a unified and full-featured controllable digital head engine, which consists of a controllable head radiance field(MetaHead-F) to super-realistically generate or reconstruct view-consistent 3D controllable digital heads and a generic top-down image generation framework LabelHead to generate digital heads consistent with the given customizable feature labels. Experiments validate that our controllable digital head engine achieves the state-of-the-art generation visual quality and reconstruction accuracy. Moreover, the generated labeled data can assist real training data and significantly surpass the labeled data generated by graphics-based methods in terms of training effect.
Reconstructing Personalized Semantic Facial NeRF Models From Monocular Video
Oct 12, 2022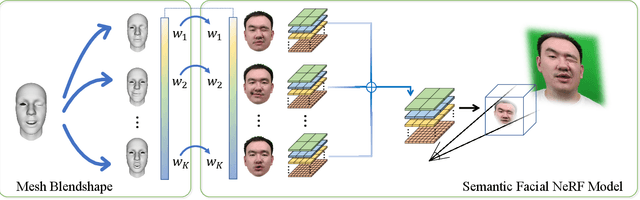

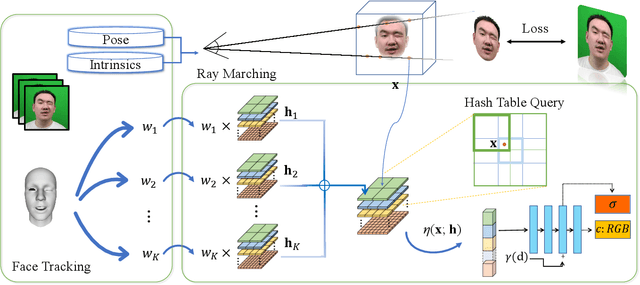
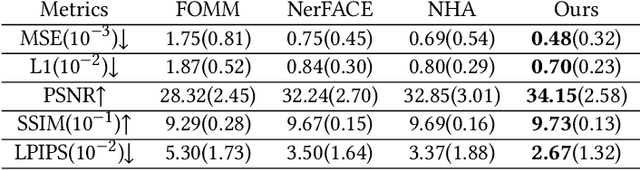
We present a novel semantic model for human head defined with neural radiance field. The 3D-consistent head model consist of a set of disentangled and interpretable bases, and can be driven by low-dimensional expression coefficients. Thanks to the powerful representation ability of neural radiance field, the constructed model can represent complex facial attributes including hair, wearings, which can not be represented by traditional mesh blendshape. To construct the personalized semantic facial model, we propose to define the bases as several multi-level voxel fields. With a short monocular RGB video as input, our method can construct the subject's semantic facial NeRF model with only ten to twenty minutes, and can render a photo-realistic human head image in tens of miliseconds with a given expression coefficient and view direction. With this novel representation, we apply it to many tasks like facial retargeting and expression editing. Experimental results demonstrate its strong representation ability and training/inference speed. Demo videos and released code are provided in our project page: https://ustc3dv.github.io/NeRFBlendShape/
* Accepted by SIGGRAPH Asia 2022 (Journal Track). Project page: https://ustc3dv.github.io/NeRFBlendShape/
SelfRecon: Self Reconstruction Your Digital Avatar from Monocular Video
Jan 30, 2022



We propose SelfRecon, a clothed human body reconstruction method that combines implicit and explicit representations to recover space-time coherent geometries from a monocular self-rotating human video. Explicit methods require a predefined template mesh for a given sequence, while the template is hard to acquire for a specific subject. Meanwhile, the fixed topology limits the reconstruction accuracy and clothing types. Implicit methods support arbitrary topology and have high quality due to continuous geometric representation. However, it is difficult to integrate multi-frame information to produce a consistent registration sequence for downstream applications. We propose to combine the advantages of both representations. We utilize differential mask loss of the explicit mesh to obtain the coherent overall shape, while the details on the implicit surface are refined with the differentiable neural rendering. Meanwhile, the explicit mesh is updated periodically to adjust its topology changes, and a consistency loss is designed to match both representations closely. Compared with existing methods, SelfRecon can produce high-fidelity surfaces for arbitrary clothed humans with self-supervised optimization. Extensive experimental results demonstrate its effectiveness on real captured monocular videos.
HeadNeRF: A Real-time NeRF-based Parametric Head Model
Dec 13, 2021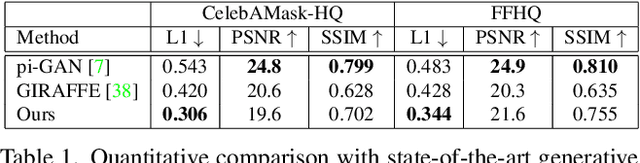
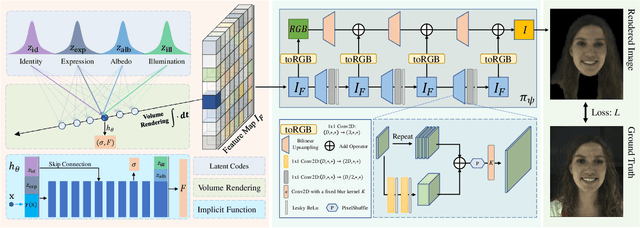


In this paper, we propose HeadNeRF, a novel NeRF-based parametric head model that integrates the neural radiance field to the parametric representation of the human head. It can render high fidelity head images in real-time, and supports directly controlling the generated images' rendering pose and various semantic attributes. Different from existing related parametric models, we use the neural radiance fields as a novel 3D proxy instead of the traditional 3D textured mesh, which makes that HeadNeRF is able to generate high fidelity images. However, the computationally expensive rendering process of the original NeRF hinders the construction of the parametric NeRF model. To address this issue, we adopt the strategy of integrating 2D neural rendering to the rendering process of NeRF and design novel loss terms. As a result, the rendering speed of HeadNeRF can be significantly accelerated, and the rendering time of one frame is reduced from 5s to 25ms. The novel-designed loss terms also improve the rendering accuracy, and the fine-level details of the human head, such as the gaps between teeth, wrinkles, and beards, can be represented and synthesized by HeadNeRF. Extensive experimental results and several applications demonstrate its effectiveness. We will release the code and trained model to the public.