 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCosAvatar: Consistent and Animatable Portrait Video Tuning with Text Prompt
Nov 30, 2023Recently, text-guided digital portrait editing has attracted more and more attentions. However, existing methods still struggle to maintain consistency across time, expression, and view or require specific data prerequisites. To solve these challenging problems, we propose CosAvatar, a high-quality and user-friendly framework for portrait tuning. With only monocular video and text instructions as input, we can produce animatable portraits with both temporal and 3D consistency. Different from methods that directly edit in the 2D domain, we employ a dynamic NeRF-based 3D portrait representation to model both the head and torso. We alternate between editing the video frames' dataset and updating the underlying 3D portrait until the edited frames reach 3D consistency. Additionally, we integrate the semantic portrait priors to enhance the edited results, allowing precise modifications in specified semantic areas. Extensive results demonstrate that our proposed method can not only accurately edit portrait styles or local attributes based on text instructions but also support expressive animation driven by a source video.
HeadNeRF: A Real-time NeRF-based Parametric Head Model
Dec 13, 2021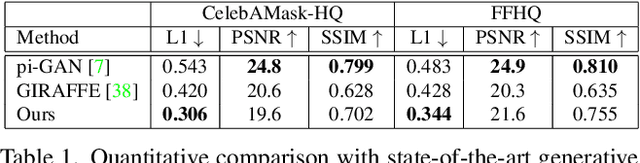
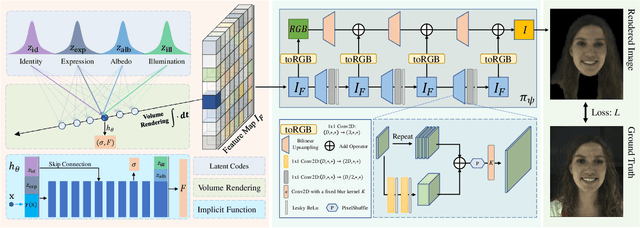


In this paper, we propose HeadNeRF, a novel NeRF-based parametric head model that integrates the neural radiance field to the parametric representation of the human head. It can render high fidelity head images in real-time, and supports directly controlling the generated images' rendering pose and various semantic attributes. Different from existing related parametric models, we use the neural radiance fields as a novel 3D proxy instead of the traditional 3D textured mesh, which makes that HeadNeRF is able to generate high fidelity images. However, the computationally expensive rendering process of the original NeRF hinders the construction of the parametric NeRF model. To address this issue, we adopt the strategy of integrating 2D neural rendering to the rendering process of NeRF and design novel loss terms. As a result, the rendering speed of HeadNeRF can be significantly accelerated, and the rendering time of one frame is reduced from 5s to 25ms. The novel-designed loss terms also improve the rendering accuracy, and the fine-level details of the human head, such as the gaps between teeth, wrinkles, and beards, can be represented and synthesized by HeadNeRF. Extensive experimental results and several applications demonstrate its effectiveness. We will release the code and trained model to the public.