 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGSwap: Realistic Head Swapping with Dynamic Neural Gaussian Field
Mar 24, 2026We present GSwap, a novel consistent and realistic video head-swapping system empowered by dynamic neural Gaussian portrait priors, which significantly advances the state of the art in face and head replacement. Unlike previous methods that rely primarily on 2D generative models or 3D Morphable Face Models (3DMM), our approach overcomes their inherent limitations, including poor 3D consistency, unnatural facial expressions, and restricted synthesis quality. Moreover, existing techniques struggle with full head-swapping tasks due to insufficient holistic head modeling and ineffective background blending, often resulting in visible artifacts and misalignments. To address these challenges, GSwap introduces an intrinsic 3D Gaussian feature field embedded within a full-body SMPL-X surface, effectively elevating 2D portrait videos into a dynamic neural Gaussian field. This innovation ensures high-fidelity, 3D-consistent portrait rendering while preserving natural head-torso relationships and seamless motion dynamics. To facilitate training, we adapt a pretrained 2D portrait generative model to the source head domain using only a few reference images, enabling efficient domain adaptation. Furthermore, we propose a neural re-rendering strategy that harmoniously integrates the synthesized foreground with the original background, eliminating blending artifacts and enhancing realism. Extensive experiments demonstrate that GSwap surpasses existing methods in multiple aspects, including visual quality, temporal coherence, identity preservation, and 3D consistency.
Easy3E: Feed-Forward 3D Asset Editing via Rectified Voxel Flow
Feb 25, 2026Existing 3D editing methods rely on computationally intensive scene-by-scene iterative optimization and suffer from multi-view inconsistency. We propose an effective and fully feedforward 3D editing framework based on the TRELLIS generative backbone, capable of modifying 3D models from a single editing view. Our framework addresses two key issues: adapting training-free 2D editing to structured 3D representations, and overcoming the bottleneck of appearance fidelity in compressed 3D features. To ensure geometric consistency, we introduce Voxel FlowEdit, an edit-driven flow in the sparse voxel latent space that achieves globally consistent 3D deformation in a single pass. To restore high-fidelity details, we develop a normal-guided single to multi-view generation module as an external appearance prior, successfully recovering high-frequency textures. Experiments demonstrate that our method enables fast, globally consistent, and high-fidelity 3D model editing.
ExpPortrait: Expressive Portrait Generation via Personalized Representation
Feb 23, 2026While diffusion models have shown great potential in portrait generation, generating expressive, coherent, and controllable cinematic portrait videos remains a significant challenge. Existing intermediate signals for portrait generation, such as 2D landmarks and parametric models, have limited disentanglement capabilities and cannot express personalized details due to their sparse or low-rank representation. Therefore, existing methods based on these models struggle to accurately preserve subject identity and expressions, hindering the generation of highly expressive portrait videos. To overcome these limitations, we propose a high-fidelity personalized head representation that more effectively disentangles expression and identity. This representation captures both static, subject-specific global geometry and dynamic, expression-related details. Furthermore, we introduce an expression transfer module to achieve personalized transfer of head pose and expression details between different identities. We use this sophisticated and highly expressive head model as a conditional signal to train a diffusion transformer (DiT)-based generator to synthesize richly detailed portrait videos. Extensive experiments on self- and cross-reenactment tasks demonstrate that our method outperforms previous models in terms of identity preservation, expression accuracy, and temporal stability, particularly in capturing fine-grained details of complex motion.
One Shot, One Talk: Whole-body Talking Avatar from a Single Image
Dec 02, 2024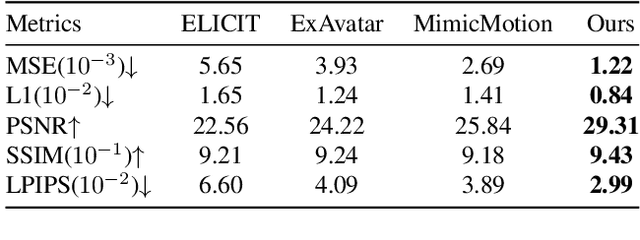
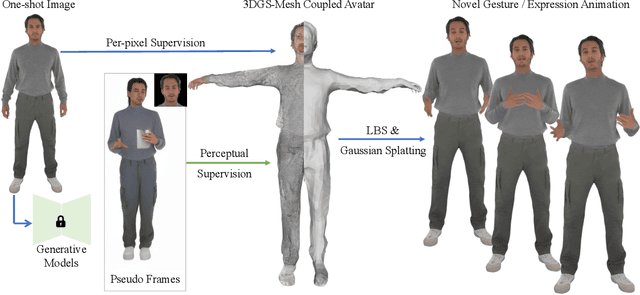
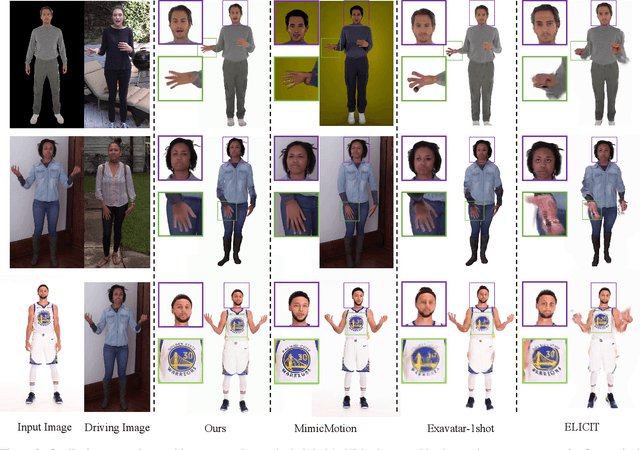

Building realistic and animatable avatars still requires minutes of multi-view or monocular self-rotating videos, and most methods lack precise control over gestures and expressions. To push this boundary, we address the challenge of constructing a whole-body talking avatar from a single image. We propose a novel pipeline that tackles two critical issues: 1) complex dynamic modeling and 2) generalization to novel gestures and expressions. To achieve seamless generalization, we leverage recent pose-guided image-to-video diffusion models to generate imperfect video frames as pseudo-labels. To overcome the dynamic modeling challenge posed by inconsistent and noisy pseudo-videos, we introduce a tightly coupled 3DGS-mesh hybrid avatar representation and apply several key regularizations to mitigate inconsistencies caused by imperfect labels. Extensive experiments on diverse subjects demonstrate that our method enables the creation of a photorealistic, precisely animatable, and expressive whole-body talking avatar from just a single image.
PICA: Physics-Integrated Clothed Avatar
Jul 07, 2024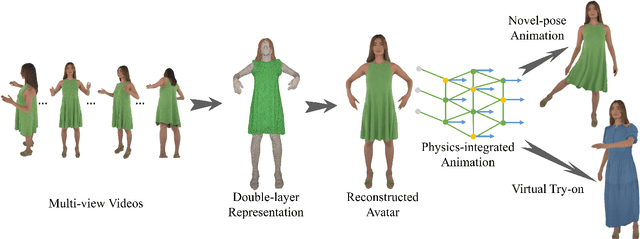
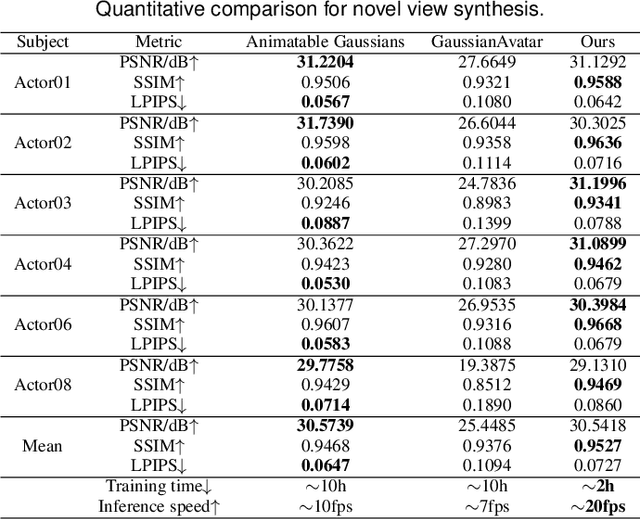
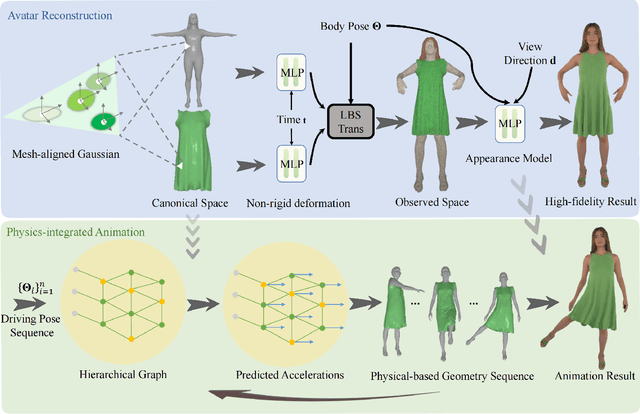
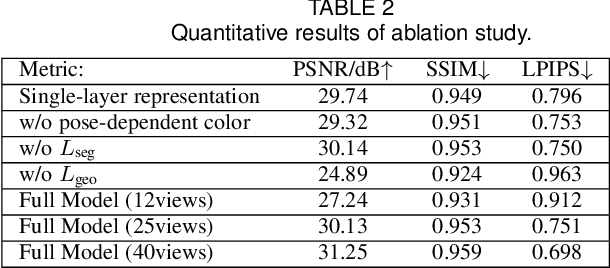
We introduce PICA, a novel representation for high-fidelity animatable clothed human avatars with physics-accurate dynamics, even for loose clothing. Previous neural rendering-based representations of animatable clothed humans typically employ a single model to represent both the clothing and the underlying body. While efficient, these approaches often fail to accurately represent complex garment dynamics, leading to incorrect deformations and noticeable rendering artifacts, especially for sliding or loose garments. Furthermore, previous works represent garment dynamics as pose-dependent deformations and facilitate novel pose animations in a data-driven manner. This often results in outcomes that do not faithfully represent the mechanics of motion and are prone to generating artifacts in out-of-distribution poses. To address these issues, we adopt two individual 3D Gaussian Splatting (3DGS) models with different deformation characteristics, modeling the human body and clothing separately. This distinction allows for better handling of their respective motion characteristics. With this representation, we integrate a graph neural network (GNN)-based clothed body physics simulation module to ensure an accurate representation of clothing dynamics. Our method, through its carefully designed features, achieves high-fidelity rendering of clothed human bodies in complex and novel driving poses, significantly outperforming previous methods under the same settings.
FlashAvatar: High-Fidelity Digital Avatar Rendering at 300FPS
Dec 03, 2023We propose FlashAvatar, a novel and lightweight 3D animatable avatar representation that could reconstruct a digital avatar from a short monocular video sequence in minutes and render high-fidelity photo-realistic images at 300FPS on a consumer-grade GPU. To achieve this, we maintain a uniform 3D Gaussian field embedded in the surface of a parametric face model and learn extra spatial offset to model non-surface regions and subtle facial details. While full use of geometric priors can capture high-frequency facial details and preserve exaggerated expressions, proper initialization can help reduce the number of Gaussians, thus enabling super-fast rendering speed. Extensive experimental results demonstrate that FlashAvatar outperforms existing works regarding visual quality and personalized details and is almost an order of magnitude faster in rendering speed. Project page: https://ustc3dv.github.io/FlashAvatar/
CosAvatar: Consistent and Animatable Portrait Video Tuning with Text Prompt
Nov 30, 2023Recently, text-guided digital portrait editing has attracted more and more attentions. However, existing methods still struggle to maintain consistency across time, expression, and view or require specific data prerequisites. To solve these challenging problems, we propose CosAvatar, a high-quality and user-friendly framework for portrait tuning. With only monocular video and text instructions as input, we can produce animatable portraits with both temporal and 3D consistency. Different from methods that directly edit in the 2D domain, we employ a dynamic NeRF-based 3D portrait representation to model both the head and torso. We alternate between editing the video frames' dataset and updating the underlying 3D portrait until the edited frames reach 3D consistency. Additionally, we integrate the semantic portrait priors to enhance the edited results, allowing precise modifications in specified semantic areas. Extensive results demonstrate that our proposed method can not only accurately edit portrait styles or local attributes based on text instructions but also support expressive animation driven by a source video.
MetaHead: An Engine to Create Realistic Digital Head
Apr 03, 2023



Collecting and labeling training data is one important step for learning-based methods because the process is time-consuming and biased. For face analysis tasks, although some generative models can be used to generate face data, they can only achieve a subset of generation diversity, reconstruction accuracy, 3D consistency, high-fidelity visual quality, and easy editability. One recent related work is the graphics-based generative method, but it can only render low realism head with high computation cost. In this paper, we propose MetaHead, a unified and full-featured controllable digital head engine, which consists of a controllable head radiance field(MetaHead-F) to super-realistically generate or reconstruct view-consistent 3D controllable digital heads and a generic top-down image generation framework LabelHead to generate digital heads consistent with the given customizable feature labels. Experiments validate that our controllable digital head engine achieves the state-of-the-art generation visual quality and reconstruction accuracy. Moreover, the generated labeled data can assist real training data and significantly surpass the labeled data generated by graphics-based methods in terms of training effect.
Reconstructing Personalized Semantic Facial NeRF Models From Monocular Video
Oct 12, 2022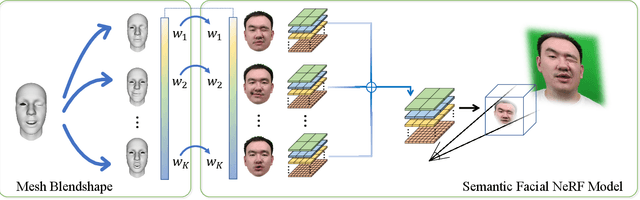

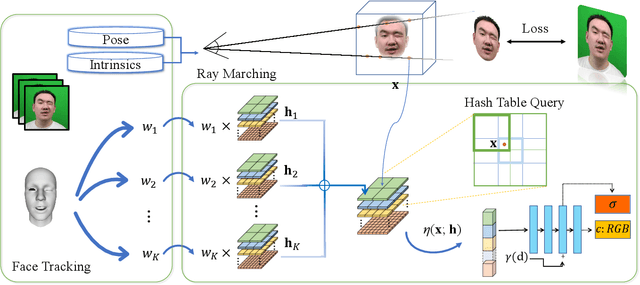
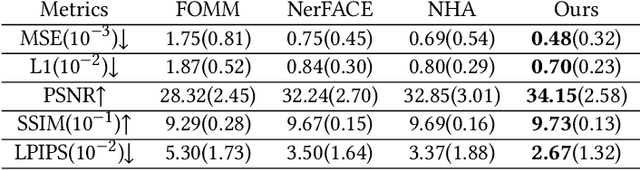
We present a novel semantic model for human head defined with neural radiance field. The 3D-consistent head model consist of a set of disentangled and interpretable bases, and can be driven by low-dimensional expression coefficients. Thanks to the powerful representation ability of neural radiance field, the constructed model can represent complex facial attributes including hair, wearings, which can not be represented by traditional mesh blendshape. To construct the personalized semantic facial model, we propose to define the bases as several multi-level voxel fields. With a short monocular RGB video as input, our method can construct the subject's semantic facial NeRF model with only ten to twenty minutes, and can render a photo-realistic human head image in tens of miliseconds with a given expression coefficient and view direction. With this novel representation, we apply it to many tasks like facial retargeting and expression editing. Experimental results demonstrate its strong representation ability and training/inference speed. Demo videos and released code are provided in our project page: https://ustc3dv.github.io/NeRFBlendShape/
* Accepted by SIGGRAPH Asia 2022 (Journal Track). Project page: https://ustc3dv.github.io/NeRFBlendShape/
Prior-Guided Multi-View 3D Head Reconstruction
Jul 09, 2021



Recovering a 3D head model including the complete face and hair regions is still a challenging problem in computer vision and graphics. In this paper, we consider this problem with a few multi-view portrait images as input. Previous multi-view stereo methods, either based on the optimization strategies or deep learning techniques, suffer from low-frequency geometric structures such as unclear head structures and inaccurate reconstruction in hair regions. To tackle this problem, we propose a prior-guided implicit neural rendering network. Specifically, we model the head geometry with a learnable signed distance field (SDF) and optimize it via an implicit differentiable renderer with the guidance of some human head priors, including the facial prior knowledge, head semantic segmentation information and 2D hair orientation maps. The utilization of these priors can improve the reconstruction accuracy and robustness, leading to a high-quality integrated 3D head model. Extensive ablation studies and comparisons with state-of-the-art methods demonstrate that our method could produce high-fidelity 3D head geometries with the guidance of these priors.