 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne Shot, One Talk: Whole-body Talking Avatar from a Single Image
Dec 02, 2024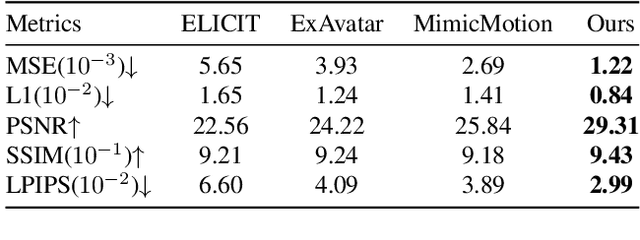
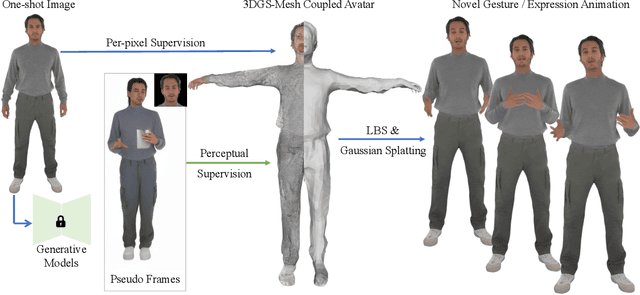
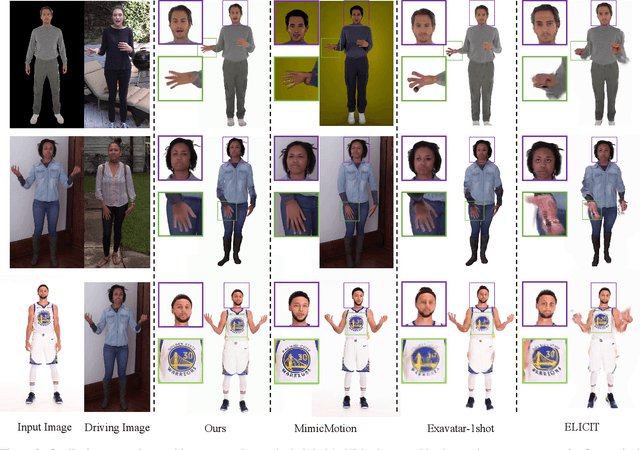

Building realistic and animatable avatars still requires minutes of multi-view or monocular self-rotating videos, and most methods lack precise control over gestures and expressions. To push this boundary, we address the challenge of constructing a whole-body talking avatar from a single image. We propose a novel pipeline that tackles two critical issues: 1) complex dynamic modeling and 2) generalization to novel gestures and expressions. To achieve seamless generalization, we leverage recent pose-guided image-to-video diffusion models to generate imperfect video frames as pseudo-labels. To overcome the dynamic modeling challenge posed by inconsistent and noisy pseudo-videos, we introduce a tightly coupled 3DGS-mesh hybrid avatar representation and apply several key regularizations to mitigate inconsistencies caused by imperfect labels. Extensive experiments on diverse subjects demonstrate that our method enables the creation of a photorealistic, precisely animatable, and expressive whole-body talking avatar from just a single image.