 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMatrix-Game 3.0: Real-Time and Streaming Interactive World Model with Long-Horizon Memory
Apr 13, 2026With the advancement of interactive video generation, diffusion models have increasingly demonstrated their potential as world models. However, existing approaches still struggle to simultaneously achieve memory-enabled long-term temporal consistency and high-resolution real-time generation, limiting their applicability in real-world scenarios. To address this, we present Matrix-Game 3.0, a memory-augmented interactive world model designed for 720p real-time longform video generation. Building upon Matrix-Game 2.0, we introduce systematic improvements across data, model, and inference. First, we develop an upgraded industrial-scale infinite data engine that integrates Unreal Engine-based synthetic data, large-scale automated collection from AAA games, and real-world video augmentation to produce high-quality Video-Pose-Action-Prompt quadruplet data at scale. Second, we propose a training framework for long-horizon consistency: by modeling prediction residuals and re-injecting imperfect generated frames during training, the base model learns self-correction; meanwhile, camera-aware memory retrieval and injection enable the base model to achieve long horizon spatiotemporal consistency. Third, we design a multi-segment autoregressive distillation strategy based on Distribution Matching Distillation (DMD), combined with model quantization and VAE decoder pruning, to achieve efficient real-time inference. Experimental results show that Matrix-Game 3.0 achieves up to 40 FPS real-time generation at 720p resolution with a 5B model, while maintaining stable memory consistency over minute-long sequences. Scaling up to a 2x14B model further improves generation quality, dynamics, and generalization. Our approach provides a practical pathway toward industrial-scale deployable world models.
Skywork UniPic 2.0: Building Kontext Model with Online RL for Unified Multimodal Model
Sep 04, 2025

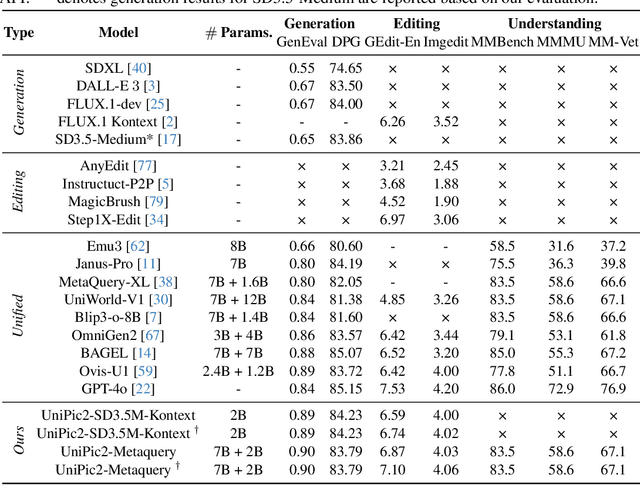
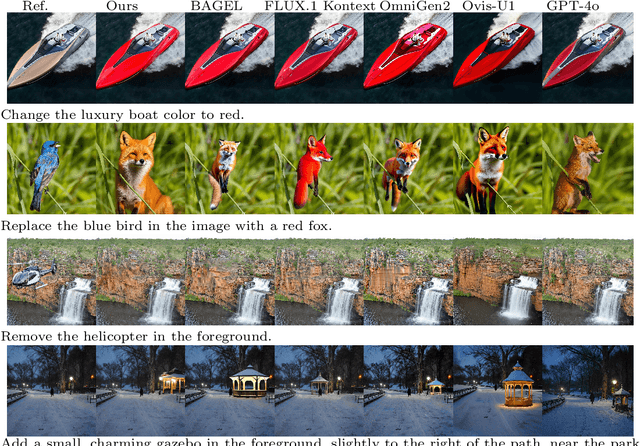
Recent advances in multimodal models have demonstrated impressive capabilities in unified image generation and editing. However, many prominent open-source models prioritize scaling model parameters over optimizing training strategies, limiting their efficiency and performance. In this work, we present UniPic2-SD3.5M-Kontext, a 2B-parameter DiT model based on SD3.5-Medium, which achieves state-of-the-art image generation and editing while extending seamlessly into a unified multimodal framework. Our approach begins with architectural modifications to SD3.5-Medium and large-scale pre-training on high-quality data, enabling joint text-to-image generation and editing capabilities. To enhance instruction following and editing consistency, we propose a novel Progressive Dual-Task Reinforcement strategy (PDTR), which effectively strengthens both tasks in a staged manner. We empirically validate that the reinforcement phases for different tasks are mutually beneficial and do not induce negative interference. After pre-training and reinforcement strategies, UniPic2-SD3.5M-Kontext demonstrates stronger image generation and editing capabilities than models with significantly larger generation parameters-including BAGEL (7B) and Flux-Kontext (12B). Furthermore, following the MetaQuery, we connect the UniPic2-SD3.5M-Kontext and Qwen2.5-VL-7B via a connector and perform joint training to launch a unified multimodal model UniPic2-Metaquery. UniPic2-Metaquery integrates understanding, generation, and editing, achieving top-tier performance across diverse tasks with a simple and scalable training paradigm. This consistently validates the effectiveness and generalizability of our proposed training paradigm, which we formalize as Skywork UniPic 2.0.
Animatable Neural Implicit Surfaces for Creating Avatars from Videos
Mar 15, 2022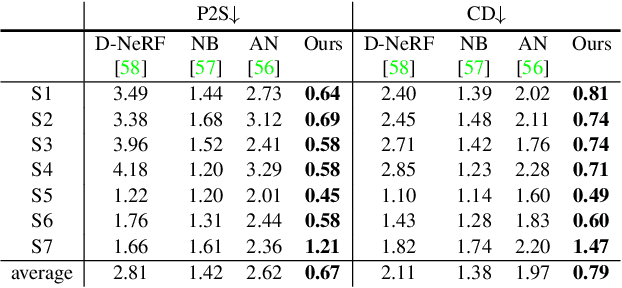
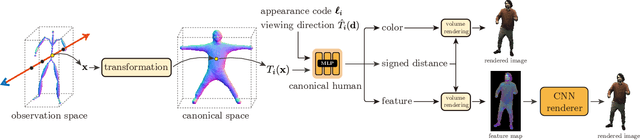
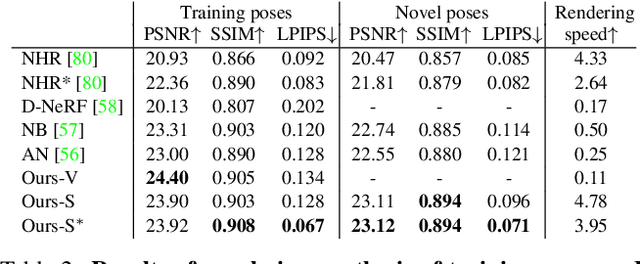
This paper aims to reconstruct an animatable human model from a video of very sparse camera views. Some recent works represent human geometry and appearance with neural radiance fields and utilize parametric human models to produce deformation fields for animation, which enables them to recover detailed 3D human models from videos. However, their reconstruction results tend to be noisy due to the lack of surface constraints on radiance fields. Moreover, as they generate the human appearance in 3D space, their rendering quality heavily depends on the accuracy of deformation fields. To solve these problems, we propose Animatable Neural Implicit Surface (AniSDF), which models the human geometry with a signed distance field and defers the appearance generation to the 2D image space with a 2D neural renderer. The signed distance field naturally regularizes the learned geometry, enabling the high-quality reconstruction of human bodies, which can be further used to improve the rendering speed. Moreover, the 2D neural renderer can be learned to compensate for geometric errors, making the rendering more robust to inaccurate deformations. Experiments on several datasets show that the proposed approach outperforms recent human reconstruction and synthesis methods by a large margin.
SelfRecon: Self Reconstruction Your Digital Avatar from Monocular Video
Jan 30, 2022



We propose SelfRecon, a clothed human body reconstruction method that combines implicit and explicit representations to recover space-time coherent geometries from a monocular self-rotating human video. Explicit methods require a predefined template mesh for a given sequence, while the template is hard to acquire for a specific subject. Meanwhile, the fixed topology limits the reconstruction accuracy and clothing types. Implicit methods support arbitrary topology and have high quality due to continuous geometric representation. However, it is difficult to integrate multi-frame information to produce a consistent registration sequence for downstream applications. We propose to combine the advantages of both representations. We utilize differential mask loss of the explicit mesh to obtain the coherent overall shape, while the details on the implicit surface are refined with the differentiable neural rendering. Meanwhile, the explicit mesh is updated periodically to adjust its topology changes, and a consistency loss is designed to match both representations closely. Compared with existing methods, SelfRecon can produce high-fidelity surfaces for arbitrary clothed humans with self-supervised optimization. Extensive experimental results demonstrate its effectiveness on real captured monocular videos.
StereoPIFu: Depth Aware Clothed Human Digitization via Stereo Vision
Apr 13, 2021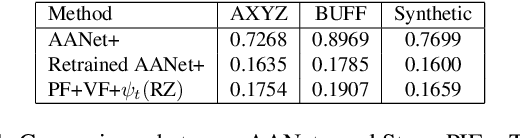
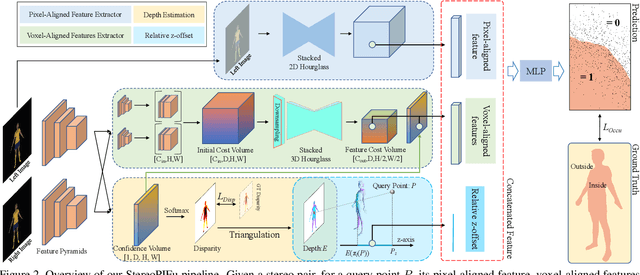
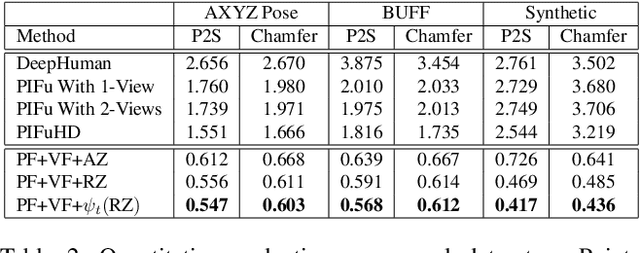
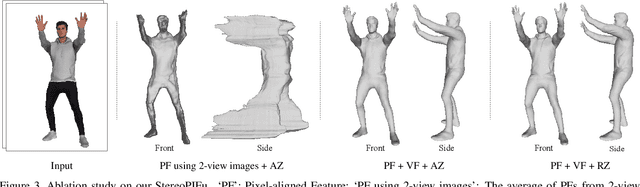
In this paper, we propose StereoPIFu, which integrates the geometric constraints of stereo vision with implicit function representation of PIFu, to recover the 3D shape of the clothed human from a pair of low-cost rectified images. First, we introduce the effective voxel-aligned features from a stereo vision-based network to enable depth-aware reconstruction. Moreover, the novel relative z-offset is employed to associate predicted high-fidelity human depth and occupancy inference, which helps restore fine-level surface details. Second, a network structure that fully utilizes the geometry information from the stereo images is designed to improve the human body reconstruction quality. Consequently, our StereoPIFu can naturally infer the human body's spatial location in camera space and maintain the correct relative position of different parts of the human body, which enables our method to capture human performance. Compared with previous works, our StereoPIFu significantly improves the robustness, completeness, and accuracy of the clothed human reconstruction, which is demonstrated by extensive experimental results.
BCNet: Learning Body and Cloth Shape from A Single Image
Apr 01, 2020



In this paper, we consider the problem to automatically reconstruct both garment and body shapes from a single near front view RGB image. To this end, we propose a layered garment representation on top of SMPL and novelly make the skinning weight of garment to be independent with the body mesh, which significantly improves the expression ability of our garment model. Compared with existing methods, our method can support more garment categories like skirts and recover more accurate garment geometry. To train our model, we construct two large scale datasets with ground truth body and garment geometries as well as paired color images. Compared with single mesh or non-parametric representation, our method can achieve more flexible control with separate meshes, makes applications like re-pose, garment transfer, and garment texture mapping possible.
Learning 3D Human Body Embedding
May 14, 2019



Although human body shapes vary for different identities with different poses, they can be embedded into a low-dimensional space due to their similarity in structure. Inspired by the recent work on latent representation learning with a deformation-based mesh representation, we propose an autoencoder like network architecture to learn disentangled shape and pose embedding specifically for 3D human body. We also integrate a coarse-to-fine reconstruction pipeline into the disentangling process to improve the reconstruction accuracy. Moreover, we construct a large dataset of human body models with consistent topology for the learning of neural network. Our learned embedding can achieve not only superior reconstruction accuracy but also provide great flexibilities in 3D human body creations via interpolation, bilateral interpolation and latent space sampling, which is confirmed by extensive experiments. The constructed dataset and trained model will be made publicly available.
CNN-based Real-time Dense Face Reconstruction with Inverse-rendered Photo-realistic Face Images
May 15, 2018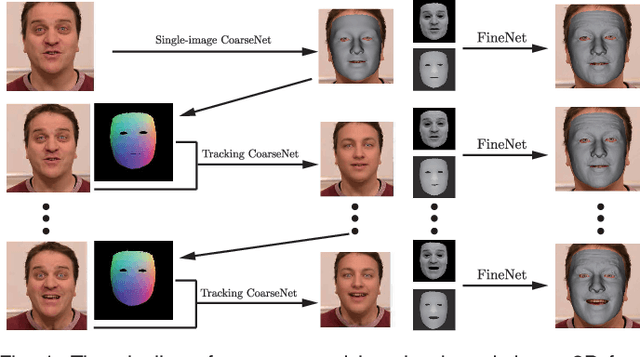
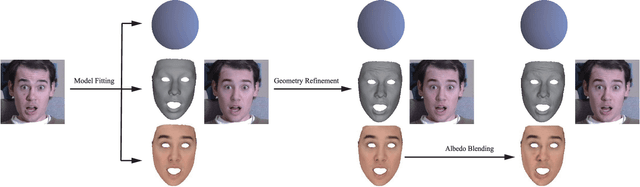

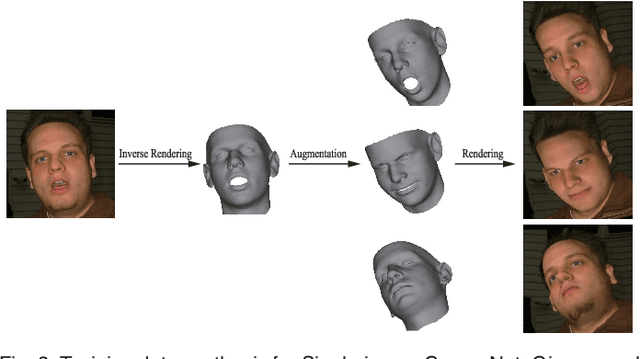
With the powerfulness of convolution neural networks (CNN), CNN based face reconstruction has recently shown promising performance in reconstructing detailed face shape from 2D face images. The success of CNN-based methods relies on a large number of labeled data. The state-of-the-art synthesizes such data using a coarse morphable face model, which however has difficulty to generate detailed photo-realistic images of faces (with wrinkles). This paper presents a novel face data generation method. Specifically, we render a large number of photo-realistic face images with different attributes based on inverse rendering. Furthermore, we construct a fine-detailed face image dataset by transferring different scales of details from one image to another. We also construct a large number of video-type adjacent frame pairs by simulating the distribution of real video data. With these nicely constructed datasets, we propose a coarse-to-fine learning framework consisting of three convolutional networks. The networks are trained for real-time detailed 3D face reconstruction from monocular video as well as from a single image. Extensive experimental results demonstrate that our framework can produce high-quality reconstruction but with much less computation time compared to the state-of-the-art. Moreover, our method is robust to pose, expression and lighting due to the diversity of data.
Deep Face Feature for Face Alignment
Mar 12, 2018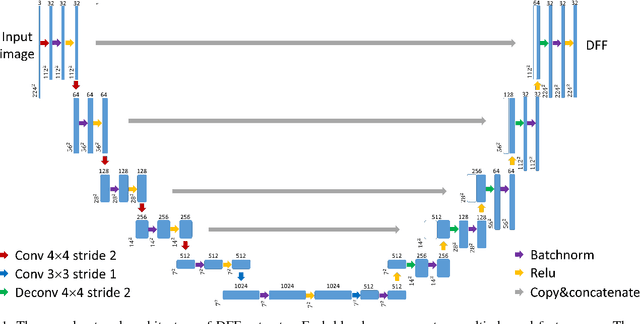


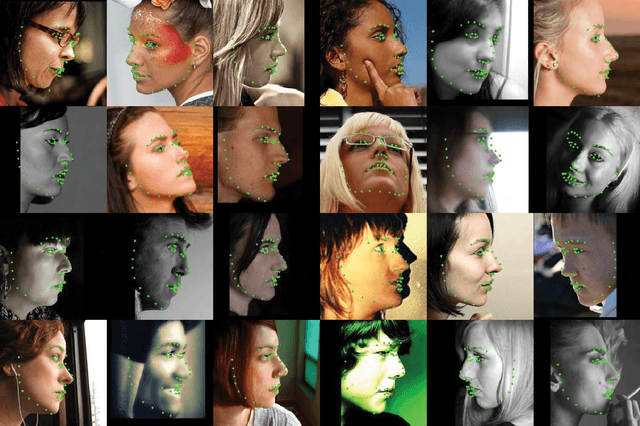
In this paper, we present a deep learning based image feature extraction method designed specifically for face images. To train the feature extraction model, we construct a large scale photo-realistic face image dataset with ground-truth correspondence between multi-view face images, which are synthesized from real photographs via an inverse rendering procedure. The deep face feature (DFF) is trained using correspondence between face images rendered from different views. Using the trained DFF model, we can extract a feature vector for each pixel of a face image, which distinguishes different facial regions and is shown to be more effective than general-purpose feature descriptors for face-related tasks such as matching and alignment. Based on the DFF, we develop a robust face alignment method, which iteratively updates landmarks, pose and 3D shape. Extensive experiments demonstrate that our method can achieve state-of-the-art results for face alignment under highly unconstrained face images.