 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeuROK: Generative 4D Neural Object Kinematics
May 28, 2026Data-driven approaches have revolutionized 3D vision, enabling transformers to effectively reconstruct and generate static 3D objects. However, generating simulative 4D dynamics -- realistic temporal deformations of static objects under various physical conditions -- remains challenging and often ad hoc, despite its importance in building comprehensive 3D world models. Most existing methods assume a predefined physical model and use system identification to estimate parameters, restricting these methods to specific categories and small-scale datasets. We propose that these restrictions can be overcome by learning a data-driven kinematic state parameterization for object-centric physical systems. Specifically, we learn both a latent space representing all possible states of the object and a decoder that maps any sampled latent to a plausibly deformed shape of the object. We refer to this parameterization as Neural Object Kinematics (NeuROK), and learn a transformer-based encoder-decoder model on a curated large-scale 4D dataset. This formulation and the learned model significantly simplify the generation of simulative dynamics since we only need to consider the dynamics within a low-dimensional latent space from the Lagrangian mechanics' perspective in classical physics. We demonstrate the effectiveness and generality of this neural simulation framework across diverse dynamic object types, showing clear advantages over prior works. Project page: https://chen-geng.com/neurok
StepAudio 2.5 Technical Report
May 22, 2026Unified audio-language modeling has emerged as a prominent trend in modern speech systems, promising to bring the reasoning capabilities of large language models to auditory tasks. However, existing unified foundations often struggle to match the depth of specialized systems across automatic speech recognition (ASR), text-to-speech synthesis (TTS), and realtime spoken interaction. Bridging this gap remains an open challenge. This report presents StepAudio 2.5, a unified audio-language foundation model that matches or exceeds specialized systems across all three capabilities. Rather than treating these tasks as architecturally distinct, we operate on the premise that once text and audio share a multimodal representational space, task specialization becomes a matter of operational regimes: data construction, optimization targets, and decoding constraints. Guided by this insight, we advance the post-training paradigm from standard supervised learning to task-tailored Reinforcement Learning from Human Feedback (RLHF), using it as the primary mechanism to define complex optimization targets. We leverage this RLHF-centric alignment, alongside specialized decoding, to shape a shared backbone into three distinct operational modes. Concretely, the ASR branch advances transcription efficiency via verifiable multi-token decoding; the TTS branch achieves controllable, expressive synthesis through preference-based RLHF and context-rich supervision; and the Realtime branch realizes low-latency, persona-consistent dialogue via generative reward modeling within an RLHF framework. On standard benchmarks, StepAudio 2.5 achieves state-of-the-art results across ASR, TTS, and Realtime, demonstrating that a singular audio-language foundation can successfully internalize the distinct deployment objectives of speech understanding, generation, and live interaction.
GenFusion: Feed-forward Human Performance Capture via Progressive Canonical Space Updates
Mar 30, 2026We present a feed-forward human performance capture method that renders novel views of a performer from a monocular RGB stream. A key challenge in this setting is the lack of sufficient observations, especially for unseen regions. Assuming the subject moves continuously over time, we take advantage of the fact that more body parts become observable by maintaining a canonical space that is progressively updated with each incoming frame. This canonical space accumulates appearance information over time and serves as a context bank when direct observations are missing in the current live frame. To effectively utilize this context while respecting the deformation of the live state, we formulate the rendering process as probabilistic regression. This resolves conflicts between past and current observations, producing sharper reconstructions than deterministic regression approaches. Furthermore, it enables plausible synthesis even in regions with no prior observations. Experiments on in-domain (4D-Dress) and out-of-distribution (MVHumanNet) datasets demonstrate the effectiveness of our approach.
Choreographing a World of Dynamic Objects
Jan 07, 2026Dynamic objects in our physical 4D (3D + time) world are constantly evolving, deforming, and interacting with other objects, leading to diverse 4D scene dynamics. In this paper, we present a universal generative pipeline, CHORD, for CHOReographing Dynamic objects and scenes and synthesizing this type of phenomena. Traditional rule-based graphics pipelines to create these dynamics are based on category-specific heuristics, yet are labor-intensive and not scalable. Recent learning-based methods typically demand large-scale datasets, which may not cover all object categories in interest. Our approach instead inherits the universality from the video generative models by proposing a distillation-based pipeline to extract the rich Lagrangian motion information hidden in the Eulerian representations of 2D videos. Our method is universal, versatile, and category-agnostic. We demonstrate its effectiveness by conducting experiments to generate a diverse range of multi-body 4D dynamics, show its advantage compared to existing methods, and demonstrate its applicability in generating robotics manipulation policies. Project page: https://yanzhelyu.github.io/chord
ART: Articulated Reconstruction Transformer
Dec 16, 2025We introduce ART, Articulated Reconstruction Transformer -- a category-agnostic, feed-forward model that reconstructs complete 3D articulated objects from only sparse, multi-state RGB images. Previous methods for articulated object reconstruction either rely on slow optimization with fragile cross-state correspondences or use feed-forward models limited to specific object categories. In contrast, ART treats articulated objects as assemblies of rigid parts, formulating reconstruction as part-based prediction. Our newly designed transformer architecture maps sparse image inputs to a set of learnable part slots, from which ART jointly decodes unified representations for individual parts, including their 3D geometry, texture, and explicit articulation parameters. The resulting reconstructions are physically interpretable and readily exportable for simulation. Trained on a large-scale, diverse dataset with per-part supervision, and evaluated across diverse benchmarks, ART achieves significant improvements over existing baselines and establishes a new state of the art for articulated object reconstruction from image inputs.
Coupled Diffusion Sampling for Training-Free Multi-View Image Editing
Oct 16, 2025We present an inference-time diffusion sampling method to perform multi-view consistent image editing using pre-trained 2D image editing models. These models can independently produce high-quality edits for each image in a set of multi-view images of a 3D scene or object, but they do not maintain consistency across views. Existing approaches typically address this by optimizing over explicit 3D representations, but they suffer from a lengthy optimization process and instability under sparse view settings. We propose an implicit 3D regularization approach by constraining the generated 2D image sequences to adhere to a pre-trained multi-view image distribution. This is achieved through coupled diffusion sampling, a simple diffusion sampling technique that concurrently samples two trajectories from both a multi-view image distribution and a 2D edited image distribution, using a coupling term to enforce the multi-view consistency among the generated images. We validate the effectiveness and generality of this framework on three distinct multi-view image editing tasks, demonstrating its applicability across various model architectures and highlighting its potential as a general solution for multi-view consistent editing.
Category-Agnostic Neural Object Rigging
May 26, 2025The motion of deformable 4D objects lies in a low-dimensional manifold. To better capture the low dimensionality and enable better controllability, traditional methods have devised several heuristic-based methods, i.e., rigging, for manipulating dynamic objects in an intuitive fashion. However, such representations are not scalable due to the need for expert knowledge of specific categories. Instead, we study the automatic exploration of such low-dimensional structures in a purely data-driven manner. Specifically, we design a novel representation that encodes deformable 4D objects into a sparse set of spatially grounded blobs and an instance-aware feature volume to disentangle the pose and instance information of the 3D shape. With such a representation, we can manipulate the pose of 3D objects intuitively by modifying the parameters of the blobs, while preserving rich instance-specific information. We evaluate the proposed method on a variety of object categories and demonstrate the effectiveness of the proposed framework. Project page: https://guangzhaohe.com/canor
Anymate: A Dataset and Baselines for Learning 3D Object Rigging
May 09, 2025Rigging and skinning are essential steps to create realistic 3D animations, often requiring significant expertise and manual effort. Traditional attempts at automating these processes rely heavily on geometric heuristics and often struggle with objects of complex geometry. Recent data-driven approaches show potential for better generality, but are often constrained by limited training data. We present the Anymate Dataset, a large-scale dataset of 230K 3D assets paired with expert-crafted rigging and skinning information -- 70 times larger than existing datasets. Using this dataset, we propose a learning-based auto-rigging framework with three sequential modules for joint, connectivity, and skinning weight prediction. We systematically design and experiment with various architectures as baselines for each module and conduct comprehensive evaluations on our dataset to compare their performance. Our models significantly outperform existing methods, providing a foundation for comparing future methods in automated rigging and skinning. Code and dataset can be found at https://anymate3d.github.io/.
Birth and Death of a Rose
Dec 06, 2024



We study the problem of generating temporal object intrinsics -- temporally evolving sequences of object geometry, reflectance, and texture, such as a blooming rose -- from pre-trained 2D foundation models. Unlike conventional 3D modeling and animation techniques that require extensive manual effort and expertise, we introduce a method that generates such assets with signals distilled from pre-trained 2D diffusion models. To ensure the temporal consistency of object intrinsics, we propose Neural Templates for temporal-state-guided distillation, derived automatically from image features from self-supervised learning. Our method can generate high-quality temporal object intrinsics for several natural phenomena and enable the sampling and controllable rendering of these dynamic objects from any viewpoint, under any environmental lighting conditions, at any time of their lifespan. Project website: https://chen-geng.com/rose4d
Tree-Structured Shading Decomposition
Sep 13, 2023

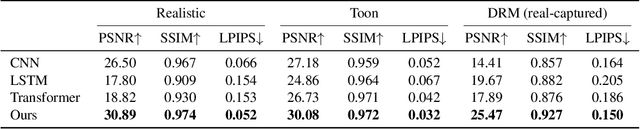
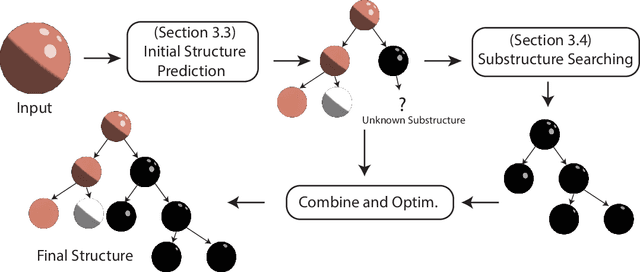
We study inferring a tree-structured representation from a single image for object shading. Prior work typically uses the parametric or measured representation to model shading, which is neither interpretable nor easily editable. We propose using the shade tree representation, which combines basic shading nodes and compositing methods to factorize object surface shading. The shade tree representation enables novice users who are unfamiliar with the physical shading process to edit object shading in an efficient and intuitive manner. A main challenge in inferring the shade tree is that the inference problem involves both the discrete tree structure and the continuous parameters of the tree nodes. We propose a hybrid approach to address this issue. We introduce an auto-regressive inference model to generate a rough estimation of the tree structure and node parameters, and then we fine-tune the inferred shade tree through an optimization algorithm. We show experiments on synthetic images, captured reflectance, real images, and non-realistic vector drawings, allowing downstream applications such as material editing, vectorized shading, and relighting. Project website: https://chen-geng.com/inv-shade-trees