 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStep-GUI Technical Report
Dec 19, 2025



Recent advances in multimodal large language models unlock unprecedented opportunities for GUI automation. However, a fundamental challenge remains: how to efficiently acquire high-quality training data while maintaining annotation reliability? We introduce a self-evolving training pipeline powered by the Calibrated Step Reward System, which converts model-generated trajectories into reliable training signals through trajectory-level calibration, achieving >90% annotation accuracy with 10-100x lower cost. Leveraging this pipeline, we introduce Step-GUI, a family of models (4B/8B) that achieves state-of-the-art GUI performance (8B: 80.2% AndroidWorld, 48.5% OSWorld, 62.6% ScreenShot-Pro) while maintaining robust general capabilities. As GUI agent capabilities improve, practical deployment demands standardized interfaces across heterogeneous devices while protecting user privacy. To this end, we propose GUI-MCP, the first Model Context Protocol for GUI automation with hierarchical architecture that combines low-level atomic operations and high-level task delegation to local specialist models, enabling high-privacy execution where sensitive data stays on-device. Finally, to assess whether agents can handle authentic everyday usage, we introduce AndroidDaily, a benchmark grounded in real-world mobile usage patterns with 3146 static actions and 235 end-to-end tasks across high-frequency daily scenarios (8B: static 89.91%, end-to-end 52.50%). Our work advances the development of practical GUI agents and demonstrates strong potential for real-world deployment in everyday digital interactions.
Advancing Embodied Agent Security: From Safety Benchmarks to Input Moderation
Apr 22, 2025



Embodied agents exhibit immense potential across a multitude of domains, making the assurance of their behavioral safety a fundamental prerequisite for their widespread deployment. However, existing research predominantly concentrates on the security of general large language models, lacking specialized methodologies for establishing safety benchmarks and input moderation tailored to embodied agents. To bridge this gap, this paper introduces a novel input moderation framework, meticulously designed to safeguard embodied agents. This framework encompasses the entire pipeline, including taxonomy definition, dataset curation, moderator architecture, model training, and rigorous evaluation. Notably, we introduce EAsafetyBench, a meticulously crafted safety benchmark engineered to facilitate both the training and stringent assessment of moderators specifically designed for embodied agents. Furthermore, we propose Pinpoint, an innovative prompt-decoupled input moderation scheme that harnesses a masked attention mechanism to effectively isolate and mitigate the influence of functional prompts on moderation tasks. Extensive experiments conducted on diverse benchmark datasets and models validate the feasibility and efficacy of the proposed approach. The results demonstrate that our methodologies achieve an impressive average detection accuracy of 94.58%, surpassing the performance of existing state-of-the-art techniques, alongside an exceptional moderation processing time of merely 0.002 seconds per instance.
Social Life Simulation for Non-Cognitive Skills Learning
May 01, 2024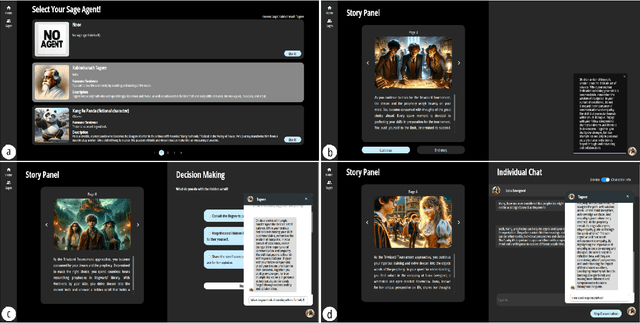
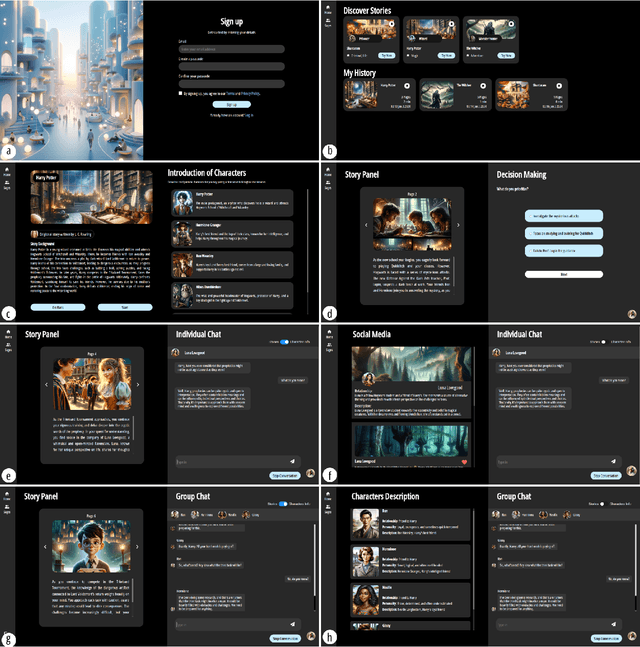
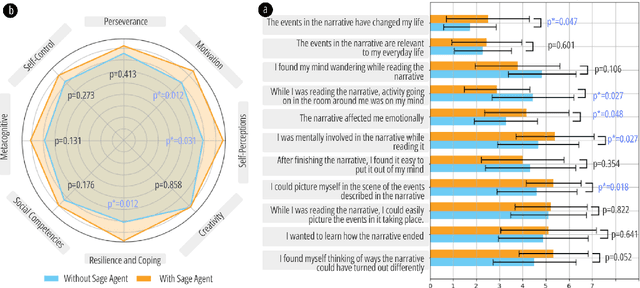
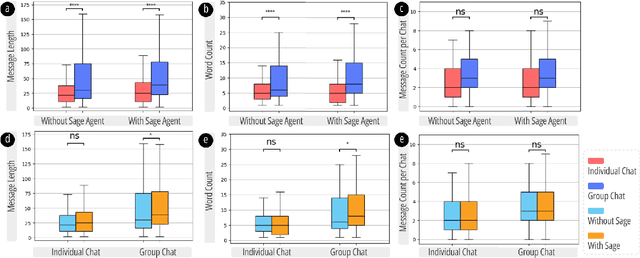
Non-cognitive skills are crucial for personal and social life well-being, and such skill development can be supported by narrative-based (e.g., storytelling) technologies. While generative AI enables interactive and role-playing storytelling, little is known about how users engage with and perceive the use of AI in social life simulation for non-cognitive skills learning. To this end, we introduced SimuLife++, an interactive platform enabled by a large language model (LLM). The system allows users to act as protagonists, creating stories with one or multiple AI-based characters in diverse social scenarios. In particular, we expanded the Human-AI interaction to a Human-AI-AI collaboration by including a sage agent, who acts as a bystander to provide users with more insightful perspectives on their choices and conversations. Through a within-subject user study, we found that the inclusion of the sage agent significantly enhanced narrative immersion, according to the narrative transportation scale, leading to more messages, particularly in group chats. Participants' interactions with the sage agent were also associated with significantly higher scores in their perceived motivation, self-perceptions, and resilience and coping, indicating positive impacts on non-cognitive skills reflection. Participants' interview results further explained the sage agent's aid in decision-making, solving ethical dilemmas, and problem-solving; on the other hand, they suggested improvements in user control and balanced responses from multiple characters. We provide design implications on the application of generative AI in narrative solutions for non-cognitive skill development in broader social contexts.
Supporting Mitosis Detection AI Training with Inter-Observer Eye-Gaze Consistencies
Apr 02, 2024

The expansion of artificial intelligence (AI) in pathology tasks has intensified the demand for doctors' annotations in AI development. However, collecting high-quality annotations from doctors is costly and time-consuming, creating a bottleneck in AI progress. This study investigates eye-tracking as a cost-effective technology to collect doctors' behavioral data for AI training with a focus on the pathology task of mitosis detection. One major challenge in using eye-gaze data is the low signal-to-noise ratio, which hinders the extraction of meaningful information. We tackled this by levering the properties of inter-observer eye-gaze consistencies and creating eye-gaze labels from consistent eye-fixations shared by a group of observers. Our study involved 14 non-medical participants, from whom we collected eye-gaze data and generated eye-gaze labels based on varying group sizes. We assessed the efficacy of such eye-gaze labels by training Convolutional Neural Networks (CNNs) and comparing their performance to those trained with ground truth annotations and a heuristic-based baseline. Results indicated that CNNs trained with our eye-gaze labels closely followed the performance of ground-truth-based CNNs, and significantly outperformed the baseline. Although primarily focused on mitosis, we envision that insights from this study can be generalized to other medical imaging tasks.
Relightable and Animatable Neural Avatar from Sparse-View Video
Aug 17, 2023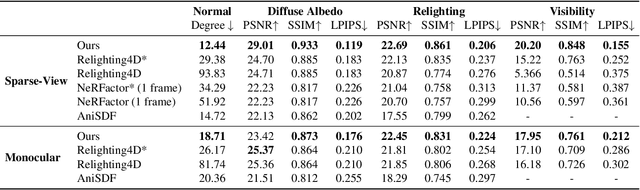
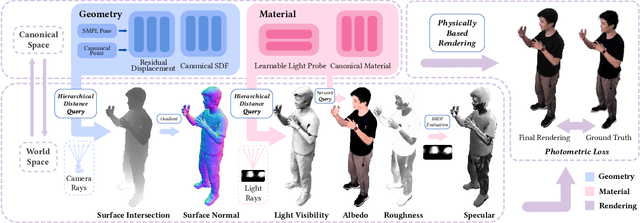
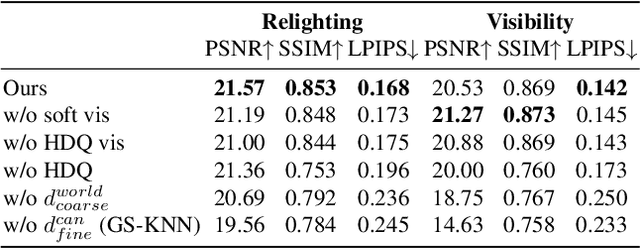
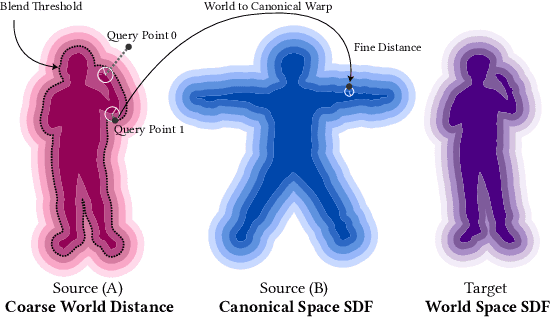
This paper tackles the challenge of creating relightable and animatable neural avatars from sparse-view (or even monocular) videos of dynamic humans under unknown illumination. Compared to studio environments, this setting is more practical and accessible but poses an extremely challenging ill-posed problem. Previous neural human reconstruction methods are able to reconstruct animatable avatars from sparse views using deformed Signed Distance Fields (SDF) but cannot recover material parameters for relighting. While differentiable inverse rendering-based methods have succeeded in material recovery of static objects, it is not straightforward to extend them to dynamic humans as it is computationally intensive to compute pixel-surface intersection and light visibility on deformed SDFs for inverse rendering. To solve this challenge, we propose a Hierarchical Distance Query (HDQ) algorithm to approximate the world space distances under arbitrary human poses. Specifically, we estimate coarse distances based on a parametric human model and compute fine distances by exploiting the local deformation invariance of SDF. Based on the HDQ algorithm, we leverage sphere tracing to efficiently estimate the surface intersection and light visibility. This allows us to develop the first system to recover animatable and relightable neural avatars from sparse view (or monocular) inputs. Experiments demonstrate that our approach is able to produce superior results compared to state-of-the-art methods. Our code will be released for reproducibility.
XNLI: Explaining and Diagnosing NLI-based Visual Data Analysis
Jan 25, 2023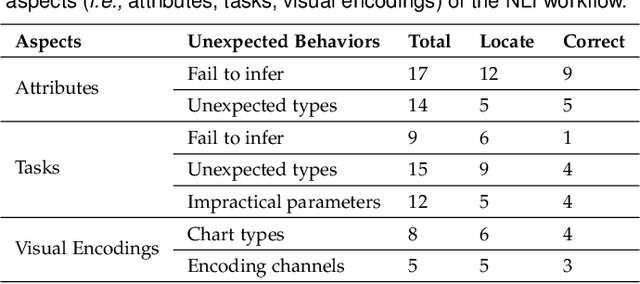
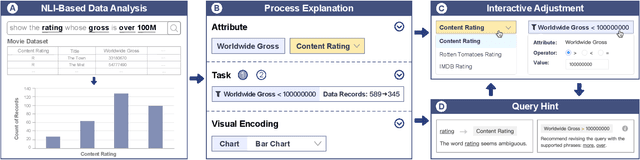
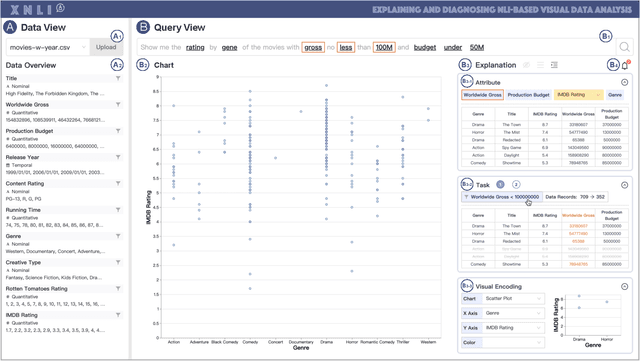
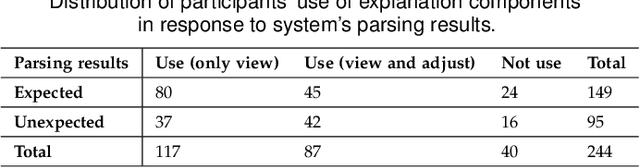
Natural language interfaces (NLIs) enable users to flexibly specify analytical intentions in data visualization. However, diagnosing the visualization results without understanding the underlying generation process is challenging. Our research explores how to provide explanations for NLIs to help users locate the problems and further revise the queries. We present XNLI, an explainable NLI system for visual data analysis. The system introduces a Provenance Generator to reveal the detailed process of visual transformations, a suite of interactive widgets to support error adjustments, and a Hint Generator to provide query revision hints based on the analysis of user queries and interactions. Two usage scenarios of XNLI and a user study verify the effectiveness and usability of the system. Results suggest that XNLI can significantly enhance task accuracy without interrupting the NLI-based analysis process.
TC-SfM: Robust Track-Community-Based Structure-from-Motion
Jun 13, 2022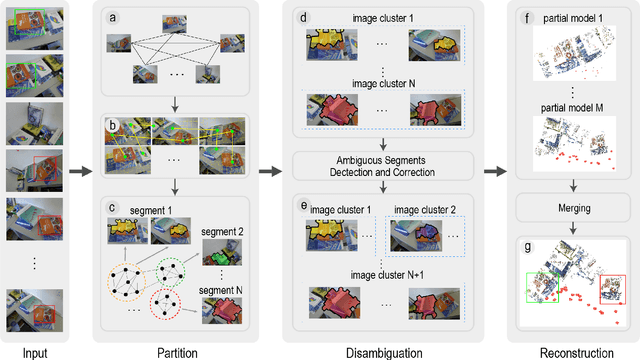
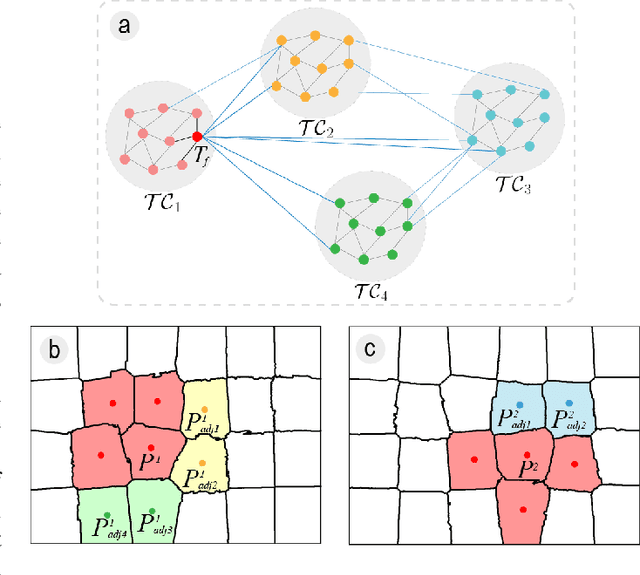

Structure-from-Motion (SfM) aims to recover 3D scene structures and camera poses based on the correspondences between input images, and thus the ambiguity caused by duplicate structures (i.e., different structures with strong visual resemblance) always results in incorrect camera poses and 3D structures. To deal with the ambiguity, most existing studies resort to additional constraint information or implicit inference by analyzing two-view geometries or feature points. In this paper, we propose to exploit high-level information in the scene, i.e., the spatial contextual information of local regions, to guide the reconstruction. Specifically, a novel structure is proposed, namely, {\textit{track-community}}, in which each community consists of a group of tracks and represents a local segment in the scene. A community detection algorithm is used to partition the scene into several segments. Then, the potential ambiguous segments are detected by analyzing the neighborhood of tracks and corrected by checking the pose consistency. Finally, we perform partial reconstruction on each segment and align them with a novel bidirectional consistency cost function which considers both 3D-3D correspondences and pairwise relative camera poses. Experimental results demonstrate that our approach can robustly alleviate reconstruction failure resulting from visually indistinguishable structures and accurately merge the partial reconstructions.
Towards Improving Embedding Based Models of Social Network Alignment via Pseudo Anchors
Nov 22, 2021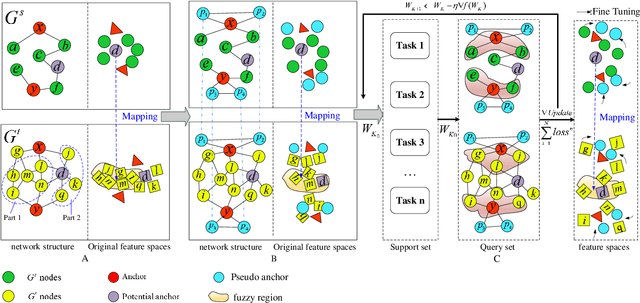
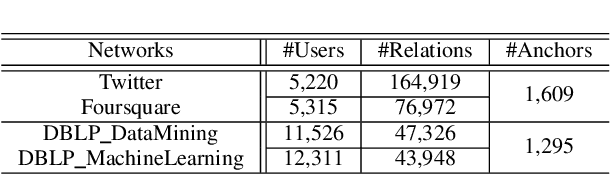
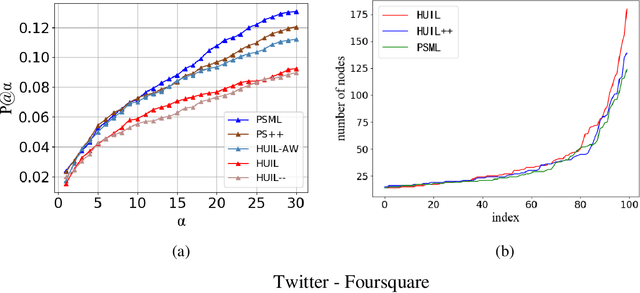
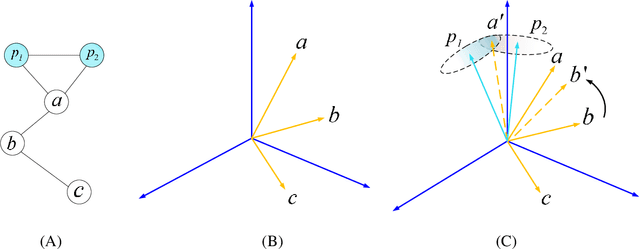
Social network alignment aims at aligning person identities across social networks. Embedding based models have been shown effective for the alignment where the structural proximity preserving objective is typically adopted for the model training. With the observation that ``overly-close'' user embeddings are unavoidable for such models causing alignment inaccuracy, we propose a novel learning framework which tries to enforce the resulting embeddings to be more widely apart among the users via the introduction of carefully implanted pseudo anchors. We further proposed a meta-learning algorithm to guide the updating of the pseudo anchor embeddings during the learning process. The proposed intervention via the use of pseudo anchors and meta-learning allows the learning framework to be applicable to a wide spectrum of network alignment methods. We have incorporated the proposed learning framework into several state-of-the-art models. Our experimental results demonstrate its efficacy where the methods with the pseudo anchors implanted can outperform their counterparts without pseudo anchors by a fairly large margin, especially when there only exist very few labeled anchors.