 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisentangled Geometry and Appearance for Efficient Multi-View Surface Reconstruction and Rendering
Aug 24, 2025This paper addresses the limitations of neural rendering-based multi-view surface reconstruction methods, which require an additional mesh extraction step that is inconvenient and would produce poor-quality surfaces with mesh aliasing, restricting downstream applications. Building on the explicit mesh representation and differentiable rasterization framework, this work proposes an efficient solution that preserves the high efficiency of this framework while significantly improving reconstruction quality and versatility. Specifically, we introduce a disentangled geometry and appearance model that does not rely on deep networks, enhancing learning and broadening applicability. A neural deformation field is constructed to incorporate global geometric context, enhancing geometry learning, while a novel regularization constrains geometric features passed to a neural shader to ensure its accuracy and boost shading. For appearance, a view-invariant diffuse term is separated and baked into mesh vertices, further improving rendering efficiency. Experimental results demonstrate that the proposed method achieves state-of-the-art training (4.84 minutes) and rendering (0.023 seconds) speeds, with reconstruction quality that is competitive with top-performing methods. Moreover, the method enables practical applications such as mesh and texture editing, showcasing its versatility and application potential. This combination of efficiency, competitive quality, and broad applicability makes our approach a valuable contribution to multi-view surface reconstruction and rendering.
TC-SfM: Robust Track-Community-Based Structure-from-Motion
Jun 13, 2022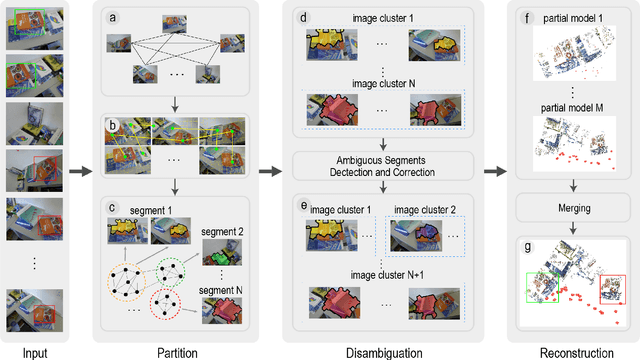
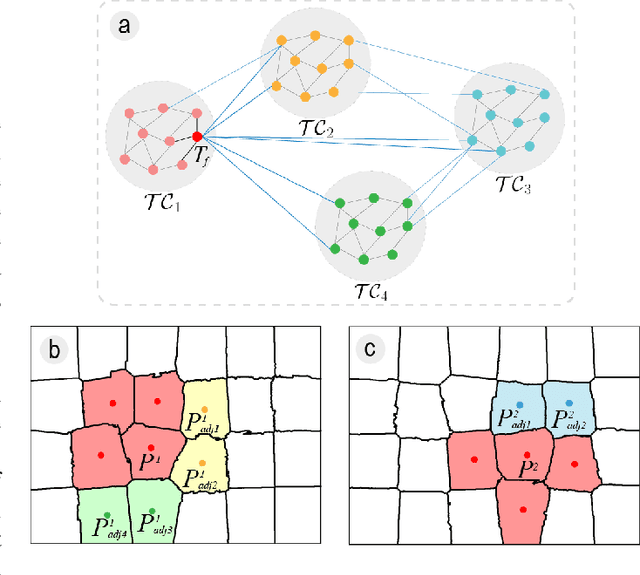

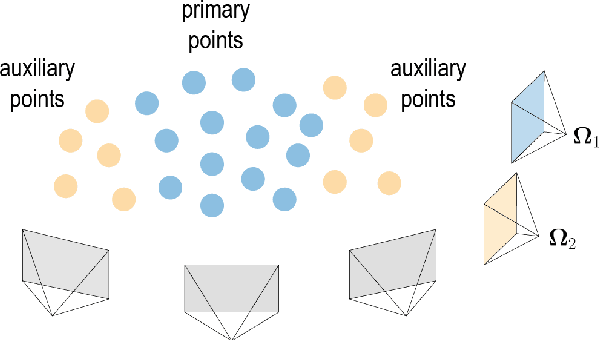
Structure-from-Motion (SfM) aims to recover 3D scene structures and camera poses based on the correspondences between input images, and thus the ambiguity caused by duplicate structures (i.e., different structures with strong visual resemblance) always results in incorrect camera poses and 3D structures. To deal with the ambiguity, most existing studies resort to additional constraint information or implicit inference by analyzing two-view geometries or feature points. In this paper, we propose to exploit high-level information in the scene, i.e., the spatial contextual information of local regions, to guide the reconstruction. Specifically, a novel structure is proposed, namely, {\textit{track-community}}, in which each community consists of a group of tracks and represents a local segment in the scene. A community detection algorithm is used to partition the scene into several segments. Then, the potential ambiguous segments are detected by analyzing the neighborhood of tracks and corrected by checking the pose consistency. Finally, we perform partial reconstruction on each segment and align them with a novel bidirectional consistency cost function which considers both 3D-3D correspondences and pairwise relative camera poses. Experimental results demonstrate that our approach can robustly alleviate reconstruction failure resulting from visually indistinguishable structures and accurately merge the partial reconstructions.