 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideoPro: A Visual Analytics Approach for Interactive Video Programming
Aug 01, 2023


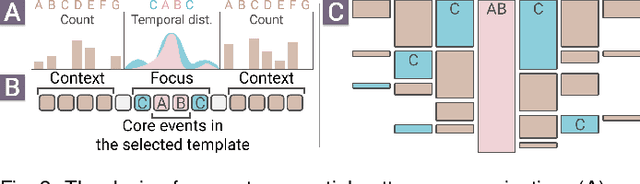
Constructing supervised machine learning models for real-world video analysis require substantial labeled data, which is costly to acquire due to scarce domain expertise and laborious manual inspection. While data programming shows promise in generating labeled data at scale with user-defined labeling functions, the high dimensional and complex temporal information in videos poses additional challenges for effectively composing and evaluating labeling functions. In this paper, we propose VideoPro, a visual analytics approach to support flexible and scalable video data programming for model steering with reduced human effort. We first extract human-understandable events from videos using computer vision techniques and treat them as atomic components of labeling functions. We further propose a two-stage template mining algorithm that characterizes the sequential patterns of these events to serve as labeling function templates for efficient data labeling. The visual interface of VideoPro facilitates multifaceted exploration, examination, and application of the labeling templates, allowing for effective programming of video data at scale. Moreover, users can monitor the impact of programming on model performance and make informed adjustments during the iterative programming process. We demonstrate the efficiency and effectiveness of our approach with two case studies and expert interviews.
Computational Approaches for Traditional Chinese Painting: From the "Six Principles of Painting" Perspective
Jul 26, 2023Traditional Chinese Painting (TCP) is an invaluable cultural heritage resource and a unique visual art style. In recent years, increasing interest has been placed on digitalizing TCPs to preserve and revive the culture. The resulting digital copies have enabled the advancement of computational methods for structured and systematic understanding of TCPs. To explore this topic, we conducted an in-depth analysis of 92 pieces of literature. We examined the current use of computer technologies on TCPs from three perspectives, based on numerous conversations with specialists. First, in light of the "Six Principles of Painting" theory, we categorized the articles according to their research focus on artistic elements. Second, we created a four-stage framework to illustrate the purposes of TCP applications. Third, we summarized the popular computational techniques applied to TCPs. The framework also provides insights into potential applications and future prospects, with professional opinion. The list of surveyed publications and related information is available online at https://ca4tcp.com.
PromptMagician: Interactive Prompt Engineering for Text-to-Image Creation
Jul 18, 2023Generative text-to-image models have gained great popularity among the public for their powerful capability to generate high-quality images based on natural language prompts. However, developing effective prompts for desired images can be challenging due to the complexity and ambiguity of natural language. This research proposes PromptMagician, a visual analysis system that helps users explore the image results and refine the input prompts. The backbone of our system is a prompt recommendation model that takes user prompts as input, retrieves similar prompt-image pairs from DiffusionDB, and identifies special (important and relevant) prompt keywords. To facilitate interactive prompt refinement, PromptMagician introduces a multi-level visualization for the cross-modal embedding of the retrieved images and recommended keywords, and supports users in specifying multiple criteria for personalized exploration. Two usage scenarios, a user study, and expert interviews demonstrate the effectiveness and usability of our system, suggesting it facilitates prompt engineering and improves the creativity support of the generative text-to-image model.
XNLI: Explaining and Diagnosing NLI-based Visual Data Analysis
Jan 25, 2023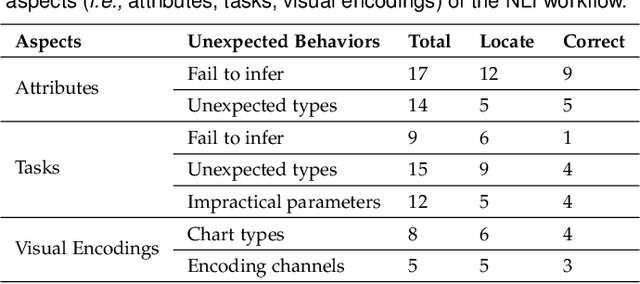
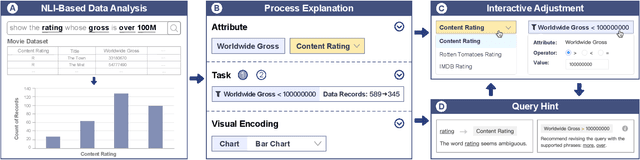
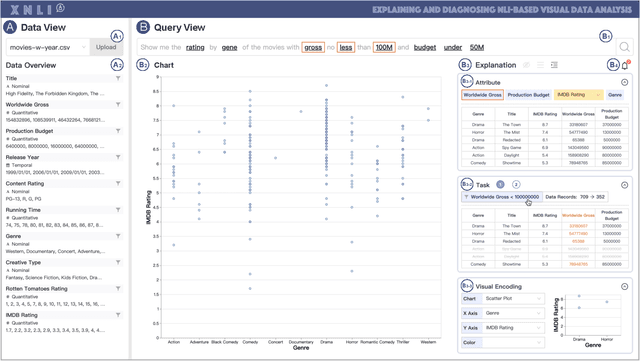
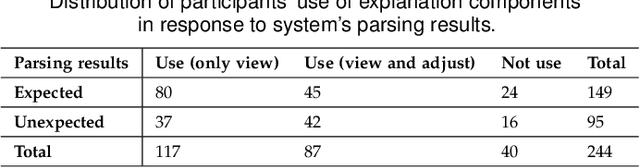
Natural language interfaces (NLIs) enable users to flexibly specify analytical intentions in data visualization. However, diagnosing the visualization results without understanding the underlying generation process is challenging. Our research explores how to provide explanations for NLIs to help users locate the problems and further revise the queries. We present XNLI, an explainable NLI system for visual data analysis. The system introduces a Provenance Generator to reveal the detailed process of visual transformations, a suite of interactive widgets to support error adjustments, and a Hint Generator to provide query revision hints based on the analysis of user queries and interactions. Two usage scenarios of XNLI and a user study verify the effectiveness and usability of the system. Results suggest that XNLI can significantly enhance task accuracy without interrupting the NLI-based analysis process.