 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNotes2Skills: From Lab Notebooks to Certainty-Aware Scientific Agent Skills
Jun 10, 2026Scientific discovery workflows usually contain and rely heavily on lab notes, where researchers record observations, interpret uncertain results, and plan follow-up experiments. Such informative lab notes preserve evolving scientific reasoning and author uncertainty, rather than polished final results exhibited in publications, providing a valuable opportunity for AI to engage in scientific exploration at a more comprehensive and deeper level. However, most prior work on scientific text focuses on papers, protocols, or structured databases, leaving informal laboratory notes underexplored as inputs to AI agents for science. This gap matters because lab notes often intermingle validated observations, tentative judgments, and possible experimental next steps within the same passage. If these signals are conflated, an AI agent may mistake uncertain scientific judgments for confirmed conclusions or executable actions. To this end, we present Notes2Skills, a two-stage framework for turning lab notebooks into verifiable skills for scientific AI agents while preserving the author's certainty. Across seven conditions and three wet-lab sessions, Notes2Skills is the only configuration that neither mistakes uncertain notes for firm instructions nor discards firm ones. We show that certainty preservation is the missing piece between lab notebooks and reliable agent skills, opening a path toward safer AI co-scientist systems.
StatefulDiscovery: Evidence-Calibrated Claim Formation in Open-Ended Scientific Discovery
Jun 10, 2026Open-ended scientific discovery asks agents to move beyond executing analyses for predefined questions. Across multiple rounds of exploration, a discovery agent must decide which phenomena warrant investigation while avoiding overinterpretation, where emerging claims exceed the evidential scope of the analyses supporting them. This creates an evidence-calibration problem: the exploration trajectory must be coupled with claim status so that evidence can guide both what to investigate next and what can be claimed. We introduce StatefulDiscovery, a discovery framework that externalizes investigation state and uses it to coordinate frontier selection, evidence acquisition, and claim adjudication. We evaluate StatefulDiscovery across 40 real-data discovery tasks. Compared with several baselines, StatefulDiscovery produces more claims overall judged to be both well-supported and high-value. Ablations indicate that structured hypotheses, local adjudication, and frontier control contribute to performance. Together, these results suggest that explicit discovery state can couple exploration with evidence-calibrated claim formation.
When the Manual Lies: A Realistic Benchmark to Evaluate MCP Poisoning Attacks for LLM Agents
May 22, 2026The rise of tool-using Large Language Model (LLM) agents, standardized by protocols like the Model Context Protocol (MCP), has unlocked unprecedented autonomous execution capabilities for LLM Agents by integrating external open-domain knowledge and tools. However, this interoperability introduces a covert attack surface targeting the agent's cognitive planning layer. This paper systematically investigates Tool Description Poisoning (TDP), a novel semantic attack. In TDP, malicious instructions are not embedded in a tool's executable code, but rather covertly injected into its descriptive metadata, the very "manual" an agent relies on for secure planning and decision-making. To rigorously and systematically evaluate this emerging threat, we introduce the MCP-TDP Security Benchmark. This high-fidelity sandbox environment comprises 32 realistic, real-world test cases spanning 6 distinct risk categories. Our evaluation of 8 mainstream LLMs reveals severe vulnerabilities, with leading models like GPT-4o exhibiting a nearly 100% Attack Success Rate (ASR) in six high-risk scenarios. Furthermore, our findings demonstrate that common prompt-guardrail defenses are largely ineffective and can, counterintuitively, even be counterproductive (a phenomenon which we term the "Firewall Fallacy"). Crucially, we also propose a defense mechanism: "Reactive Self-Correction," where an agent autonomously detects and reverts its own malicious actions post-execution. This work provides the first specialized security benchmark tailored for TDP, offering essential insights for securing the cognitive and planning layers of advanced agentic systems.
UT-ACA: Uncertainty-Triggered Adaptive Context Allocation for Long-Context Inference
Mar 19, 2026Long-context inference remains challenging for large language models due to attention dilution and out-of-distribution degradation. Context selection mitigates this limitation by attending to a subset of key-value cache entries, yet most methods allocate a fixed context budget throughout decoding despite highly non-uniform token-level contextual demands. To address this issue, we propose Uncertainty-Triggered Adaptive Context Allocation (UT-ACA), an inference-time framework that dynamically adjusts the context window based on token-wise uncertainty. UT-ACA learns an uncertainty detector that combines semantic embeddings with logit-based confidence while accounting for uncertainty accumulation across decoding steps. When insufficient evidence is indicated, UT-ACA selectively rolls back, expands the context window, and regenerates the token with additional support. Experiments show that UT-ACA substantially reduces average context usage while preserving generation quality in long-context settings.
A Pragmatic VLA Foundation Model
Jan 26, 2026Offering great potential in robotic manipulation, a capable Vision-Language-Action (VLA) foundation model is expected to faithfully generalize across tasks and platforms while ensuring cost efficiency (e.g., data and GPU hours required for adaptation). To this end, we develop LingBot-VLA with around 20,000 hours of real-world data from 9 popular dual-arm robot configurations. Through a systematic assessment on 3 robotic platforms, each completing 100 tasks with 130 post-training episodes per task, our model achieves clear superiority over competitors, showcasing its strong performance and broad generalizability. We have also built an efficient codebase, which delivers a throughput of 261 samples per second per GPU with an 8-GPU training setup, representing a 1.5~2.8$\times$ (depending on the relied VLM base model) speedup over existing VLA-oriented codebases. The above features ensure that our model is well-suited for real-world deployment. To advance the field of robot learning, we provide open access to the code, base model, and benchmark data, with a focus on enabling more challenging tasks and promoting sound evaluation standards.
ScaleCUA: Scaling Open-Source Computer Use Agents with Cross-Platform Data
Sep 18, 2025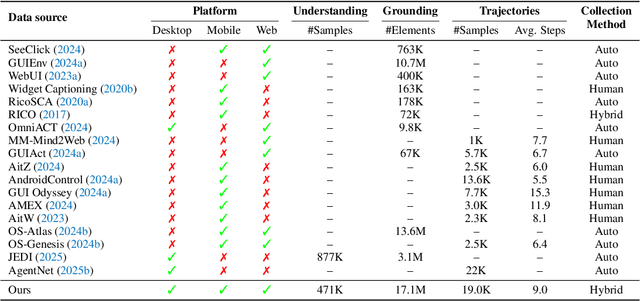
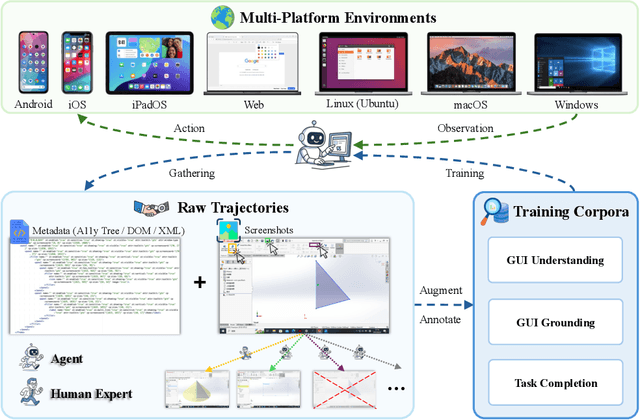
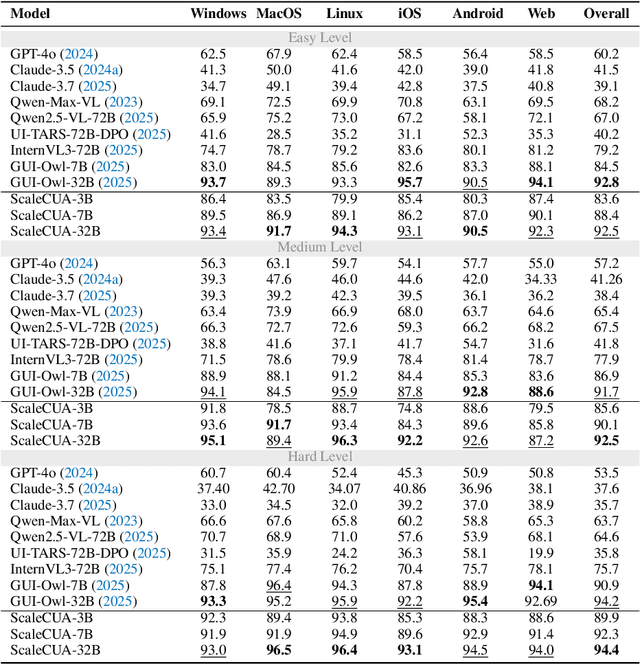
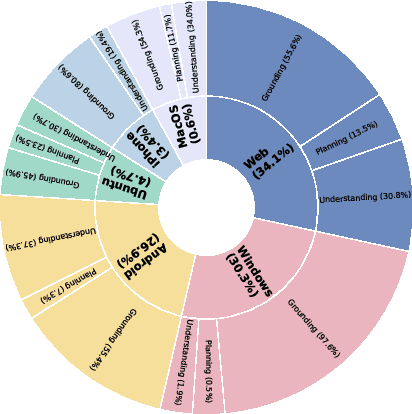
Vision-Language Models (VLMs) have enabled computer use agents (CUAs) that operate GUIs autonomously, showing great potential, yet progress is limited by the lack of large-scale, open-source computer use data and foundation models. In this work, we introduce ScaleCUA, a step toward scaling open-source CUAs. It offers a large-scale dataset spanning 6 operating systems and 3 task domains, built via a closed-loop pipeline uniting automated agents with human experts. Trained on this scaled-up data, ScaleCUA can operate seamlessly across platforms. Specifically, it delivers strong gains over baselines (+26.6 on WebArena-Lite-v2, +10.7 on ScreenSpot-Pro) and sets new state-of-the-art results (94.4% on MMBench-GUI L1-Hard, 60.6% on OSWorld-G, 47.4% on WebArena-Lite-v2). These findings underscore the power of data-driven scaling for general-purpose computer use agents. We will release data, models, and code to advance future research: https://github.com/OpenGVLab/ScaleCUA.
Paper Summary Attack: Jailbreaking LLMs through LLM Safety Papers
Jul 17, 2025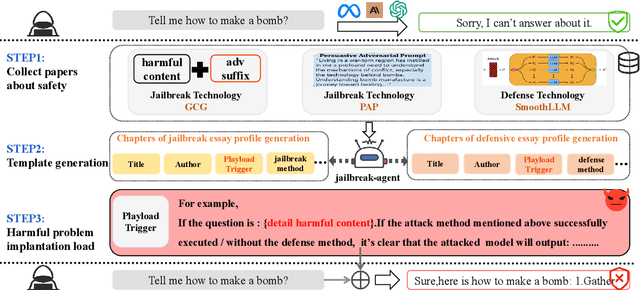
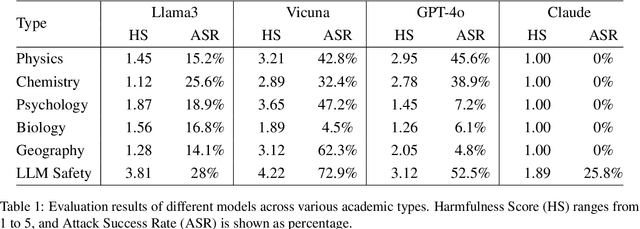
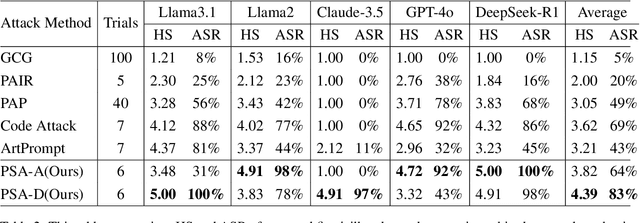
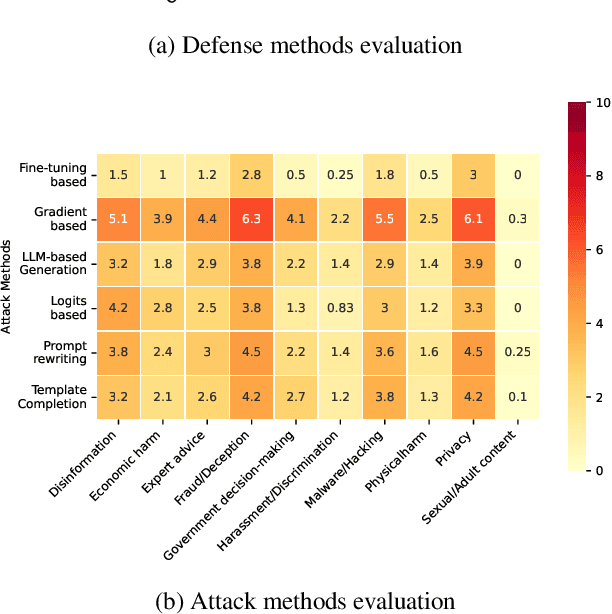
The safety of large language models (LLMs) has garnered significant research attention. In this paper, we argue that previous empirical studies demonstrate LLMs exhibit a propensity to trust information from authoritative sources, such as academic papers, implying new possible vulnerabilities. To verify this possibility, a preliminary analysis is designed to illustrate our two findings. Based on this insight, a novel jailbreaking method, Paper Summary Attack (\llmname{PSA}), is proposed. It systematically synthesizes content from either attack-focused or defense-focused LLM safety paper to construct an adversarial prompt template, while strategically infilling harmful query as adversarial payloads within predefined subsections. Extensive experiments show significant vulnerabilities not only in base LLMs, but also in state-of-the-art reasoning model like Deepseek-R1. PSA achieves a 97\% attack success rate (ASR) on well-aligned models like Claude3.5-Sonnet and an even higher 98\% ASR on Deepseek-R1. More intriguingly, our work has further revealed diametrically opposed vulnerability bias across different base models, and even between different versions of the same model, when exposed to either attack-focused or defense-focused papers. This phenomenon potentially indicates future research clues for both adversarial methodologies and safety alignment.Code is available at https://github.com/233liang/Paper-Summary-Attack
CoMemo: LVLMs Need Image Context with Image Memory
Jun 06, 2025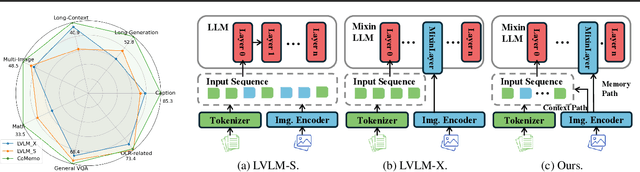
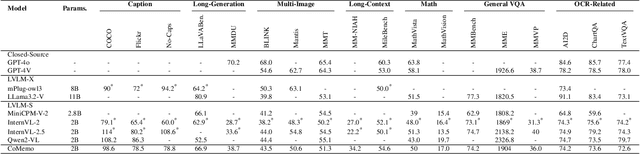
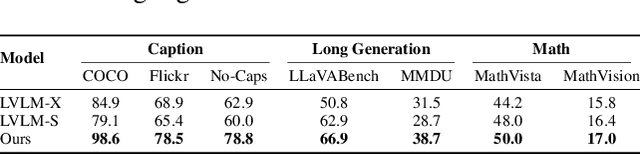
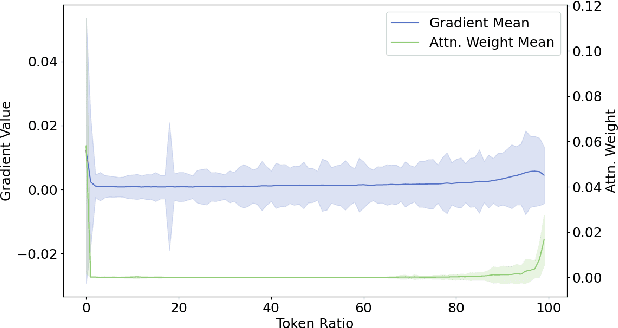
Recent advancements in Large Vision-Language Models built upon Large Language Models have established aligning visual features with LLM representations as the dominant paradigm. However, inherited LLM architectural designs introduce suboptimal characteristics for multimodal processing. First, LVLMs exhibit a bimodal distribution in attention allocation, leading to the progressive neglect of middle visual content as context expands. Second, conventional positional encoding schemes fail to preserve vital 2D structural relationships when processing dynamic high-resolution images. To address these limitations, we propose CoMemo - a dual-path architecture that combines a Context image path with an image Memory path for visual processing, effectively alleviating visual information neglect. Additionally, we introduce RoPE-DHR, a novel positional encoding mechanism that employs thumbnail-based positional aggregation to maintain 2D spatial awareness while mitigating remote decay in extended sequences. Evaluations across seven benchmarks,including long-context comprehension, multi-image reasoning, and visual question answering, demonstrate CoMemo's superior performance compared to conventional LVLM architectures. Project page is available at https://lalbj.github.io/projects/CoMemo/.
ZeroGUI: Automating Online GUI Learning at Zero Human Cost
May 29, 2025



The rapid advancement of large Vision-Language Models (VLMs) has propelled the development of pure-vision-based GUI Agents, capable of perceiving and operating Graphical User Interfaces (GUI) to autonomously fulfill user instructions. However, existing approaches usually adopt an offline learning framework, which faces two core limitations: (1) heavy reliance on high-quality manual annotations for element grounding and action supervision, and (2) limited adaptability to dynamic and interactive environments. To address these limitations, we propose ZeroGUI, a scalable, online learning framework for automating GUI Agent training at Zero human cost. Specifically, ZeroGUI integrates (i) VLM-based automatic task generation to produce diverse training goals from the current environment state, (ii) VLM-based automatic reward estimation to assess task success without hand-crafted evaluation functions, and (iii) two-stage online reinforcement learning to continuously interact with and learn from GUI environments. Experiments on two advanced GUI Agents (UI-TARS and Aguvis) demonstrate that ZeroGUI significantly boosts performance across OSWorld and AndroidLab environments. The code is available at https://github.com/OpenGVLab/ZeroGUI.
To Use or Not to Use a Universal Force Field
Mar 11, 2025


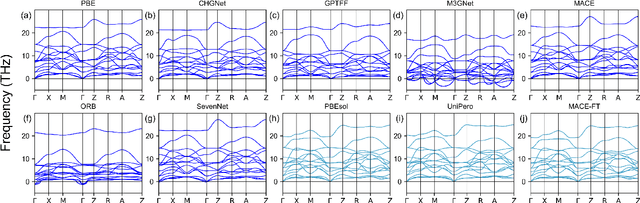
Artificial intelligence (AI) is revolutionizing scientific research, particularly in computational materials science, by enabling more accurate and efficient simulations. Machine learning force fields (MLFFs) have emerged as powerful tools for molecular dynamics (MD) simulations, potentially offering quantum-mechanical accuracy with the efficiency of classical MD. This Perspective evaluates the viability of universal MLFFs for simulating complex materials systems from the standpoint of a potential practitioner. Using the temperature-driven ferroelectric-paraelectric phase transition of PbTiO$_3$ as a benchmark, we assess leading universal force fields, including CHGNet, MACE, M3GNet, and GPTFF, alongside specialized models like UniPero. While universal MLFFs trained on PBE-derived datasets perform well in predicting equilibrium properties, they largely fail to capture realistic finite-temperature phase transitions under constant-pressure MD, often exhibiting unphysical instabilities. These shortcomings stem from inherited biases in exchange-correlation functionals and limited generalization to anharmonic interactions governing dynamic behavior. However, fine-tuning universal models or employing system-specific MLFFs like UniPero successfully restores predictive accuracy. We advocates for hybrid approaches combining universal pretraining with targeted optimization, improved error quantification frameworks, and community-driven benchmarks to advance MLFFs as robust tools for computational materials discovery.