 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSceneScribe-1M: A Large-Scale Video Dataset with Comprehensive Geometric and Semantic Annotations
Apr 09, 2026The convergence of 3D geometric perception and video synthesis has created an unprecedented demand for large-scale video data that is rich in both semantic and spatio-temporal information. While existing datasets have advanced either 3D understanding or video generation, a significant gap remains in providing a unified resource that supports both domains at scale. To bridge this chasm, we introduce SceneScribe-1M, a new large-scale, multi-modal video dataset. It comprises one million in-the-wild videos, each meticulously annotated with detailed textual descriptions, precise camera parameters, dense depth maps, and consistent 3D point tracks. We demonstrate the versatility and value of SceneScribe-1M by establishing benchmarks across a wide array of downstream tasks, including monocular depth estimation, scene reconstruction, and dynamic point tracking, as well as generative tasks such as text-to-video synthesis, with or without camera control. By open-sourcing SceneScribe-1M, we aim to provide a comprehensive benchmark and a catalyst for research, fostering the development of models that can both perceive the dynamic 3D world and generate controllable, realistic video content.
Advancing Open-source World Models
Jan 28, 2026We present LingBot-World, an open-sourced world simulator stemming from video generation. Positioned as a top-tier world model, LingBot-World offers the following features. (1) It maintains high fidelity and robust dynamics in a broad spectrum of environments, including realism, scientific contexts, cartoon styles, and beyond. (2) It enables a minute-level horizon while preserving contextual consistency over time, which is also known as "long-term memory". (3) It supports real-time interactivity, achieving a latency of under 1 second when producing 16 frames per second. We provide public access to the code and model in an effort to narrow the divide between open-source and closed-source technologies. We believe our release will empower the community with practical applications across areas like content creation, gaming, and robot learning.
A Pragmatic VLA Foundation Model
Jan 26, 2026Offering great potential in robotic manipulation, a capable Vision-Language-Action (VLA) foundation model is expected to faithfully generalize across tasks and platforms while ensuring cost efficiency (e.g., data and GPU hours required for adaptation). To this end, we develop LingBot-VLA with around 20,000 hours of real-world data from 9 popular dual-arm robot configurations. Through a systematic assessment on 3 robotic platforms, each completing 100 tasks with 130 post-training episodes per task, our model achieves clear superiority over competitors, showcasing its strong performance and broad generalizability. We have also built an efficient codebase, which delivers a throughput of 261 samples per second per GPU with an 8-GPU training setup, representing a 1.5~2.8$\times$ (depending on the relied VLM base model) speedup over existing VLA-oriented codebases. The above features ensure that our model is well-suited for real-world deployment. To advance the field of robot learning, we provide open access to the code, base model, and benchmark data, with a focus on enabling more challenging tasks and promoting sound evaluation standards.
Learning Consistent Taxonomic Classification through Hierarchical Reasoning
Jan 21, 2026While Vision-Language Models (VLMs) excel at visual understanding, they often fail to grasp hierarchical knowledge. This leads to common errors where VLMs misclassify coarser taxonomic levels even when correctly identifying the most specific level (leaf level). Existing approaches largely overlook this issue by failing to model hierarchical reasoning. To address this gap, we propose VL-Taxon, a two-stage, hierarchy-based reasoning framework designed to improve both leaf-level accuracy and hierarchical consistency in taxonomic classification. The first stage employs a top-down process to enhance leaf-level classification accuracy. The second stage then leverages this accurate leaf-level output to ensure consistency throughout the entire taxonomic hierarchy. Each stage is initially trained with supervised fine-tuning to instill taxonomy knowledge, followed by reinforcement learning to refine the model's reasoning and generalization capabilities. Extensive experiments reveal a remarkable result: our VL-Taxon framework, implemented on the Qwen2.5-VL-7B model, outperforms its original 72B counterpart by over 10% in both leaf-level and hierarchical consistency accuracy on average on the iNaturalist-2021 dataset. Notably, this significant gain was achieved by fine-tuning on just a small subset of data, without relying on any examples generated by other VLMs.
The Great March 100: 100 Detail-oriented Tasks for Evaluating Embodied AI Agents
Jan 16, 2026Recently, with the rapid development of robot learning and imitation learning, numerous datasets and methods have emerged. However, these datasets and their task designs often lack systematic consideration and principles. This raises important questions: Do the current datasets and task designs truly advance the capabilities of robotic agents? Do evaluations on a few common tasks accurately reflect the differentiated performance of various methods proposed by different teams and evaluated on different tasks? To address these issues, we introduce the Great March 100 (\textbf{GM-100}) as the first step towards a robot learning Olympics. GM-100 consists of 100 carefully designed tasks that cover a wide range of interactions and long-tail behaviors, aiming to provide a diverse and challenging set of tasks to comprehensively evaluate the capabilities of robotic agents and promote diversity and complexity in robot dataset task designs. These tasks are developed through systematic analysis and expansion of existing task designs, combined with insights from human-object interaction primitives and object affordances. We collect a large amount of trajectory data on different robotic platforms and evaluate several baseline models. Experimental results demonstrate that the GM-100 tasks are 1) feasible to execute and 2) sufficiently challenging to effectively differentiate the performance of current VLA models. Our data and code are available at https://rhos.ai/research/gm-100.
Vision-Centric Activation and Coordination for Multimodal Large Language Models
Oct 16, 2025Multimodal large language models (MLLMs) integrate image features from visual encoders with LLMs, demonstrating advanced comprehension capabilities. However, mainstream MLLMs are solely supervised by the next-token prediction of textual tokens, neglecting critical vision-centric information essential for analytical abilities. To track this dilemma, we introduce VaCo, which optimizes MLLM representations through Vision-Centric activation and Coordination from multiple vision foundation models (VFMs). VaCo introduces visual discriminative alignment to integrate task-aware perceptual features extracted from VFMs, thereby unifying the optimization of both textual and visual outputs in MLLMs. Specifically, we incorporate the learnable Modular Task Queries (MTQs) and Visual Alignment Layers (VALs) into MLLMs, activating specific visual signals under the supervision of diverse VFMs. To coordinate representation conflicts across VFMs, the crafted Token Gateway Mask (TGM) restricts the information flow among multiple groups of MTQs. Extensive experiments demonstrate that VaCo significantly improves the performance of different MLLMs on various benchmarks, showcasing its superior capabilities in visual comprehension.
VideoMAR: Autoregressive Video Generatio with Continuous Tokens
Jun 18, 2025Masked-based autoregressive models have demonstrated promising image generation capability in continuous space. However, their potential for video generation remains under-explored. In this paper, we propose \textbf{VideoMAR}, a concise and efficient decoder-only autoregressive image-to-video model with continuous tokens, composing temporal frame-by-frame and spatial masked generation. We first identify temporal causality and spatial bi-directionality as the first principle of video AR models, and propose the next-frame diffusion loss for the integration of mask and video generation. Besides, the huge cost and difficulty of long sequence autoregressive modeling is a basic but crucial issue. To this end, we propose the temporal short-to-long curriculum learning and spatial progressive resolution training, and employ progressive temperature strategy at inference time to mitigate the accumulation error. Furthermore, VideoMAR replicates several unique capacities of language models to video generation. It inherently bears high efficiency due to simultaneous temporal-wise KV cache and spatial-wise parallel generation, and presents the capacity of spatial and temporal extrapolation via 3D rotary embeddings. On the VBench-I2V benchmark, VideoMAR surpasses the previous state-of-the-art (Cosmos I2V) while requiring significantly fewer parameters ($9.3\%$), training data ($0.5\%$), and GPU resources ($0.2\%$).
Aligned Better, Listen Better for Audio-Visual Large Language Models
Apr 02, 2025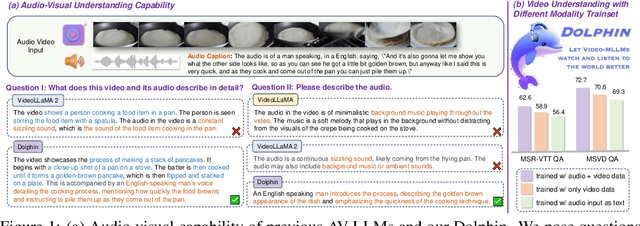

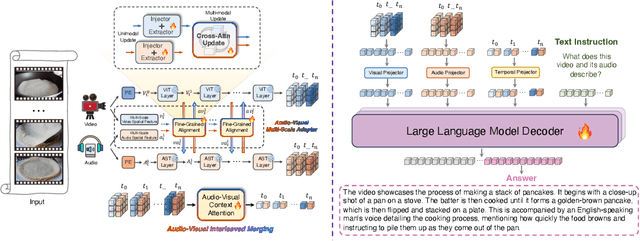
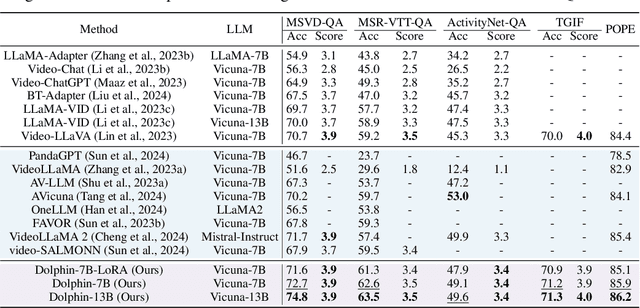
Audio is essential for multimodal video understanding. On the one hand, video inherently contains audio, which supplies complementary information to vision. Besides, video large language models (Video-LLMs) can encounter many audio-centric settings. However, existing Video-LLMs and Audio-Visual Large Language Models (AV-LLMs) exhibit deficiencies in exploiting audio information, leading to weak understanding and hallucinations. To solve the issues, we delve into the model architecture and dataset. (1) From the architectural perspective, we propose a fine-grained AV-LLM, namely Dolphin. The concurrent alignment of audio and visual modalities in both temporal and spatial dimensions ensures a comprehensive and accurate understanding of videos. Specifically, we devise an audio-visual multi-scale adapter for multi-scale information aggregation, which achieves spatial alignment. For temporal alignment, we propose audio-visual interleaved merging. (2) From the dataset perspective, we curate an audio-visual caption and instruction-tuning dataset, called AVU. It comprises 5.2 million diverse, open-ended data tuples (video, audio, question, answer) and introduces a novel data partitioning strategy. Extensive experiments show our model not only achieves remarkable performance in audio-visual understanding, but also mitigates potential hallucinations.
Benchmarking Large Vision-Language Models via Directed Scene Graph for Comprehensive Image Captioning
Dec 12, 2024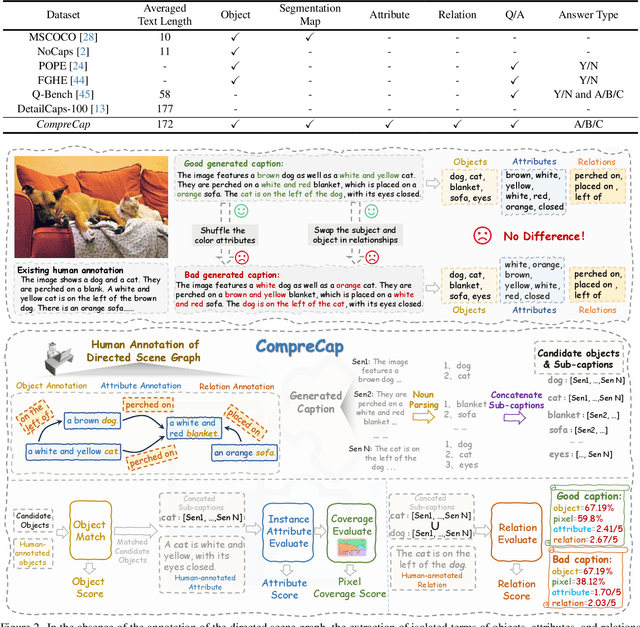
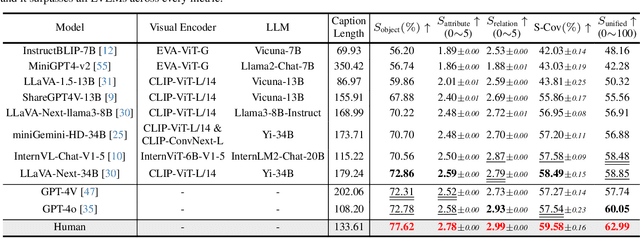

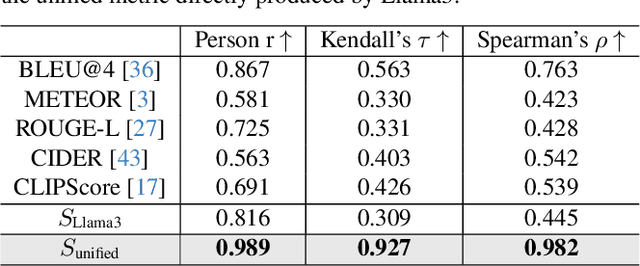
Generating detailed captions comprehending text-rich visual content in images has received growing attention for Large Vision-Language Models (LVLMs). However, few studies have developed benchmarks specifically tailored for detailed captions to measure their accuracy and comprehensiveness. In this paper, we introduce a detailed caption benchmark, termed as CompreCap, to evaluate the visual context from a directed scene graph view. Concretely, we first manually segment the image into semantically meaningful regions (i.e., semantic segmentation mask) according to common-object vocabulary, while also distinguishing attributes of objects within all those regions. Then directional relation labels of these objects are annotated to compose a directed scene graph that can well encode rich compositional information of the image. Based on our directed scene graph, we develop a pipeline to assess the generated detailed captions from LVLMs on multiple levels, including the object-level coverage, the accuracy of attribute descriptions, the score of key relationships, etc. Experimental results on the CompreCap dataset confirm that our evaluation method aligns closely with human evaluation scores across LVLMs.
Learning Visual Generative Priors without Text
Dec 10, 2024



Although text-to-image (T2I) models have recently thrived as visual generative priors, their reliance on high-quality text-image pairs makes scaling up expensive. We argue that grasping the cross-modality alignment is not a necessity for a sound visual generative prior, whose focus should be on texture modeling. Such a philosophy inspires us to study image-to-image (I2I) generation, where models can learn from in-the-wild images in a self-supervised manner. We first develop a pure vision-based training framework, Lumos, and confirm the feasibility and the scalability of learning I2I models. We then find that, as an upstream task of T2I, our I2I model serves as a more foundational visual prior and achieves on-par or better performance than existing T2I models using only 1/10 text-image pairs for fine-tuning. We further demonstrate the superiority of I2I priors over T2I priors on some text-irrelevant visual generative tasks, like image-to-3D and image-to-video.