 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMotionStone: Decoupled Motion Intensity Modulation with Diffusion Transformer for Image-to-Video Generation
Dec 08, 2024



The image-to-video (I2V) generation is conditioned on the static image, which has been enhanced recently by the motion intensity as an additional control signal. These motion-aware models are appealing to generate diverse motion patterns, yet there lacks a reliable motion estimator for training such models on large-scale video set in the wild. Traditional metrics, e.g., SSIM or optical flow, are hard to generalize to arbitrary videos, while, it is very tough for human annotators to label the abstract motion intensity neither. Furthermore, the motion intensity shall reveal both local object motion and global camera movement, which has not been studied before. This paper addresses the challenge with a new motion estimator, capable of measuring the decoupled motion intensities of objects and cameras in video. We leverage the contrastive learning on randomly paired videos and distinguish the video with greater motion intensity. Such a paradigm is friendly for annotation and easy to scale up to achieve stable performance on motion estimation. We then present a new I2V model, named MotionStone, developed with the decoupled motion estimator. Experimental results demonstrate the stability of the proposed motion estimator and the state-of-the-art performance of MotionStone on I2V generation. These advantages warrant the decoupled motion estimator to serve as a general plug-in enhancer for both data processing and video generation training.
Text Prompt is Not Enough: Sound Event Enhanced Prompt Adapter for Target Style Audio Generation
Sep 14, 2024



Current mainstream audio generation methods primarily rely on simple text prompts, often failing to capture the nuanced details necessary for multi-style audio generation. To address this limitation, the Sound Event Enhanced Prompt Adapter is proposed. Unlike traditional static global style transfer, this method extracts style embedding through cross-attention between text and reference audio for adaptive style control. Adaptive layer normalization is then utilized to enhance the model's capacity to express multiple styles. Additionally, the Sound Event Reference Style Transfer Dataset (SERST) is introduced for the proposed target style audio generation task, enabling dual-prompt audio generation using both text and audio references. Experimental results demonstrate the robustness of the model, achieving state-of-the-art Fr\'echet Distance of 26.94 and KL Divergence of 1.82, surpassing Tango, AudioLDM, and AudioGen. Furthermore, the generated audio shows high similarity to its corresponding audio reference. The demo, code, and dataset are publicly available.
Prototype Clustered Diffusion Models for Versatile Inverse Problems
Jul 13, 2024



Diffusion models have made remarkable progress in solving various inverse problems, attributing to the generative modeling capability of the data manifold. Posterior sampling from the conditional score function enable the precious data consistency certified by the measurement-based likelihood term. However, most prevailing approaches confined to the deterministic deterioration process of the measurement model, regardless of capricious unpredictable disturbance in real-world sceneries. To address this obstacle, we show that the measurement-based likelihood can be renovated with restoration-based likelihood via the opposite probabilistic graphic direction, licencing the patronage of various off-the-shelf restoration models and extending the strictly deterministic deterioration process to adaptable clustered processes with the supposed prototype, in what we call restorer guidance. Particularly, assembled with versatile prototypes optionally, we can resolve inverse problems with bunch of choices for assorted sample quality and realize the proficient deterioration control with assured realistic. We show that our work can be formally analogous to the transition from classifier guidance to classifier-free guidance in the field of inverse problem solver. Experiments on multifarious inverse problems demonstrate the effectiveness of our method, including image dehazing, rain streak removal, and motion deblurring.
Unleashing the Potential of Unsupervised Pre-Training with Intra-Identity Regularization for Person Re-Identification
Dec 01, 2021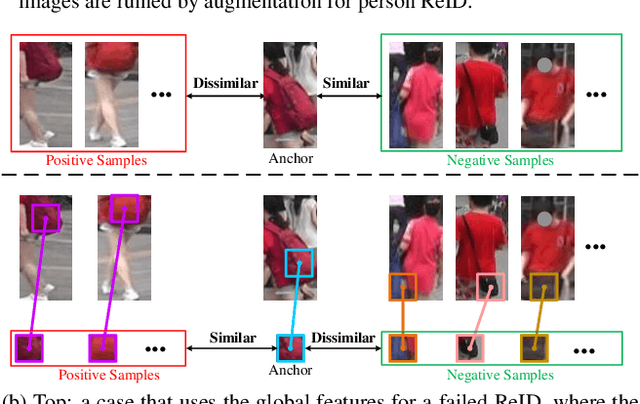
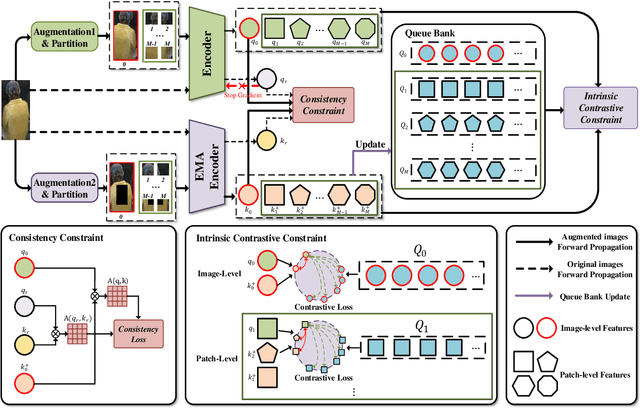
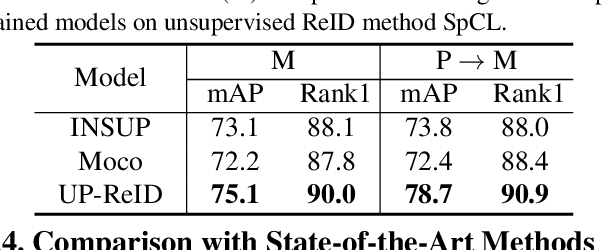
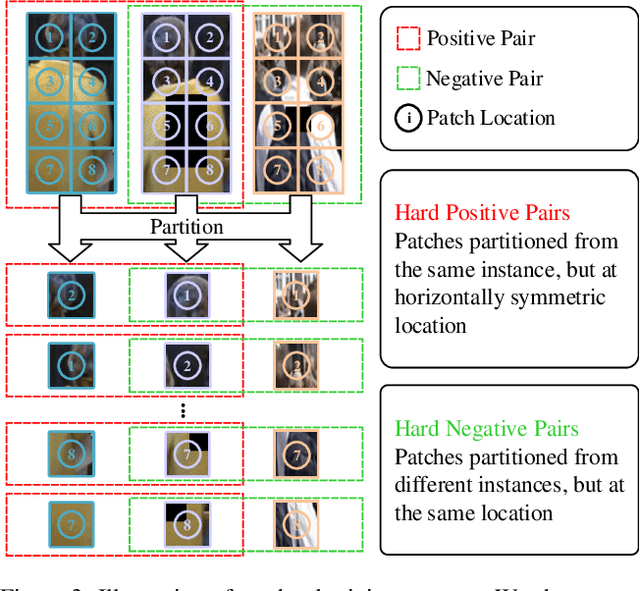
Existing person re-identification (ReID) methods typically directly load the pre-trained ImageNet weights for initialization. However, as a fine-grained classification task, ReID is more challenging and exists a large domain gap between ImageNet classification. Inspired by the great success of self-supervised representation learning with contrastive objectives, in this paper, we design an Unsupervised Pre-training framework for ReID based on the contrastive learning (CL) pipeline, dubbed UP-ReID. During the pre-training, we attempt to address two critical issues for learning fine-grained ReID features: (1) the augmentations in CL pipeline may distort the discriminative clues in person images. (2) the fine-grained local features of person images are not fully-explored. Therefore, we introduce an intra-identity (I$^2$-)regularization in the UP-ReID, which is instantiated as two constraints coming from global image aspect and local patch aspect: a global consistency is enforced between augmented and original person images to increase robustness to augmentation, while an intrinsic contrastive constraint among local patches of each image is employed to fully explore the local discriminative clues. Extensive experiments on multiple popular Re-ID datasets, including PersonX, Market1501, CUHK03, and MSMT17, demonstrate that our UP-ReID pre-trained model can significantly benefit the downstream ReID fine-tuning and achieve state-of-the-art performance. Codes and models will be released to https://github.com/Frost-Yang-99/UP-ReID.