 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoDance: An Unbind-Rebind Paradigm for Robust Multi-Subject Animation
Jan 16, 2026Character image animation is gaining significant importance across various domains, driven by the demand for robust and flexible multi-subject rendering. While existing methods excel in single-person animation, they struggle to handle arbitrary subject counts, diverse character types, and spatial misalignment between the reference image and the driving poses. We attribute these limitations to an overly rigid spatial binding that forces strict pixel-wise alignment between the pose and reference, and an inability to consistently rebind motion to intended subjects. To address these challenges, we propose CoDance, a novel Unbind-Rebind framework that enables the animation of arbitrary subject counts, types, and spatial configurations conditioned on a single, potentially misaligned pose sequence. Specifically, the Unbind module employs a novel pose shift encoder to break the rigid spatial binding between the pose and the reference by introducing stochastic perturbations to both poses and their latent features, thereby compelling the model to learn a location-agnostic motion representation. To ensure precise control and subject association, we then devise a Rebind module, leveraging semantic guidance from text prompts and spatial guidance from subject masks to direct the learned motion to intended characters. Furthermore, to facilitate comprehensive evaluation, we introduce a new multi-subject CoDanceBench. Extensive experiments on CoDanceBench and existing datasets show that CoDance achieves SOTA performance, exhibiting remarkable generalization across diverse subjects and spatial layouts. The code and weights will be open-sourced.
PhysRVG: Physics-Aware Unified Reinforcement Learning for Video Generative Models
Jan 16, 2026Physical principles are fundamental to realistic visual simulation, but remain a significant oversight in transformer-based video generation. This gap highlights a critical limitation in rendering rigid body motion, a core tenet of classical mechanics. While computer graphics and physics-based simulators can easily model such collisions using Newton formulas, modern pretrain-finetune paradigms discard the concept of object rigidity during pixel-level global denoising. Even perfectly correct mathematical constraints are treated as suboptimal solutions (i.e., conditions) during model optimization in post-training, fundamentally limiting the physical realism of generated videos. Motivated by these considerations, we introduce, for the first time, a physics-aware reinforcement learning paradigm for video generation models that enforces physical collision rules directly in high-dimensional spaces, ensuring the physics knowledge is strictly applied rather than treated as conditions. Subsequently, we extend this paradigm to a unified framework, termed Mimicry-Discovery Cycle (MDcycle), which allows substantial fine-tuning while fully preserving the model's ability to leverage physics-grounded feedback. To validate our approach, we construct new benchmark PhysRVGBench and perform extensive qualitative and quantitative experiments to thoroughly assess its effectiveness.
VideoMAR: Autoregressive Video Generatio with Continuous Tokens
Jun 18, 2025Masked-based autoregressive models have demonstrated promising image generation capability in continuous space. However, their potential for video generation remains under-explored. In this paper, we propose \textbf{VideoMAR}, a concise and efficient decoder-only autoregressive image-to-video model with continuous tokens, composing temporal frame-by-frame and spatial masked generation. We first identify temporal causality and spatial bi-directionality as the first principle of video AR models, and propose the next-frame diffusion loss for the integration of mask and video generation. Besides, the huge cost and difficulty of long sequence autoregressive modeling is a basic but crucial issue. To this end, we propose the temporal short-to-long curriculum learning and spatial progressive resolution training, and employ progressive temperature strategy at inference time to mitigate the accumulation error. Furthermore, VideoMAR replicates several unique capacities of language models to video generation. It inherently bears high efficiency due to simultaneous temporal-wise KV cache and spatial-wise parallel generation, and presents the capacity of spatial and temporal extrapolation via 3D rotary embeddings. On the VBench-I2V benchmark, VideoMAR surpasses the previous state-of-the-art (Cosmos I2V) while requiring significantly fewer parameters ($9.3\%$), training data ($0.5\%$), and GPU resources ($0.2\%$).
Ming-Omni: A Unified Multimodal Model for Perception and Generation
Jun 11, 2025



We propose Ming-Omni, a unified multimodal model capable of processing images, text, audio, and video, while demonstrating strong proficiency in both speech and image generation. Ming-Omni employs dedicated encoders to extract tokens from different modalities, which are then processed by Ling, an MoE architecture equipped with newly proposed modality-specific routers. This design enables a single model to efficiently process and fuse multimodal inputs within a unified framework, thereby facilitating diverse tasks without requiring separate models, task-specific fine-tuning, or structural redesign. Importantly, Ming-Omni extends beyond conventional multimodal models by supporting audio and image generation. This is achieved through the integration of an advanced audio decoder for natural-sounding speech and Ming-Lite-Uni for high-quality image generation, which also allow the model to engage in context-aware chatting, perform text-to-speech conversion, and conduct versatile image editing. Our experimental results showcase Ming-Omni offers a powerful solution for unified perception and generation across all modalities. Notably, our proposed Ming-Omni is the first open-source model we are aware of to match GPT-4o in modality support, and we release all code and model weights to encourage further research and development in the community.
Hi-VAE: Efficient Video Autoencoding with Global and Detailed Motion
Jun 08, 2025Recent breakthroughs in video autoencoders (Video AEs) have advanced video generation, but existing methods fail to efficiently model spatio-temporal redundancies in dynamics, resulting in suboptimal compression factors. This shortfall leads to excessive training costs for downstream tasks. To address this, we introduce Hi-VAE, an efficient video autoencoding framework that hierarchically encode coarse-to-fine motion representations of video dynamics and formulate the decoding process as a conditional generation task. Specifically, Hi-VAE decomposes video dynamics into two latent spaces: Global Motion, capturing overarching motion patterns, and Detailed Motion, encoding high-frequency spatial details. Using separate self-supervised motion encoders, we compress video latents into compact motion representations to reduce redundancy significantly. A conditional diffusion decoder then reconstructs videos by combining hierarchical global and detailed motions, enabling high-fidelity video reconstructions. Extensive experiments demonstrate that Hi-VAE achieves a high compression factor of 1428$\times$, almost 30$\times$ higher than baseline methods (e.g., Cosmos-VAE at 48$\times$), validating the efficiency of our approach. Meanwhile, Hi-VAE maintains high reconstruction quality at such high compression rates and performs effectively in downstream generative tasks. Moreover, Hi-VAE exhibits interpretability and scalability, providing new perspectives for future exploration in video latent representation and generation.
Dimension-Reduction Attack! Video Generative Models are Experts on Controllable Image Synthesis
May 29, 2025Video generative models can be regarded as world simulators due to their ability to capture dynamic, continuous changes inherent in real-world environments. These models integrate high-dimensional information across visual, temporal, spatial, and causal dimensions, enabling predictions of subjects in various status. A natural and valuable research direction is to explore whether a fully trained video generative model in high-dimensional space can effectively support lower-dimensional tasks such as controllable image generation. In this work, we propose a paradigm for video-to-image knowledge compression and task adaptation, termed \textit{Dimension-Reduction Attack} (\texttt{DRA-Ctrl}), which utilizes the strengths of video models, including long-range context modeling and flatten full-attention, to perform various generation tasks. Specially, to address the challenging gap between continuous video frames and discrete image generation, we introduce a mixup-based transition strategy that ensures smooth adaptation. Moreover, we redesign the attention structure with a tailored masking mechanism to better align text prompts with image-level control. Experiments across diverse image generation tasks, such as subject-driven and spatially conditioned generation, show that repurposed video models outperform those trained directly on images. These results highlight the untapped potential of large-scale video generators for broader visual applications. \texttt{DRA-Ctrl} provides new insights into reusing resource-intensive video models and lays foundation for future unified generative models across visual modalities. The project page is https://dra-ctrl-2025.github.io/DRA-Ctrl/.
Ming-Lite-Uni: Advancements in Unified Architecture for Natural Multimodal Interaction
May 05, 2025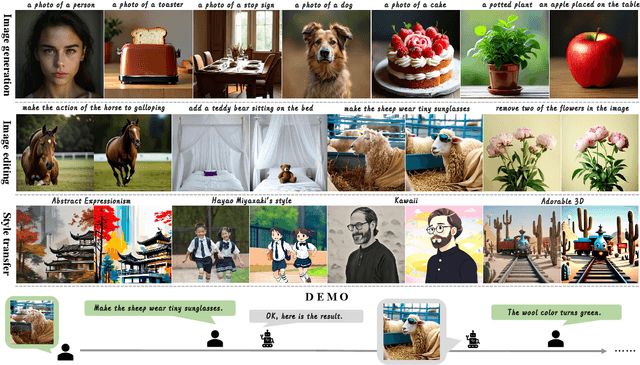

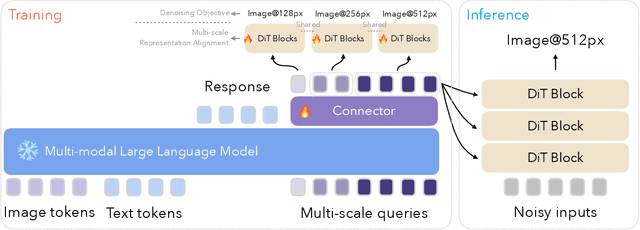
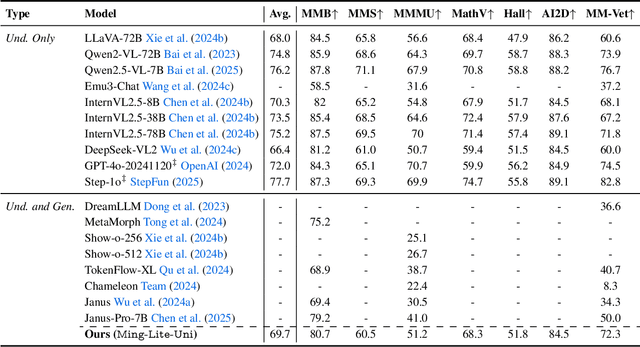
We introduce Ming-Lite-Uni, an open-source multimodal framework featuring a newly designed unified visual generator and a native multimodal autoregressive model tailored for unifying vision and language. Specifically, this project provides an open-source implementation of the integrated MetaQueries and M2-omni framework, while introducing the novel multi-scale learnable tokens and multi-scale representation alignment strategy. By leveraging a fixed MLLM and a learnable diffusion model, Ming-Lite-Uni enables native multimodal AR models to perform both text-to-image generation and instruction based image editing tasks, expanding their capabilities beyond pure visual understanding. Our experimental results demonstrate the strong performance of Ming-Lite-Uni and illustrate the impressive fluid nature of its interactive process. All code and model weights are open-sourced to foster further exploration within the community. Notably, this work aligns with concurrent multimodal AI milestones - such as ChatGPT-4o with native image generation updated in March 25, 2025 - underscoring the broader significance of unified models like Ming-Lite-Uni on the path toward AGI. Ming-Lite-Uni is in alpha stage and will soon be further refined.
DreamRelation: Relation-Centric Video Customization
Mar 10, 2025Relational video customization refers to the creation of personalized videos that depict user-specified relations between two subjects, a crucial task for comprehending real-world visual content. While existing methods can personalize subject appearances and motions, they still struggle with complex relational video customization, where precise relational modeling and high generalization across subject categories are essential. The primary challenge arises from the intricate spatial arrangements, layout variations, and nuanced temporal dynamics inherent in relations; consequently, current models tend to overemphasize irrelevant visual details rather than capturing meaningful interactions. To address these challenges, we propose DreamRelation, a novel approach that personalizes relations through a small set of exemplar videos, leveraging two key components: Relational Decoupling Learning and Relational Dynamics Enhancement. First, in Relational Decoupling Learning, we disentangle relations from subject appearances using relation LoRA triplet and hybrid mask training strategy, ensuring better generalization across diverse relationships. Furthermore, we determine the optimal design of relation LoRA triplet by analyzing the distinct roles of the query, key, and value features within MM-DiT's attention mechanism, making DreamRelation the first relational video generation framework with explainable components. Second, in Relational Dynamics Enhancement, we introduce space-time relational contrastive loss, which prioritizes relational dynamics while minimizing the reliance on detailed subject appearances. Extensive experiments demonstrate that DreamRelation outperforms state-of-the-art methods in relational video customization. Code and models will be made publicly available.
Benchmarking Large Vision-Language Models via Directed Scene Graph for Comprehensive Image Captioning
Dec 12, 2024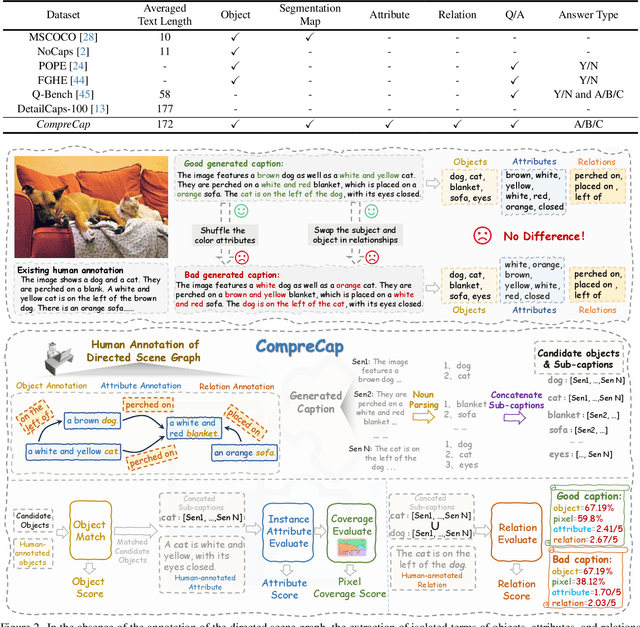
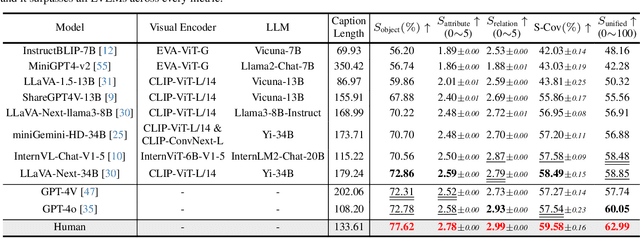

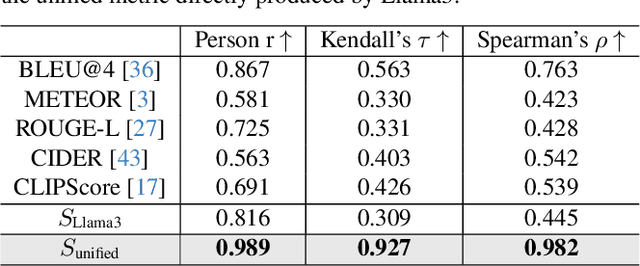
Generating detailed captions comprehending text-rich visual content in images has received growing attention for Large Vision-Language Models (LVLMs). However, few studies have developed benchmarks specifically tailored for detailed captions to measure their accuracy and comprehensiveness. In this paper, we introduce a detailed caption benchmark, termed as CompreCap, to evaluate the visual context from a directed scene graph view. Concretely, we first manually segment the image into semantically meaningful regions (i.e., semantic segmentation mask) according to common-object vocabulary, while also distinguishing attributes of objects within all those regions. Then directional relation labels of these objects are annotated to compose a directed scene graph that can well encode rich compositional information of the image. Based on our directed scene graph, we develop a pipeline to assess the generated detailed captions from LVLMs on multiple levels, including the object-level coverage, the accuracy of attribute descriptions, the score of key relationships, etc. Experimental results on the CompreCap dataset confirm that our evaluation method aligns closely with human evaluation scores across LVLMs.
MotionStone: Decoupled Motion Intensity Modulation with Diffusion Transformer for Image-to-Video Generation
Dec 08, 2024



The image-to-video (I2V) generation is conditioned on the static image, which has been enhanced recently by the motion intensity as an additional control signal. These motion-aware models are appealing to generate diverse motion patterns, yet there lacks a reliable motion estimator for training such models on large-scale video set in the wild. Traditional metrics, e.g., SSIM or optical flow, are hard to generalize to arbitrary videos, while, it is very tough for human annotators to label the abstract motion intensity neither. Furthermore, the motion intensity shall reveal both local object motion and global camera movement, which has not been studied before. This paper addresses the challenge with a new motion estimator, capable of measuring the decoupled motion intensities of objects and cameras in video. We leverage the contrastive learning on randomly paired videos and distinguish the video with greater motion intensity. Such a paradigm is friendly for annotation and easy to scale up to achieve stable performance on motion estimation. We then present a new I2V model, named MotionStone, developed with the decoupled motion estimator. Experimental results demonstrate the stability of the proposed motion estimator and the state-of-the-art performance of MotionStone on I2V generation. These advantages warrant the decoupled motion estimator to serve as a general plug-in enhancer for both data processing and video generation training.