 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText Prompt is Not Enough: Sound Event Enhanced Prompt Adapter for Target Style Audio Generation
Sep 14, 2024



Current mainstream audio generation methods primarily rely on simple text prompts, often failing to capture the nuanced details necessary for multi-style audio generation. To address this limitation, the Sound Event Enhanced Prompt Adapter is proposed. Unlike traditional static global style transfer, this method extracts style embedding through cross-attention between text and reference audio for adaptive style control. Adaptive layer normalization is then utilized to enhance the model's capacity to express multiple styles. Additionally, the Sound Event Reference Style Transfer Dataset (SERST) is introduced for the proposed target style audio generation task, enabling dual-prompt audio generation using both text and audio references. Experimental results demonstrate the robustness of the model, achieving state-of-the-art Fr\'echet Distance of 26.94 and KL Divergence of 1.82, surpassing Tango, AudioLDM, and AudioGen. Furthermore, the generated audio shows high similarity to its corresponding audio reference. The demo, code, and dataset are publicly available.
Does Current Deepfake Audio Detection Model Effectively Detect ALM-based Deepfake Audio?
Aug 20, 2024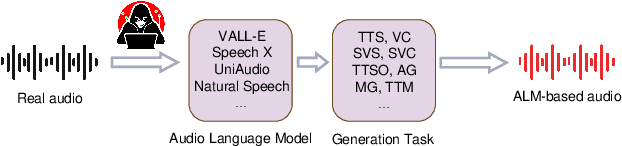
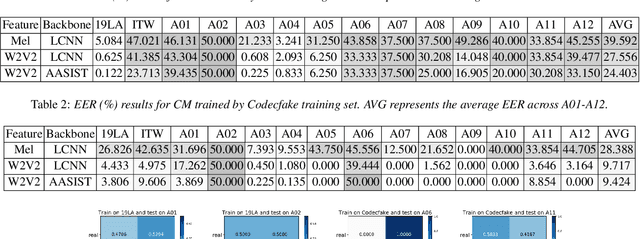

Currently, Audio Language Models (ALMs) are rapidly advancing due to the developments in large language models and audio neural codecs. These ALMs have significantly lowered the barrier to creating deepfake audio, generating highly realistic and diverse types of deepfake audio, which pose severe threats to society. Consequently, effective audio deepfake detection technologies to detect ALM-based audio have become increasingly critical. This paper investigate the effectiveness of current countermeasure (CM) against ALM-based audio. Specifically, we collect 12 types of the latest ALM-based deepfake audio and utilizing the latest CMs to evaluate. Our findings reveal that the latest codec-trained CM can effectively detect ALM-based audio, achieving 0% equal error rate under most ALM test conditions, which exceeded our expectations. This indicates promising directions for future research in ALM-based deepfake audio detection.