 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhyAVBench: A Challenging Audio Physics-Sensitivity Benchmark for Physically Grounded Text-to-Audio-Video Generation
Dec 30, 2025Text-to-audio-video (T2AV) generation underpins a wide range of applications demanding realistic audio-visual content, including virtual reality, world modeling, gaming, and filmmaking. However, existing T2AV models remain incapable of generating physically plausible sounds, primarily due to their limited understanding of physical principles. To situate current research progress, we present PhyAVBench, a challenging audio physics-sensitivity benchmark designed to systematically evaluate the audio physics grounding capabilities of existing T2AV models. PhyAVBench comprises 1,000 groups of paired text prompts with controlled physical variables that implicitly induce sound variations, enabling a fine-grained assessment of models' sensitivity to changes in underlying acoustic conditions. We term this evaluation paradigm the Audio-Physics Sensitivity Test (APST). Unlike prior benchmarks that primarily focus on audio-video synchronization, PhyAVBench explicitly evaluates models' understanding of the physical mechanisms underlying sound generation, covering 6 major audio physics dimensions, 4 daily scenarios (music, sound effects, speech, and their mix), and 50 fine-grained test points, ranging from fundamental aspects such as sound diffraction to more complex phenomena, e.g., Helmholtz resonance. Each test point consists of multiple groups of paired prompts, where each prompt is grounded by at least 20 newly recorded or collected real-world videos, thereby minimizing the risk of data leakage during model pre-training. Both prompts and videos are iteratively refined through rigorous human-involved error correction and quality control to ensure high quality. We argue that only models with a genuine grasp of audio-related physical principles can generate physically consistent audio-visual content. We hope PhyAVBench will stimulate future progress in this critical yet largely unexplored domain.
Audio-Thinker: Guiding Audio Language Model When and How to Think via Reinforcement Learning
Aug 12, 2025Recent advancements in large language models, multimodal large language models, and large audio language models (LALMs) have significantly improved their reasoning capabilities through reinforcement learning with rule-based rewards. However, the explicit reasoning process has yet to show significant benefits for audio question answering, and effectively leveraging deep reasoning remains an open challenge, with LALMs still falling short of human-level auditory-language reasoning. To address these limitations, we propose Audio-Thinker, a reinforcement learning framework designed to enhance the reasoning capabilities of LALMs, with a focus on improving adaptability, consistency, and effectiveness. Our approach introduces an adaptive think accuracy reward, enabling the model to adjust its reasoning strategies based on task complexity dynamically. Furthermore, we incorporate an external reward model to evaluate the overall consistency and quality of the reasoning process, complemented by think-based rewards that help the model distinguish between valid and flawed reasoning paths during training. Experimental results demonstrate that our Audio-Thinker model outperforms existing reasoning-oriented LALMs across various benchmark tasks, exhibiting superior reasoning and generalization capabilities.
Mitigating Audiovisual Mismatch in Visual-Guide Audio Captioning
May 28, 2025Current vision-guided audio captioning systems frequently fail to address audiovisual misalignment in real-world scenarios, such as dubbed content or off-screen sounds. To bridge this critical gap, we present an entropy-aware gated fusion framework that dynamically modulates visual information flow through cross-modal uncertainty quantification. Our novel approach employs attention entropy analysis in cross-attention layers to automatically identify and suppress misleading visual cues during modal fusion. Complementing this architecture, we develop a batch-wise audiovisual shuffling technique that generates synthetic mismatched training pairs, greatly enhancing model resilience against alignment noise. Evaluations on the AudioCaps benchmark demonstrate our system's superior performance over existing baselines, especially in mismatched modality scenarios. Furthermore, our solution demonstrates an approximately 6x improvement in inference speed compared to the baseline.
Information-Theoretic Complementary Prompts for Improved Continual Text Classification
May 27, 2025Continual Text Classification (CTC) aims to continuously classify new text data over time while minimizing catastrophic forgetting of previously acquired knowledge. However, existing methods often focus on task-specific knowledge, overlooking the importance of shared, task-agnostic knowledge. Inspired by the complementary learning systems theory, which posits that humans learn continually through the interaction of two systems -- the hippocampus, responsible for forming distinct representations of specific experiences, and the neocortex, which extracts more general and transferable representations from past experiences -- we introduce Information-Theoretic Complementary Prompts (InfoComp), a novel approach for CTC. InfoComp explicitly learns two distinct prompt spaces: P(rivate)-Prompt and S(hared)-Prompt. These respectively encode task-specific and task-invariant knowledge, enabling models to sequentially learn classification tasks without relying on data replay. To promote more informative prompt learning, InfoComp uses an information-theoretic framework that maximizes mutual information between different parameters (or encoded representations). Within this framework, we design two novel loss functions: (1) to strengthen the accumulation of task-specific knowledge in P-Prompt, effectively mitigating catastrophic forgetting, and (2) to enhance the retention of task-invariant knowledge in S-Prompt, improving forward knowledge transfer. Extensive experiments on diverse CTC benchmarks show that our approach outperforms previous state-of-the-art methods.
Hearing from Silence: Reasoning Audio Descriptions from Silent Videos via Vision-Language Model
May 19, 2025Humans can intuitively infer sounds from silent videos, but whether multimodal large language models can perform modal-mismatch reasoning without accessing target modalities remains relatively unexplored. Current text-assisted-video-to-audio (VT2A) methods excel in video foley tasks but struggle to acquire audio descriptions during inference. We introduce the task of Reasoning Audio Descriptions from Silent Videos (SVAD) to address this challenge and investigate vision-language models' (VLMs) capabilities on this task. To further enhance the VLMs' reasoning capacity for the SVAD task, we construct a CoT-AudioCaps dataset and propose a Chain-of-Thought-based supervised fine-tuning strategy. Experiments on SVAD and subsequent VT2A tasks demonstrate our method's effectiveness in two key aspects: significantly improving VLMs' modal-mismatch reasoning for SVAD and effectively addressing the challenge of acquiring audio descriptions during VT2A inference.
Deconfounded Reasoning for Multimodal Fake News Detection via Causal Intervention
Apr 12, 2025



The rapid growth of social media has led to the widespread dissemination of fake news across multiple content forms, including text, images, audio, and video. Traditional unimodal detection methods fall short in addressing complex cross-modal manipulations; as a result, multimodal fake news detection has emerged as a more effective solution. However, existing multimodal approaches, especially in the context of fake news detection on social media, often overlook the confounders hidden within complex cross-modal interactions, leading models to rely on spurious statistical correlations rather than genuine causal mechanisms. In this paper, we propose the Causal Intervention-based Multimodal Deconfounded Detection (CIMDD) framework, which systematically models three types of confounders via a unified Structural Causal Model (SCM): (1) Lexical Semantic Confounder (LSC); (2) Latent Visual Confounder (LVC); (3) Dynamic Cross-Modal Coupling Confounder (DCCC). To mitigate the influence of these confounders, we specifically design three causal modules based on backdoor adjustment, frontdoor adjustment, and cross-modal joint intervention to block spurious correlations from different perspectives and achieve causal disentanglement of representations for deconfounded reasoning. Experimental results on the FakeSV and FVC datasets demonstrate that CIMDD significantly improves detection accuracy, outperforming state-of-the-art methods by 4.27% and 4.80%, respectively. Furthermore, extensive experimental results indicate that CIMDD exhibits strong generalization and robustness across diverse multimodal scenarios.
Exploring Modality Disruption in Multimodal Fake News Detection
Apr 12, 2025
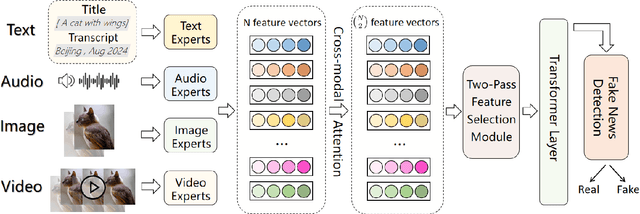
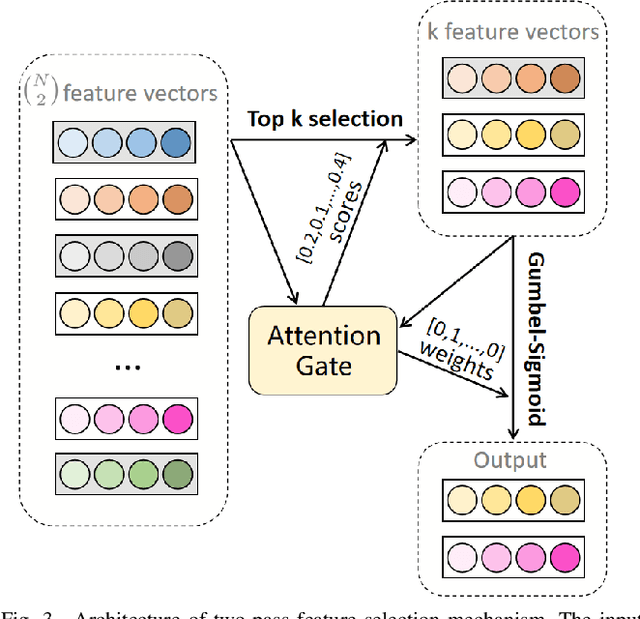
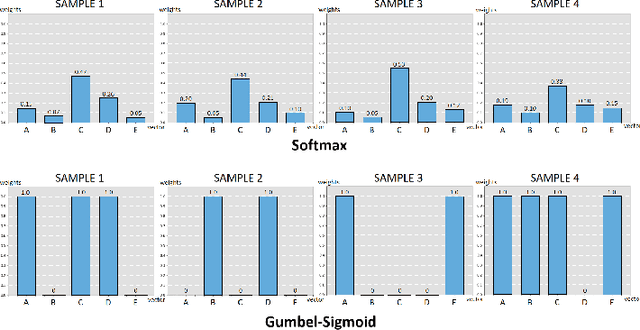
The rapid growth of social media has led to the widespread dissemination of fake news across multiple content forms, including text, images, audio, and video. Compared to unimodal fake news detection, multimodal fake news detection benefits from the increased availability of information across multiple modalities. However, in the context of social media, certain modalities in multimodal fake news detection tasks may contain disruptive or over-expressive information. These elements often include exaggerated or embellished content. We define this phenomenon as modality disruption and explore its impact on detection models through experiments. To address the issue of modality disruption in a targeted manner, we propose a multimodal fake news detection framework, FND-MoE. Additionally, we design a two-pass feature selection mechanism to further mitigate the impact of modality disruption. Extensive experiments on the FakeSV and FVC-2018 datasets demonstrate that FND-MoE significantly outperforms state-of-the-art methods, with accuracy improvements of 3.45% and 3.71% on the respective datasets compared to baseline models.
Lifelong Learning of Large Language Model based Agents: A Roadmap
Jan 13, 2025Lifelong learning, also known as continual or incremental learning, is a crucial component for advancing Artificial General Intelligence (AGI) by enabling systems to continuously adapt in dynamic environments. While large language models (LLMs) have demonstrated impressive capabilities in natural language processing, existing LLM agents are typically designed for static systems and lack the ability to adapt over time in response to new challenges. This survey is the first to systematically summarize the potential techniques for incorporating lifelong learning into LLM-based agents. We categorize the core components of these agents into three modules: the perception module for multimodal input integration, the memory module for storing and retrieving evolving knowledge, and the action module for grounded interactions with the dynamic environment. We highlight how these pillars collectively enable continuous adaptation, mitigate catastrophic forgetting, and improve long-term performance. This survey provides a roadmap for researchers and practitioners working to develop lifelong learning capabilities in LLM agents, offering insights into emerging trends, evaluation metrics, and application scenarios. Relevant literature and resources are available at \href{this url}{https://github.com/qianlima-lab/awesome-lifelong-llm-agent}.
Neural Codec Source Tracing: Toward Comprehensive Attribution in Open-Set Condition
Jan 11, 2025



Current research in audio deepfake detection is gradually transitioning from binary classification to multi-class tasks, referred as audio deepfake source tracing task. However, existing studies on source tracing consider only closed-set scenarios and have not considered the challenges posed by open-set conditions. In this paper, we define the Neural Codec Source Tracing (NCST) task, which is capable of performing open-set neural codec classification and interpretable ALM detection. Specifically, we constructed the ST-Codecfake dataset for the NCST task, which includes bilingual audio samples generated by 11 state-of-the-art neural codec methods and ALM-based out-ofdistribution (OOD) test samples. Furthermore, we establish a comprehensive source tracing benchmark to assess NCST models in open-set conditions. The experimental results reveal that although the NCST models perform well in in-distribution (ID) classification and OOD detection, they lack robustness in classifying unseen real audio. The ST-codecfake dataset and code are available.
Mel-Refine: A Plug-and-Play Approach to Refine Mel-Spectrogram in Audio Generation
Dec 11, 2024Text-to-audio (TTA) model is capable of generating diverse audio from textual prompts. However, most mainstream TTA models, which predominantly rely on Mel-spectrograms, still face challenges in producing audio with rich content. The intricate details and texture required in Mel-spectrograms for such audio often surpass the models' capacity, leading to outputs that are blurred or lack coherence. In this paper, we begin by investigating the critical role of U-Net in Mel-spectrogram generation. Our analysis shows that in U-Net structure, high-frequency components in skip-connections and the backbone influence texture and detail, while low-frequency components in the backbone are critical for the diffusion denoising process. We further propose ``Mel-Refine'', a plug-and-play approach that enhances Mel-spectrogram texture and detail by adjusting different component weights during inference. Our method requires no additional training or fine-tuning and is fully compatible with any diffusion-based TTA architecture. Experimental results show that our approach boosts performance metrics of the latest TTA model Tango2 by 25\%, demonstrating its effectiveness.