 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeconfounded Reasoning for Multimodal Fake News Detection via Causal Intervention
Apr 12, 2025



The rapid growth of social media has led to the widespread dissemination of fake news across multiple content forms, including text, images, audio, and video. Traditional unimodal detection methods fall short in addressing complex cross-modal manipulations; as a result, multimodal fake news detection has emerged as a more effective solution. However, existing multimodal approaches, especially in the context of fake news detection on social media, often overlook the confounders hidden within complex cross-modal interactions, leading models to rely on spurious statistical correlations rather than genuine causal mechanisms. In this paper, we propose the Causal Intervention-based Multimodal Deconfounded Detection (CIMDD) framework, which systematically models three types of confounders via a unified Structural Causal Model (SCM): (1) Lexical Semantic Confounder (LSC); (2) Latent Visual Confounder (LVC); (3) Dynamic Cross-Modal Coupling Confounder (DCCC). To mitigate the influence of these confounders, we specifically design three causal modules based on backdoor adjustment, frontdoor adjustment, and cross-modal joint intervention to block spurious correlations from different perspectives and achieve causal disentanglement of representations for deconfounded reasoning. Experimental results on the FakeSV and FVC datasets demonstrate that CIMDD significantly improves detection accuracy, outperforming state-of-the-art methods by 4.27% and 4.80%, respectively. Furthermore, extensive experimental results indicate that CIMDD exhibits strong generalization and robustness across diverse multimodal scenarios.
Exploring Modality Disruption in Multimodal Fake News Detection
Apr 12, 2025
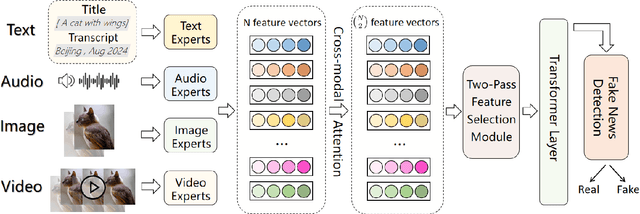
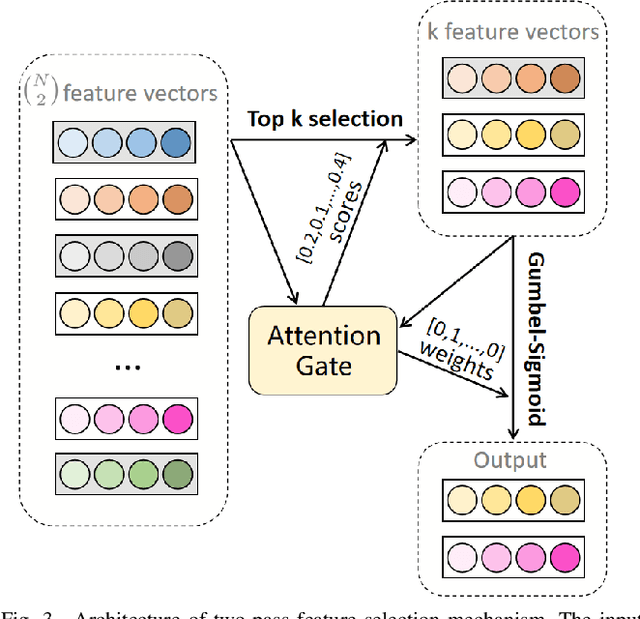
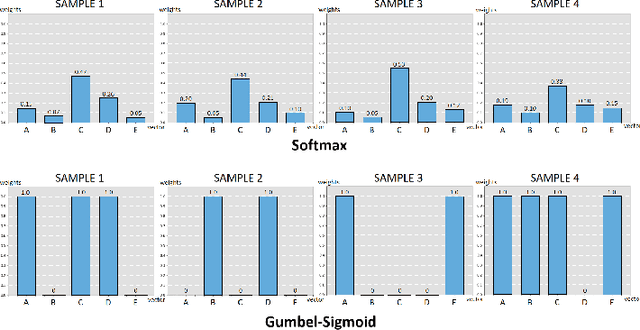
The rapid growth of social media has led to the widespread dissemination of fake news across multiple content forms, including text, images, audio, and video. Compared to unimodal fake news detection, multimodal fake news detection benefits from the increased availability of information across multiple modalities. However, in the context of social media, certain modalities in multimodal fake news detection tasks may contain disruptive or over-expressive information. These elements often include exaggerated or embellished content. We define this phenomenon as modality disruption and explore its impact on detection models through experiments. To address the issue of modality disruption in a targeted manner, we propose a multimodal fake news detection framework, FND-MoE. Additionally, we design a two-pass feature selection mechanism to further mitigate the impact of modality disruption. Extensive experiments on the FakeSV and FVC-2018 datasets demonstrate that FND-MoE significantly outperforms state-of-the-art methods, with accuracy improvements of 3.45% and 3.71% on the respective datasets compared to baseline models.
MTPareto: A MultiModal Targeted Pareto Framework for Fake News Detection
Jan 12, 2025Multimodal fake news detection is essential for maintaining the authenticity of Internet multimedia information. Significant differences in form and content of multimodal information lead to intensified optimization conflicts, hindering effective model training as well as reducing the effectiveness of existing fusion methods for bimodal. To address this problem, we propose the MTPareto framework to optimize multimodal fusion, using a Targeted Pareto(TPareto) optimization algorithm for fusion-level-specific objective learning with a certain focus. Based on the designed hierarchical fusion network, the algorithm defines three fusion levels with corresponding losses and implements all-modal-oriented Pareto gradient integration for each. This approach accomplishes superior multimodal fusion by utilizing the information obtained from intermediate fusion to provide positive effects to the entire process. Experiment results on FakeSV and FVC datasets show that the proposed framework outperforms baselines and the TPareto optimization algorithm achieves 2.40% and 1.89% accuracy improvement respectively.