 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuiding Perception-Reasoning Closer to Human in Blind Image Quality Assessment
Dec 18, 2025Humans assess image quality through a perception-reasoning cascade, integrating sensory cues with implicit reasoning to form self-consistent judgments. In this work, we investigate how a model can acquire both human-like and self-consistent reasoning capability for blind image quality assessment (BIQA). We first collect human evaluation data that capture several aspects of human perception-reasoning pipeline. Then, we adopt reinforcement learning, using human annotations as reward signals to guide the model toward human-like perception and reasoning. To enable the model to internalize self-consistent reasoning capability, we design a reward that drives the model to infer the image quality purely from self-generated descriptions. Empirically, our approach achieves score prediction performance comparable to state-of-the-art BIQA systems under general metrics, including Pearson and Spearman correlation coefficients. In addition to the rating score, we assess human-model alignment using ROUGE-1 to measure the similarity between model-generated and human perception-reasoning chains. On over 1,000 human-annotated samples, our model reaches a ROUGE-1 score of 0.512 (cf. 0.443 for baseline), indicating substantial coverage of human explanations and marking a step toward human-like interpretable reasoning in BIQA.
MedKGent: A Large Language Model Agent Framework for Constructing Temporally Evolving Medical Knowledge Graph
Aug 17, 2025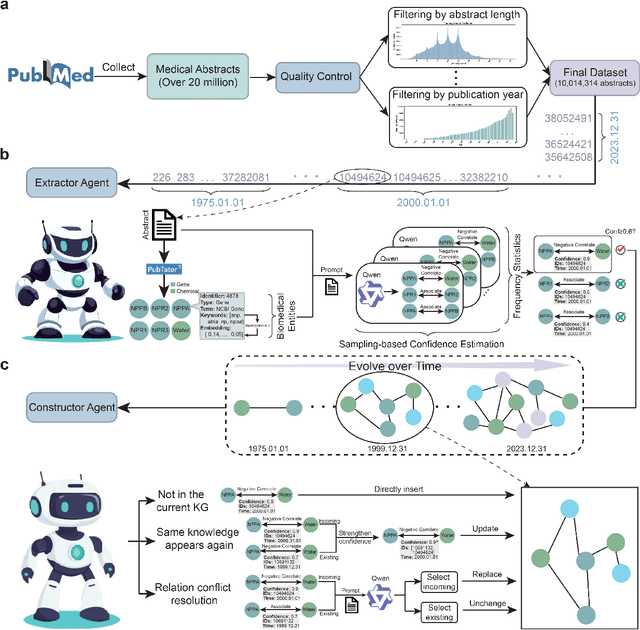
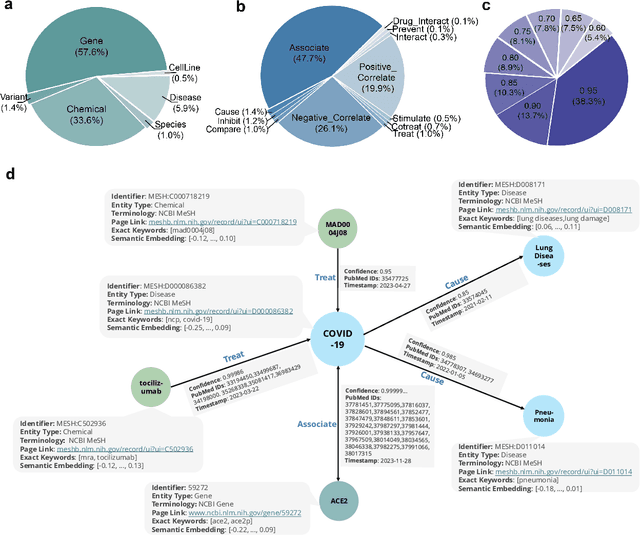
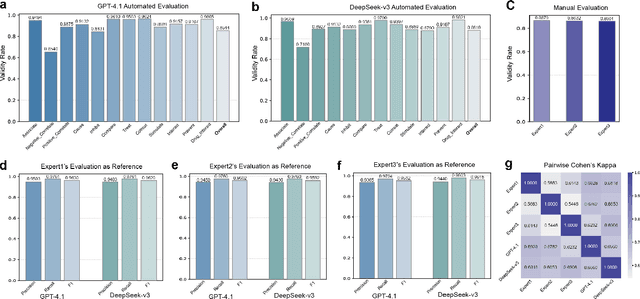
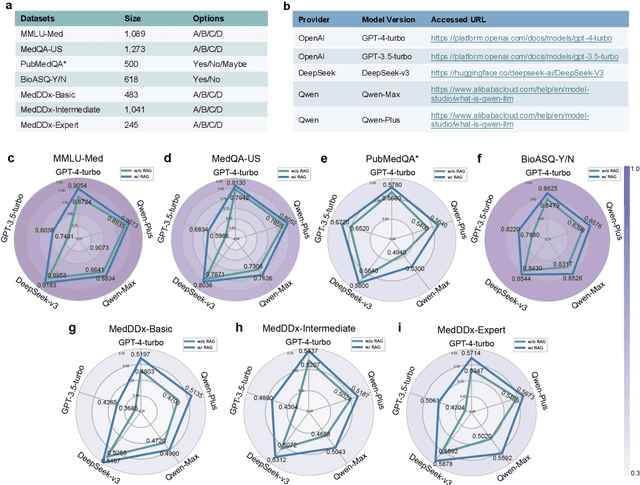
The rapid expansion of medical literature presents growing challenges for structuring and integrating domain knowledge at scale. Knowledge Graphs (KGs) offer a promising solution by enabling efficient retrieval, automated reasoning, and knowledge discovery. However, current KG construction methods often rely on supervised pipelines with limited generalizability or naively aggregate outputs from Large Language Models (LLMs), treating biomedical corpora as static and ignoring the temporal dynamics and contextual uncertainty of evolving knowledge. To address these limitations, we introduce MedKGent, a LLM agent framework for constructing temporally evolving medical KGs. Leveraging over 10 million PubMed abstracts published between 1975 and 2023, we simulate the emergence of biomedical knowledge via a fine-grained daily time series. MedKGent incrementally builds the KG in a day-by-day manner using two specialized agents powered by the Qwen2.5-32B-Instruct model. The Extractor Agent identifies knowledge triples and assigns confidence scores via sampling-based estimation, which are used to filter low-confidence extractions and inform downstream processing. The Constructor Agent incrementally integrates the retained triples into a temporally evolving graph, guided by confidence scores and timestamps to reinforce recurring knowledge and resolve conflicts. The resulting KG contains 156,275 entities and 2,971,384 relational triples. Quality assessments by two SOTA LLMs and three domain experts demonstrate an accuracy approaching 90\%, with strong inter-rater agreement. To evaluate downstream utility, we conduct RAG across seven medical question answering benchmarks using five leading LLMs, consistently observing significant improvements over non-augmented baselines. Case studies further demonstrate the KG's value in literature-based drug repurposing via confidence-aware causal inference.
Learning Deliberately, Acting Intuitively: Unlocking Test-Time Reasoning in Multimodal LLMs
Jul 09, 2025Reasoning is a key capability for large language models (LLMs), particularly when applied to complex tasks such as mathematical problem solving. However, multimodal reasoning research still requires further exploration of modality alignment and training costs. Many of these approaches rely on additional data annotation and relevant rule-based rewards to enhance the understanding and reasoning ability, which significantly increases training costs and limits scalability. To address these challenges, we propose the Deliberate-to-Intuitive reasoning framework (D2I) that improves the understanding and reasoning ability of multimodal LLMs (MLLMs) without extra annotations and complex rewards. Specifically, our method sets deliberate reasoning strategies to enhance modality alignment only through the rule-based format reward during training. While evaluating, the reasoning style shifts to intuitive, which removes deliberate reasoning strategies during training and implicitly reflects the model's acquired abilities in the response. D2I outperforms baselines across both in-domain and out-of-domain benchmarks. Our findings highlight the role of format reward in fostering transferable reasoning skills in MLLMs, and inspire directions for decoupling training-time reasoning depth from test-time response flexibility.
When Large Language Models Meet Speech: A Survey on Integration Approaches
Feb 26, 2025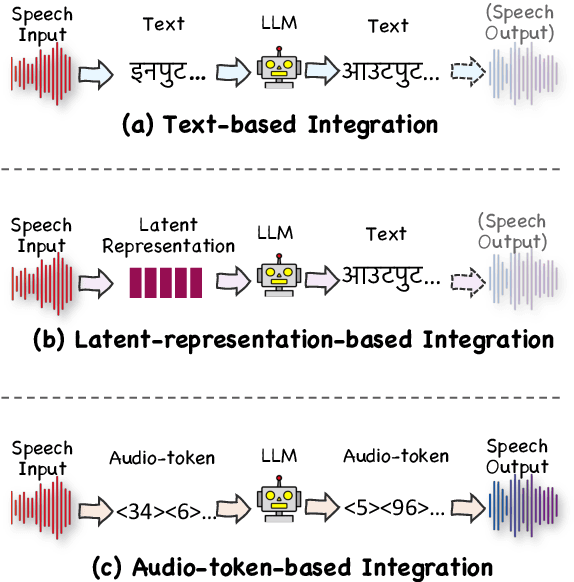
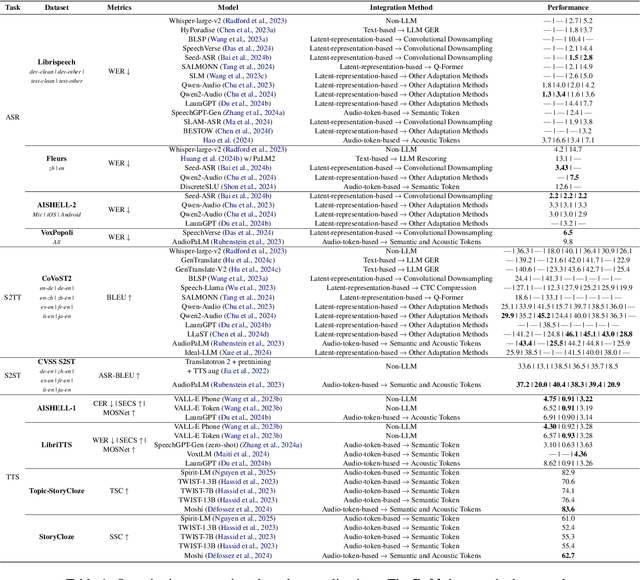
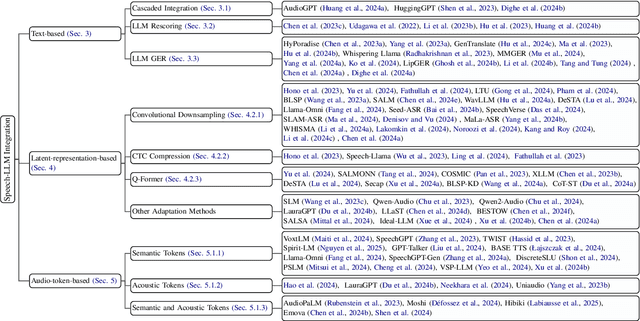
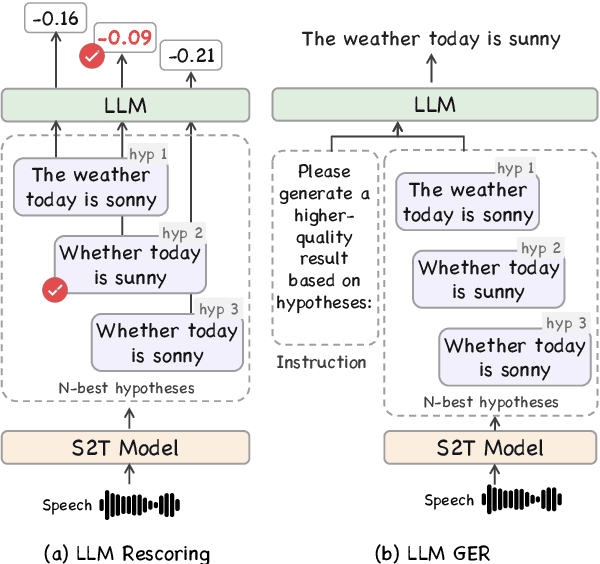
Recent advancements in large language models (LLMs) have spurred interest in expanding their application beyond text-based tasks. A large number of studies have explored integrating other modalities with LLMs, notably speech modality, which is naturally related to text. This paper surveys the integration of speech with LLMs, categorizing the methodologies into three primary approaches: text-based, latent-representation-based, and audio-token-based integration. We also demonstrate how these methods are applied across various speech-related applications and highlight the challenges in this field to offer inspiration for
Federated Incremental Named Entity Recognition
Nov 18, 2024



Federated Named Entity Recognition (FNER) boosts model training within each local client by aggregating the model updates of decentralized local clients, without sharing their private data. However, existing FNER methods assume fixed entity types and local clients in advance, leading to their ineffectiveness in practical applications. In a more realistic scenario, local clients receive new entity types continuously, while new local clients collecting novel data may irregularly join the global FNER training. This challenging setup, referred to here as Federated Incremental NER, renders the global model suffering from heterogeneous forgetting of old entity types from both intra-client and inter-client perspectives. To overcome these challenges, we propose a Local-Global Forgetting Defense (LGFD) model. Specifically, to address intra-client forgetting, we develop a structural knowledge distillation loss to retain the latent space's feature structure and a pseudo-label-guided inter-type contrastive loss to enhance discriminative capability over different entity types, effectively preserving previously learned knowledge within local clients. To tackle inter-client forgetting, we propose a task switching monitor that can automatically identify new entity types under privacy protection and store the latest old global model for knowledge distillation and pseudo-labeling. Experiments demonstrate significant improvement of our LGFD model over comparison methods.
MM-LLMs: Recent Advances in MultiModal Large Language Models
Jan 25, 2024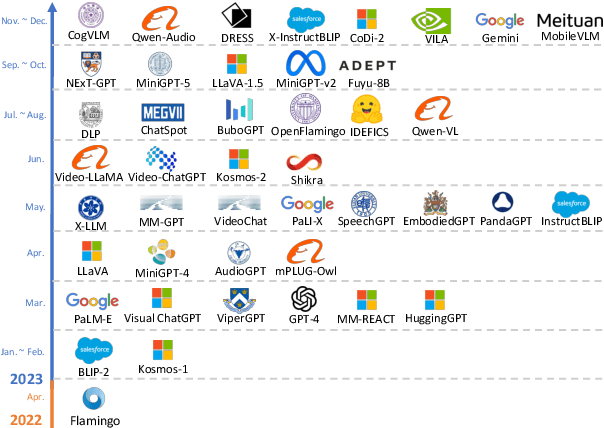
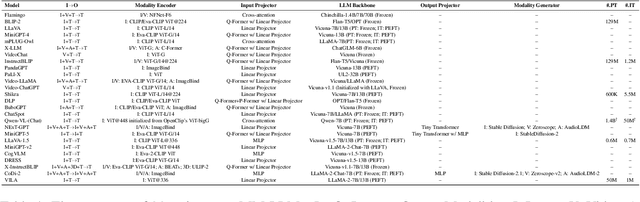
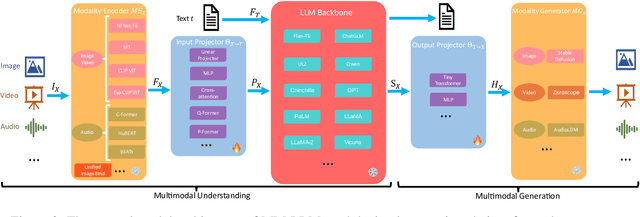
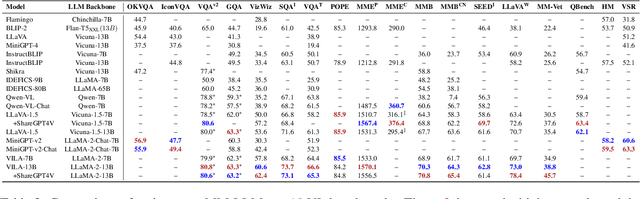
In the past year, MultiModal Large Language Models (MM-LLMs) have undergone substantial advancements, augmenting off-the-shelf LLMs to support MM inputs or outputs via cost-effective training strategies. The resulting models not only preserve the inherent reasoning and decision-making capabilities of LLMs but also empower a diverse range of MM tasks. In this paper, we provide a comprehensive survey aimed at facilitating further research of MM-LLMs. Specifically, we first outline general design formulations for model architecture and training pipeline. Subsequently, we provide brief introductions of $26$ existing MM-LLMs, each characterized by its specific formulations. Additionally, we review the performance of MM-LLMs on mainstream benchmarks and summarize key training recipes to enhance the potency of MM-LLMs. Lastly, we explore promising directions for MM-LLMs while concurrently maintaining a real-time tracking website for the latest developments in the field. We hope that this survey contributes to the ongoing advancement of the MM-LLMs domain.
Continual Named Entity Recognition without Catastrophic Forgetting
Oct 23, 2023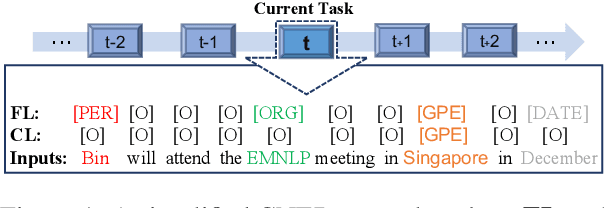
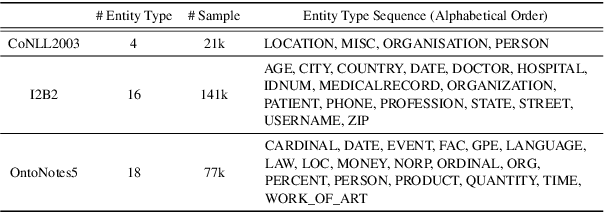
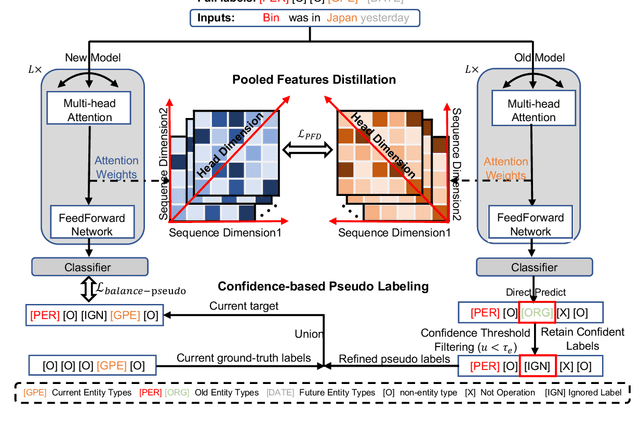
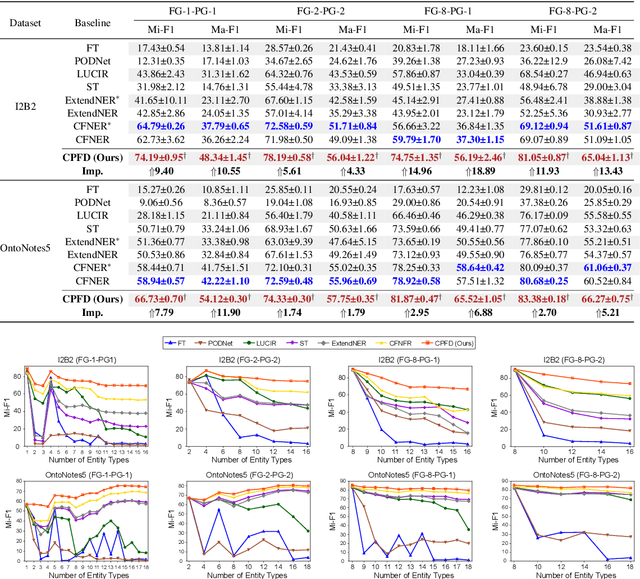
Continual Named Entity Recognition (CNER) is a burgeoning area, which involves updating an existing model by incorporating new entity types sequentially. Nevertheless, continual learning approaches are often severely afflicted by catastrophic forgetting. This issue is intensified in CNER due to the consolidation of old entity types from previous steps into the non-entity type at each step, leading to what is known as the semantic shift problem of the non-entity type. In this paper, we introduce a pooled feature distillation loss that skillfully navigates the trade-off between retaining knowledge of old entity types and acquiring new ones, thereby more effectively mitigating the problem of catastrophic forgetting. Additionally, we develop a confidence-based pseudo-labeling for the non-entity type, \emph{i.e.,} predicting entity types using the old model to handle the semantic shift of the non-entity type. Following the pseudo-labeling process, we suggest an adaptive re-weighting type-balanced learning strategy to handle the issue of biased type distribution. We carried out comprehensive experiments on ten CNER settings using three different datasets. The results illustrate that our method significantly outperforms prior state-of-the-art approaches, registering an average improvement of $6.3$\% and $8.0$\% in Micro and Macro F1 scores, respectively.
Stroke Extraction of Chinese Character Based on Deep Structure Deformable Image Registration
Jul 10, 2023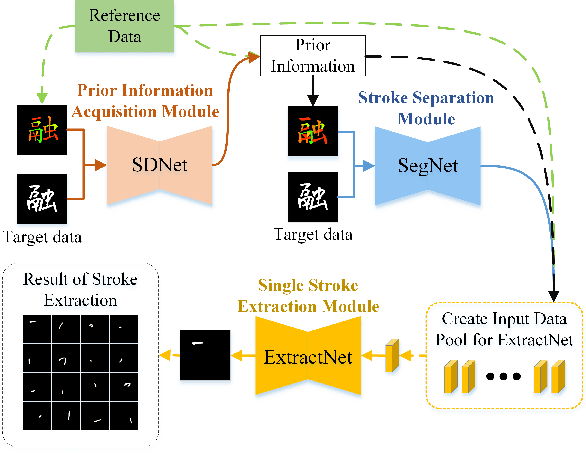
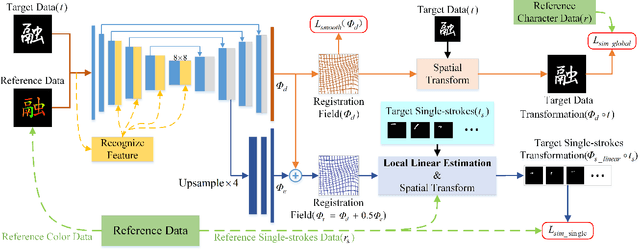
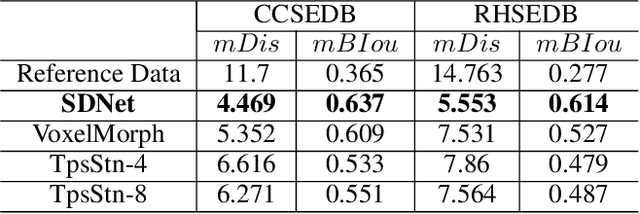
Stroke extraction of Chinese characters plays an important role in the field of character recognition and generation. The most existing character stroke extraction methods focus on image morphological features. These methods usually lead to errors of cross strokes extraction and stroke matching due to rarely using stroke semantics and prior information. In this paper, we propose a deep learning-based character stroke extraction method that takes semantic features and prior information of strokes into consideration. This method consists of three parts: image registration-based stroke registration that establishes the rough registration of the reference strokes and the target as prior information; image semantic segmentation-based stroke segmentation that preliminarily separates target strokes into seven categories; and high-precision extraction of single strokes. In the stroke registration, we propose a structure deformable image registration network to achieve structure-deformable transformation while maintaining the stable morphology of single strokes for character images with complex structures. In order to verify the effectiveness of the method, we construct two datasets respectively for calligraphy characters and regular handwriting characters. The experimental results show that our method strongly outperforms the baselines. Code is available at https://github.com/MengLi-l1/StrokeExtraction.
* 10 pages, 8 figures, published to AAAI-23 (oral)