 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe RoboSense Challenge: Sense Anything, Navigate Anywhere, Adapt Across Platforms
Jan 08, 2026Autonomous systems are increasingly deployed in open and dynamic environments -- from city streets to aerial and indoor spaces -- where perception models must remain reliable under sensor noise, environmental variation, and platform shifts. However, even state-of-the-art methods often degrade under unseen conditions, highlighting the need for robust and generalizable robot sensing. The RoboSense 2025 Challenge is designed to advance robustness and adaptability in robot perception across diverse sensing scenarios. It unifies five complementary research tracks spanning language-grounded decision making, socially compliant navigation, sensor configuration generalization, cross-view and cross-modal correspondence, and cross-platform 3D perception. Together, these tasks form a comprehensive benchmark for evaluating real-world sensing reliability under domain shifts, sensor failures, and platform discrepancies. RoboSense 2025 provides standardized datasets, baseline models, and unified evaluation protocols, enabling large-scale and reproducible comparison of robust perception methods. The challenge attracted 143 teams from 85 institutions across 16 countries, reflecting broad community engagement. By consolidating insights from 23 winning solutions, this report highlights emerging methodological trends, shared design principles, and open challenges across all tracks, marking a step toward building robots that can sense reliably, act robustly, and adapt across platforms in real-world environments.
Cs2K: Class-specific and Class-shared Knowledge Guidance for Incremental Semantic Segmentation
Jul 12, 2024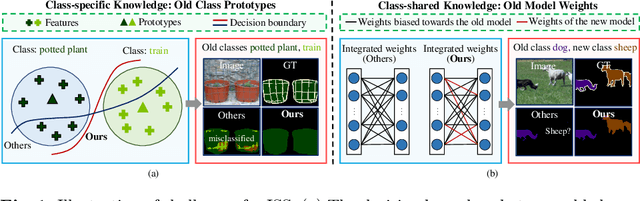
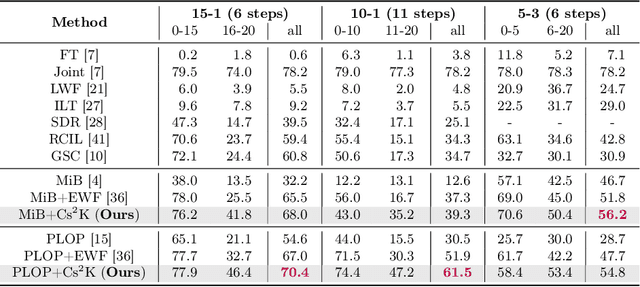
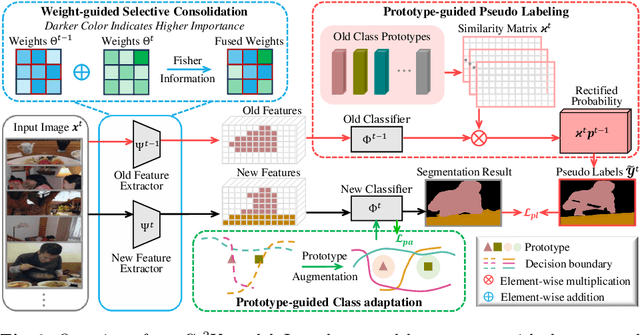
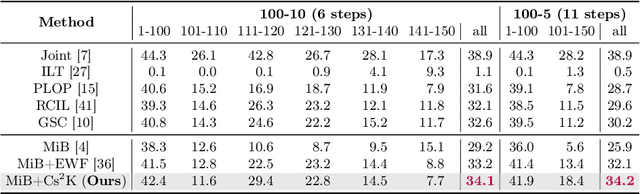
Incremental semantic segmentation endeavors to segment newly encountered classes while maintaining knowledge of old classes. However, existing methods either 1) lack guidance from class-specific knowledge (i.e., old class prototypes), leading to a bias towards new classes, or 2) constrain class-shared knowledge (i.e., old model weights) excessively without discrimination, resulting in a preference for old classes. In this paper, to trade off model performance, we propose the Class-specific and Class-shared Knowledge (Cs2K) guidance for incremental semantic segmentation. Specifically, from the class-specific knowledge aspect, we design a prototype-guided pseudo labeling that exploits feature proximity from prototypes to correct pseudo labels, thereby overcoming catastrophic forgetting. Meanwhile, we develop a prototype-guided class adaptation that aligns class distribution across datasets via learning old augmented prototypes. Moreover, from the class-shared knowledge aspect, we propose a weight-guided selective consolidation to strengthen old memory while maintaining new memory by integrating old and new model weights based on weight importance relative to old classes. Experiments on public datasets demonstrate that our proposed Cs2K significantly improves segmentation performance and is plug-and-play.
Continual Named Entity Recognition without Catastrophic Forgetting
Oct 23, 2023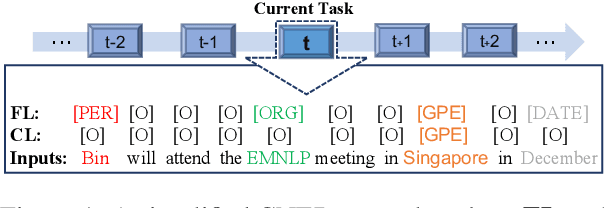
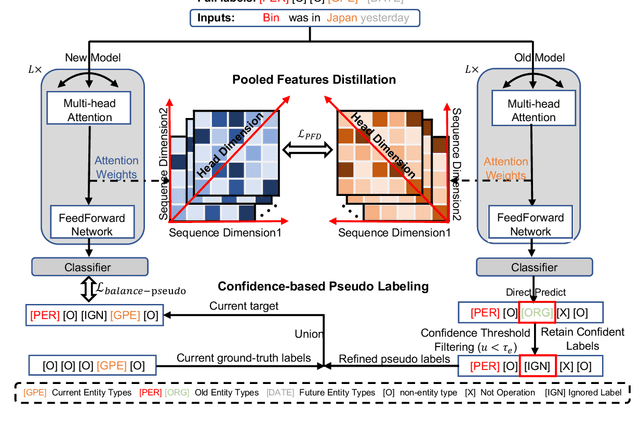
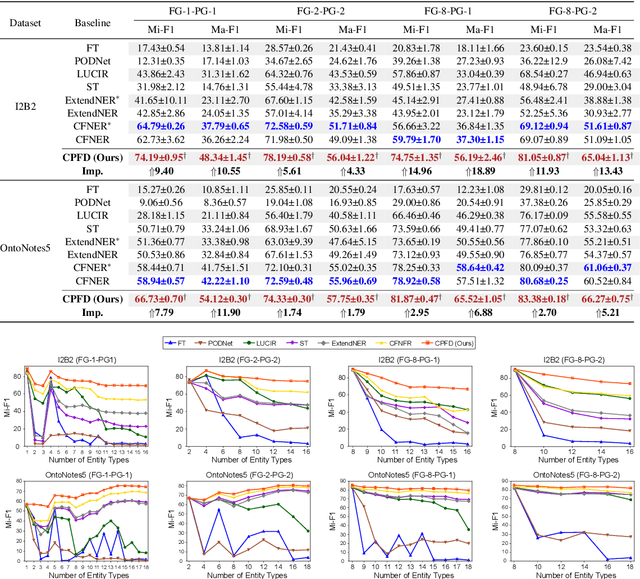
Continual Named Entity Recognition (CNER) is a burgeoning area, which involves updating an existing model by incorporating new entity types sequentially. Nevertheless, continual learning approaches are often severely afflicted by catastrophic forgetting. This issue is intensified in CNER due to the consolidation of old entity types from previous steps into the non-entity type at each step, leading to what is known as the semantic shift problem of the non-entity type. In this paper, we introduce a pooled feature distillation loss that skillfully navigates the trade-off between retaining knowledge of old entity types and acquiring new ones, thereby more effectively mitigating the problem of catastrophic forgetting. Additionally, we develop a confidence-based pseudo-labeling for the non-entity type, \emph{i.e.,} predicting entity types using the old model to handle the semantic shift of the non-entity type. Following the pseudo-labeling process, we suggest an adaptive re-weighting type-balanced learning strategy to handle the issue of biased type distribution. We carried out comprehensive experiments on ten CNER settings using three different datasets. The results illustrate that our method significantly outperforms prior state-of-the-art approaches, registering an average improvement of $6.3$\% and $8.0$\% in Micro and Macro F1 scores, respectively.
Task Relation Distillation and Prototypical Pseudo Label for Incremental Named Entity Recognition
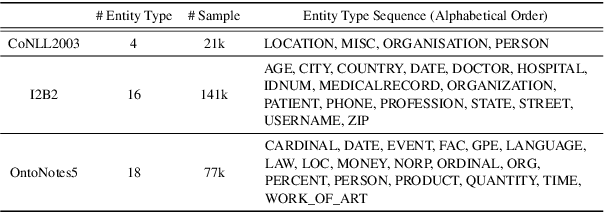
Aug 17, 2023Incremental Named Entity Recognition (INER) involves the sequential learning of new entity types without accessing the training data of previously learned types. However, INER faces the challenge of catastrophic forgetting specific for incremental learning, further aggravated by background shift (i.e., old and future entity types are labeled as the non-entity type in the current task). To address these challenges, we propose a method called task Relation Distillation and Prototypical pseudo label (RDP) for INER. Specifically, to tackle catastrophic forgetting, we introduce a task relation distillation scheme that serves two purposes: 1) ensuring inter-task semantic consistency across different incremental learning tasks by minimizing inter-task relation distillation loss, and 2) enhancing the model's prediction confidence by minimizing intra-task self-entropy loss. Simultaneously, to mitigate background shift, we develop a prototypical pseudo label strategy that distinguishes old entity types from the current non-entity type using the old model. This strategy generates high-quality pseudo labels by measuring the distances between token embeddings and type-wise prototypes. We conducted extensive experiments on ten INER settings of three benchmark datasets (i.e., CoNLL2003, I2B2, and OntoNotes5). The results demonstrate that our method achieves significant improvements over the previous state-of-the-art methods, with an average increase of 6.08% in Micro F1 score and 7.71% in Macro F1 score.
Gradient-Semantic Compensation for Incremental Semantic Segmentation
Jul 20, 2023Incremental semantic segmentation aims to continually learn the segmentation of new coming classes without accessing the training data of previously learned classes. However, most current methods fail to address catastrophic forgetting and background shift since they 1) treat all previous classes equally without considering different forgetting paces caused by imbalanced gradient back-propagation; 2) lack strong semantic guidance between classes. To tackle the above challenges, in this paper, we propose a Gradient-Semantic Compensation (GSC) model, which surmounts incremental semantic segmentation from both gradient and semantic perspectives. Specifically, to address catastrophic forgetting from the gradient aspect, we develop a step-aware gradient compensation that can balance forgetting paces of previously seen classes via re-weighting gradient backpropagation. Meanwhile, we propose a soft-sharp semantic relation distillation to distill consistent inter-class semantic relations via soft labels for alleviating catastrophic forgetting from the semantic aspect. In addition, we develop a prototypical pseudo re-labeling that provides strong semantic guidance to mitigate background shift. It produces high-quality pseudo labels for old classes in the background by measuring distances between pixels and class-wise prototypes. Extensive experiments on three public datasets, i.e., Pascal VOC 2012, ADE20K, and Cityscapes, demonstrate the effectiveness of our proposed GSC model.
Self-paced Weight Consolidation for Continual Learning
Jul 20, 2023


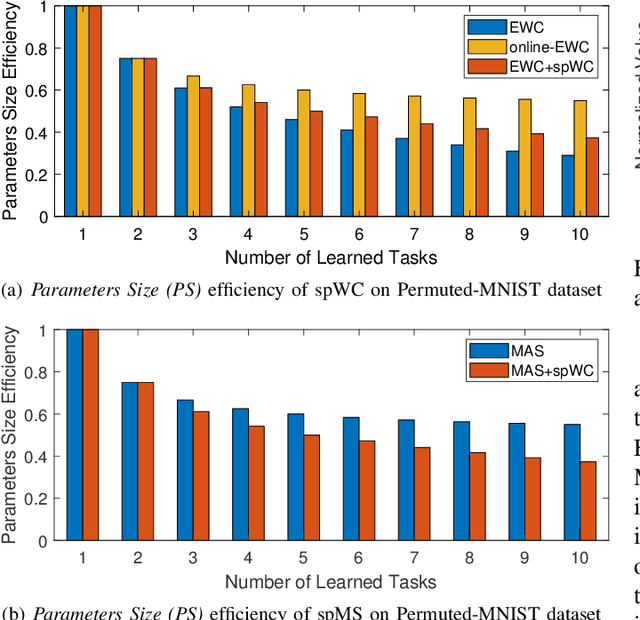
Continual learning algorithms which keep the parameters of new tasks close to that of previous tasks, are popular in preventing catastrophic forgetting in sequential task learning settings. However, 1) the performance for the new continual learner will be degraded without distinguishing the contributions of previously learned tasks; 2) the computational cost will be greatly increased with the number of tasks, since most existing algorithms need to regularize all previous tasks when learning new tasks. To address the above challenges, we propose a self-paced Weight Consolidation (spWC) framework to attain robust continual learning via evaluating the discriminative contributions of previous tasks. To be specific, we develop a self-paced regularization to reflect the priorities of past tasks via measuring difficulty based on key performance indicator (i.e., accuracy). When encountering a new task, all previous tasks are sorted from "difficult" to "easy" based on the priorities. Then the parameters of the new continual learner will be learned via selectively maintaining the knowledge amongst more difficult past tasks, which could well overcome catastrophic forgetting with less computational cost. We adopt an alternative convex search to iteratively update the model parameters and priority weights in the bi-convex formulation. The proposed spWC framework is plug-and-play, which is applicable to most continual learning algorithms (e.g., EWC, MAS and RCIL) in different directions (e.g., classification and segmentation). Experimental results on several public benchmark datasets demonstrate that our proposed framework can effectively improve performance when compared with other popular continual learning algorithms.
Federated Incremental Semantic Segmentation
Apr 10, 2023



Federated learning-based semantic segmentation (FSS) has drawn widespread attention via decentralized training on local clients. However, most FSS models assume categories are fixed in advance, thus heavily undergoing forgetting on old categories in practical applications where local clients receive new categories incrementally while have no memory storage to access old classes. Moreover, new clients collecting novel classes may join in the global training of FSS, which further exacerbates catastrophic forgetting. To surmount the above challenges, we propose a Forgetting-Balanced Learning (FBL) model to address heterogeneous forgetting on old classes from both intra-client and inter-client aspects. Specifically, under the guidance of pseudo labels generated via adaptive class-balanced pseudo labeling, we develop a forgetting-balanced semantic compensation loss and a forgetting-balanced relation consistency loss to rectify intra-client heterogeneous forgetting of old categories with background shift. It performs balanced gradient propagation and relation consistency distillation within local clients. Moreover, to tackle heterogeneous forgetting from inter-client aspect, we propose a task transition monitor. It can identify new classes under privacy protection and store the latest old global model for relation distillation. Qualitative experiments reveal large improvement of our model against comparison methods. The code is available at https://github.com/JiahuaDong/FISS.