 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCrafting Your Evolving Dreams: Concept-Incremental Versatile Customization
Jun 03, 2026Custom diffusion models (CDMs) have garnered significant interest owing to their remarkable capacity for generating personalized concepts. However, the majority of CDMs unrealistically presume that the user's collection of personalized concepts is static and incapable of incremental growth over time. Furthermore, they exhibit significant catastrophic forgetting and concept neglect of previously learned concepts when incrementally learning a sequence of new ones. To resolve the above challenges, we develop a novel Continually Customizable Diffusion Model (CCDM), enabling users to perform concept-incremental versatile customization. Specifically, we design an attribute-decoupled LoRA (AD-LoRA) module and a relevance-guided AD-LoRA aggregation strategy to mitigate catastrophic forgetting. They can preserve concept-specific attributes of each task and leverage beneficial inter-task correlations to enhance the continual learning of new customization tasks. Additionally, to address the challenge of concept neglect, we propose a controllable regional context synthesis strategy that performs multi-concept composition in alignment with user-provided conditions. This strategy enhances the overall consistency in multi-concept synthesis by guaranteeing semantic independence between user-defined regions and their smooth boundary transitions. Experiments show our CCDM exhibits significant improvements over baseline methods.
How to Continually Adapt Text-to-Image Diffusion Models for Flexible Customization?
Oct 23, 2024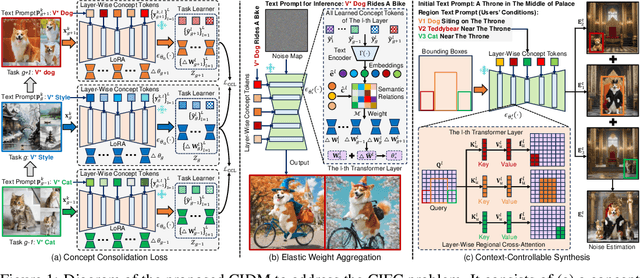
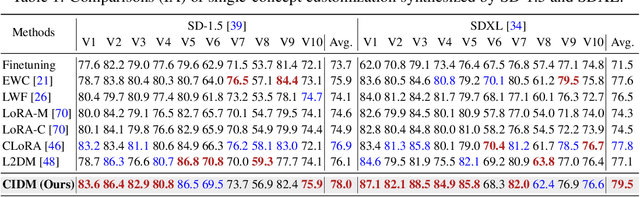

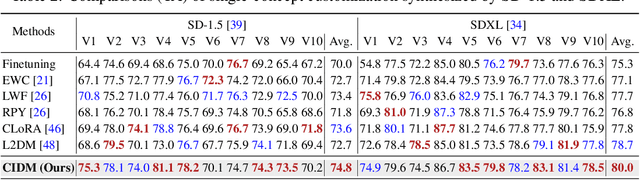
Custom diffusion models (CDMs) have attracted widespread attention due to their astonishing generative ability for personalized concepts. However, most existing CDMs unreasonably assume that personalized concepts are fixed and cannot change over time. Moreover, they heavily suffer from catastrophic forgetting and concept neglect on old personalized concepts when continually learning a series of new concepts. To address these challenges, we propose a novel Concept-Incremental text-to-image Diffusion Model (CIDM), which can resolve catastrophic forgetting and concept neglect to learn new customization tasks in a concept-incremental manner. Specifically, to surmount the catastrophic forgetting of old concepts, we develop a concept consolidation loss and an elastic weight aggregation module. They can explore task-specific and task-shared knowledge during training, and aggregate all low-rank weights of old concepts based on their contributions during inference. Moreover, in order to address concept neglect, we devise a context-controllable synthesis strategy that leverages expressive region features and noise estimation to control the contexts of generated images according to user conditions. Experiments validate that our CIDM surpasses existing custom diffusion models. The source codes are available at https://github.com/JiahuaDong/CIFC.
Prototype Correlation Matching and Class-Relation Reasoning for Few-Shot Medical Image Segmentation
Jun 07, 2024Few-shot medical image segmentation has achieved great progress in improving accuracy and efficiency of medical analysis in the biomedical imaging field. However, most existing methods cannot explore inter-class relations among base and novel medical classes to reason unseen novel classes. Moreover, the same kind of medical class has large intra-class variations brought by diverse appearances, shapes and scales, thus causing ambiguous visual characterization to degrade generalization performance of these existing methods on unseen novel classes. To address the above challenges, in this paper, we propose a \underline{\textbf{P}}rototype correlation \underline{\textbf{M}}atching and \underline{\textbf{C}}lass-relation \underline{\textbf{R}}easoning (i.e., \textbf{PMCR}) model. The proposed model can effectively mitigate false pixel correlation matches caused by large intra-class variations while reasoning inter-class relations among different medical classes. Specifically, in order to address false pixel correlation match brought by large intra-class variations, we propose a prototype correlation matching module to mine representative prototypes that can characterize diverse visual information of different appearances well. We aim to explore prototype-level rather than pixel-level correlation matching between support and query features via optimal transport algorithm to tackle false matches caused by intra-class variations. Meanwhile, in order to explore inter-class relations, we design a class-relation reasoning module to segment unseen novel medical objects via reasoning inter-class relations between base and novel classes. Such inter-class relations can be well propagated to semantic encoding of local query features to improve few-shot segmentation performance. Quantitative comparisons illustrates the large performance improvement of our model over other baseline methods.
Dual Hyperspectral Mamba for Efficient Spectral Compressive Imaging
Jun 01, 2024



Deep unfolding methods have made impressive progress in restoring 3D hyperspectral images (HSIs) from 2D measurements through convolution neural networks or Transformers in spectral compressive imaging. However, they cannot efficiently capture long-range dependencies using global receptive fields, which significantly limits their performance in HSI reconstruction. Moreover, these methods may suffer from local context neglect if we directly utilize Mamba to unfold a 2D feature map as a 1D sequence for modeling global long-range dependencies. To address these challenges, we propose a novel Dual Hyperspectral Mamba (DHM) to explore both global long-range dependencies and local contexts for efficient HSI reconstruction. After learning informative parameters to estimate degradation patterns of the CASSI system, we use them to scale the linear projection and offer noise level for the denoiser (i.e., our proposed DHM). Specifically, our DHM consists of multiple dual hyperspectral S4 blocks (DHSBs) to restore original HSIs. Particularly, each DHSB contains a global hyperspectral S4 block (GHSB) to model long-range dependencies across the entire high-resolution HSIs using global receptive fields, and a local hyperspectral S4 block (LHSB) to address local context neglect by establishing structured state-space sequence (S4) models within local windows. Experiments verify the benefits of our DHM for HSI reconstruction. The source codes and models will be available at https://github.com/JiahuaDong/DHM.
Task Relation Distillation and Prototypical Pseudo Label for Incremental Named Entity Recognition
Aug 17, 2023Incremental Named Entity Recognition (INER) involves the sequential learning of new entity types without accessing the training data of previously learned types. However, INER faces the challenge of catastrophic forgetting specific for incremental learning, further aggravated by background shift (i.e., old and future entity types are labeled as the non-entity type in the current task). To address these challenges, we propose a method called task Relation Distillation and Prototypical pseudo label (RDP) for INER. Specifically, to tackle catastrophic forgetting, we introduce a task relation distillation scheme that serves two purposes: 1) ensuring inter-task semantic consistency across different incremental learning tasks by minimizing inter-task relation distillation loss, and 2) enhancing the model's prediction confidence by minimizing intra-task self-entropy loss. Simultaneously, to mitigate background shift, we develop a prototypical pseudo label strategy that distinguishes old entity types from the current non-entity type using the old model. This strategy generates high-quality pseudo labels by measuring the distances between token embeddings and type-wise prototypes. We conducted extensive experiments on ten INER settings of three benchmark datasets (i.e., CoNLL2003, I2B2, and OntoNotes5). The results demonstrate that our method achieves significant improvements over the previous state-of-the-art methods, with an average increase of 6.08% in Micro F1 score and 7.71% in Macro F1 score.
Crucial Semantic Classifier-based Adversarial Learning for Unsupervised Domain Adaptation
Feb 03, 2023



Unsupervised Domain Adaptation (UDA), which aims to explore the transferrable features from a well-labeled source domain to a related unlabeled target domain, has been widely progressed. Nevertheless, as one of the mainstream, existing adversarial-based methods neglect to filter the irrelevant semantic knowledge, hindering adaptation performance improvement. Besides, they require an additional domain discriminator that strives extractor to generate confused representations, but discrete designing may cause model collapse. To tackle the above issues, we propose Crucial Semantic Classifier-based Adversarial Learning (CSCAL), which pays more attention to crucial semantic knowledge transferring and leverages the classifier to implicitly play the role of domain discriminator without extra network designing. Specifically, in intra-class-wise alignment, a Paired-Level Discrepancy (PLD) is designed to transfer crucial semantic knowledge. Additionally, based on classifier predictions, a Nuclear Norm-based Discrepancy (NND) is formed that considers inter-class-wise information and improves the adaptation performance. Moreover, CSCAL can be effortlessly merged into different UDA methods as a regularizer and dramatically promote their performance.