 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Large Language Models Meet Speech: A Survey on Integration Approaches
Feb 26, 2025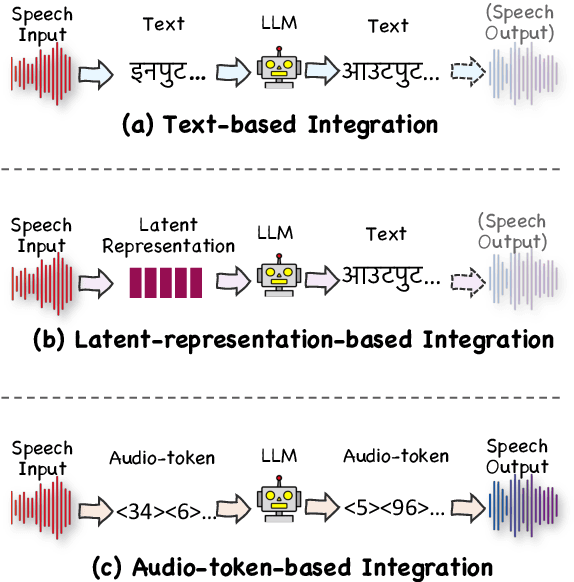
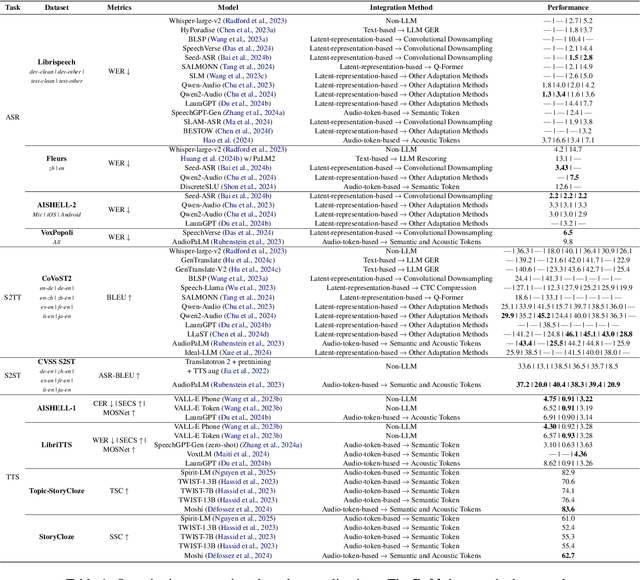
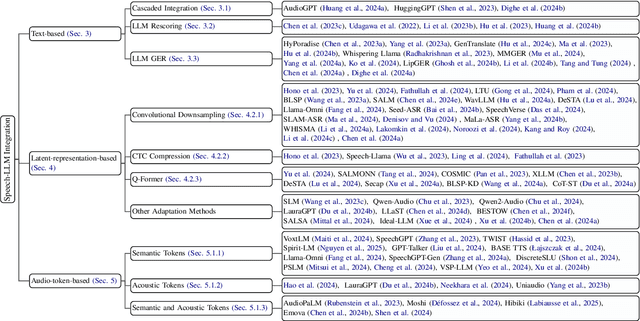
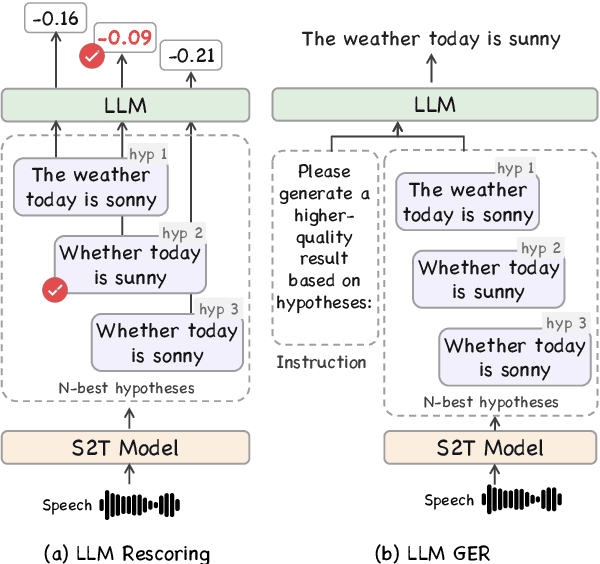
Recent advancements in large language models (LLMs) have spurred interest in expanding their application beyond text-based tasks. A large number of studies have explored integrating other modalities with LLMs, notably speech modality, which is naturally related to text. This paper surveys the integration of speech with LLMs, categorizing the methodologies into three primary approaches: text-based, latent-representation-based, and audio-token-based integration. We also demonstrate how these methods are applied across various speech-related applications and highlight the challenges in this field to offer inspiration for
Cross-lingual Embedding Clustering for Hierarchical Softmax in Low-Resource Multilingual Speech Recognition
Jan 29, 2025



We present a novel approach centered on the decoding stage of Automatic Speech Recognition (ASR) that enhances multilingual performance, especially for low-resource languages. It utilizes a cross-lingual embedding clustering method to construct a hierarchical Softmax (H-Softmax) decoder, which enables similar tokens across different languages to share similar decoder representations. It addresses the limitations of the previous Huffman-based H-Softmax method, which relied on shallow features in token similarity assessments. Through experiments on a downsampled dataset of 15 languages, we demonstrate the effectiveness of our approach in improving low-resource multilingual ASR accuracy.
MELD-ST: An Emotion-aware Speech Translation Dataset
May 21, 2024Emotion plays a crucial role in human conversation. This paper underscores the significance of considering emotion in speech translation. We present the MELD-ST dataset for the emotion-aware speech translation task, comprising English-to-Japanese and English-to-German language pairs. Each language pair includes about 10,000 utterances annotated with emotion labels from the MELD dataset. Baseline experiments using the SeamlessM4T model on the dataset indicate that fine-tuning with emotion labels can enhance translation performance in some settings, highlighting the need for further research in emotion-aware speech translation systems.
MOS-FAD: Improving Fake Audio Detection Via Automatic Mean Opinion Score Prediction
Jan 25, 2024Automatic Mean Opinion Score (MOS) prediction is employed to evaluate the quality of synthetic speech. This study extends the application of predicted MOS to the task of Fake Audio Detection (FAD), as we expect that MOS can be used to assess how close synthesized speech is to the natural human voice. We propose MOS-FAD, where MOS can be leveraged at two key points in FAD: training data selection and model fusion. In training data selection, we demonstrate that MOS enables effective filtering of samples from unbalanced datasets. In the model fusion, our results demonstrate that incorporating MOS as a gating mechanism in FAD model fusion enhances overall performance.
FedCPC: An Effective Federated Contrastive Learning Method for Privacy Preserving Early-Stage Alzheimer's Speech Detection
Nov 21, 2023The early-stage Alzheimer's disease (AD) detection has been considered an important field of medical studies. Like traditional machine learning methods, speech-based automatic detection also suffers from data privacy risks because the data of specific patients are exclusive to each medical institution. A common practice is to use federated learning to protect the patients' data privacy. However, its distributed learning process also causes performance reduction. To alleviate this problem while protecting user privacy, we propose a federated contrastive pre-training (FedCPC) performed before federated training for AD speech detection, which can learn a better representation from raw data and enables different clients to share data in the pre-training and training stages. Experimental results demonstrate that the proposed methods can achieve satisfactory performance while preserving data privacy.
Fusion of Self-supervised Learned Models for MOS Prediction
Apr 11, 2022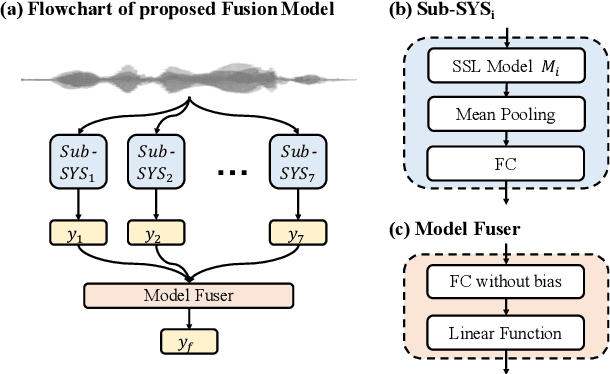
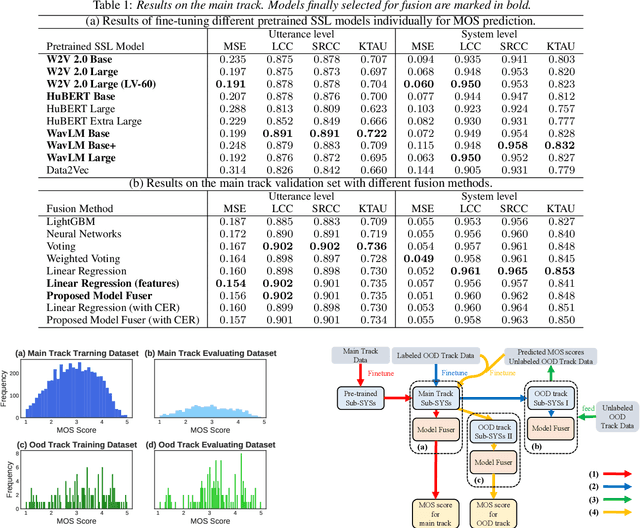
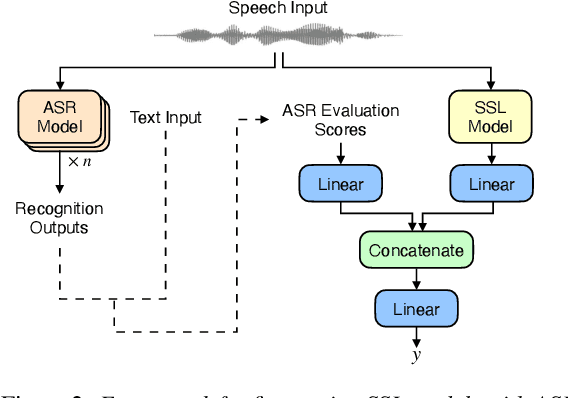
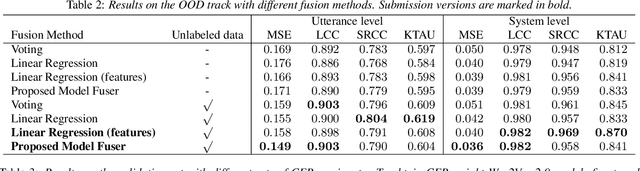
We participated in the mean opinion score (MOS) prediction challenge, 2022. This challenge aims to predict MOS scores of synthetic speech on two tracks, the main track and a more challenging sub-track: out-of-domain (OOD). To improve the accuracy of the predicted scores, we have explored several model fusion-related strategies and proposed a fused framework in which seven pretrained self-supervised learned (SSL) models have been engaged. These pretrained SSL models are derived from three ASR frameworks, including Wav2Vec, Hubert, and WavLM. For the OOD track, we followed the 7 SSL models selected on the main track and adopted a semi-supervised learning method to exploit the unlabeled data. According to the official analysis results, our system has achieved 1st rank in 6 out of 16 metrics and is one of the top 3 systems for 13 out of 16 metrics. Specifically, we have achieved the highest LCC, SRCC, and KTAU scores at the system level on main track, as well as the best performance on the LCC, SRCC, and KTAU evaluation metrics at the utterance level on OOD track. Compared with the basic SSL models, the prediction accuracy of the fused system has been largely improved, especially on OOD sub-track.