 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFusion of Self-supervised Learned Models for MOS Prediction
Apr 11, 2022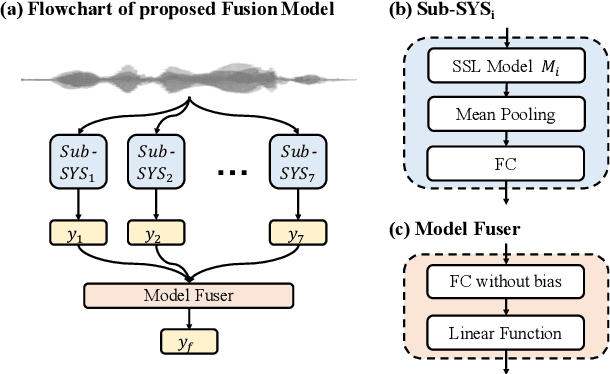
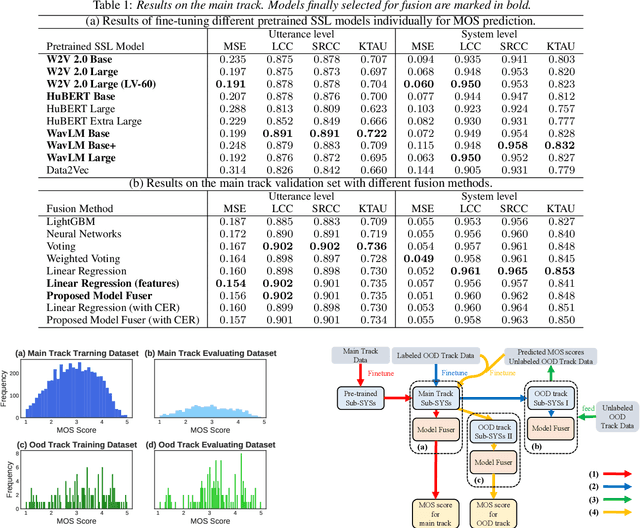
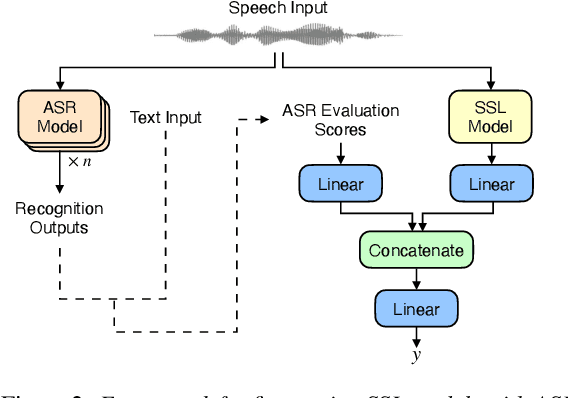
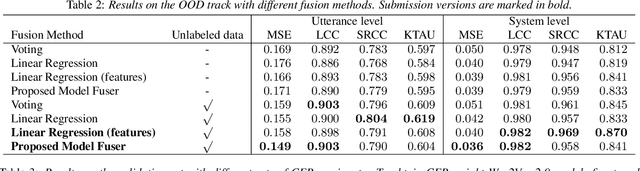
We participated in the mean opinion score (MOS) prediction challenge, 2022. This challenge aims to predict MOS scores of synthetic speech on two tracks, the main track and a more challenging sub-track: out-of-domain (OOD). To improve the accuracy of the predicted scores, we have explored several model fusion-related strategies and proposed a fused framework in which seven pretrained self-supervised learned (SSL) models have been engaged. These pretrained SSL models are derived from three ASR frameworks, including Wav2Vec, Hubert, and WavLM. For the OOD track, we followed the 7 SSL models selected on the main track and adopted a semi-supervised learning method to exploit the unlabeled data. According to the official analysis results, our system has achieved 1st rank in 6 out of 16 metrics and is one of the top 3 systems for 13 out of 16 metrics. Specifically, we have achieved the highest LCC, SRCC, and KTAU scores at the system level on main track, as well as the best performance on the LCC, SRCC, and KTAU evaluation metrics at the utterance level on OOD track. Compared with the basic SSL models, the prediction accuracy of the fused system has been largely improved, especially on OOD sub-track.
Scientific Credibility of Machine Translation Research: A Meta-Evaluation of 769 Papers
Jun 29, 2021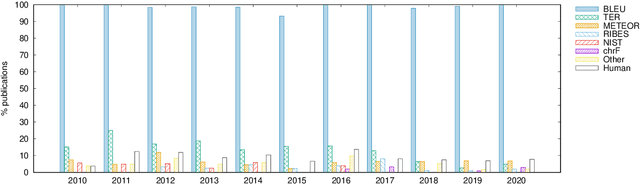

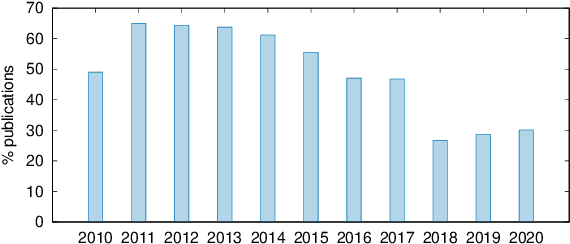
This paper presents the first large-scale meta-evaluation of machine translation (MT). We annotated MT evaluations conducted in 769 research papers published from 2010 to 2020. Our study shows that practices for automatic MT evaluation have dramatically changed during the past decade and follow concerning trends. An increasing number of MT evaluations exclusively rely on differences between BLEU scores to draw conclusions, without performing any kind of statistical significance testing nor human evaluation, while at least 108 metrics claiming to be better than BLEU have been proposed. MT evaluations in recent papers tend to copy and compare automatic metric scores from previous work to claim the superiority of a method or an algorithm without confirming neither exactly the same training, validating, and testing data have been used nor the metric scores are comparable. Furthermore, tools for reporting standardized metric scores are still far from being widely adopted by the MT community. After showing how the accumulation of these pitfalls leads to dubious evaluation, we propose a guideline to encourage better automatic MT evaluation along with a simple meta-evaluation scoring method to assess its credibility.
Balancing Cost and Benefit with Tied-Multi Transformers
Feb 20, 2020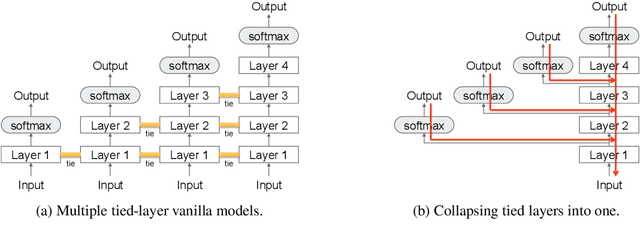
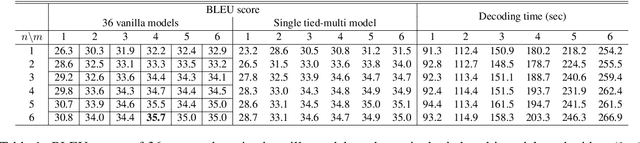
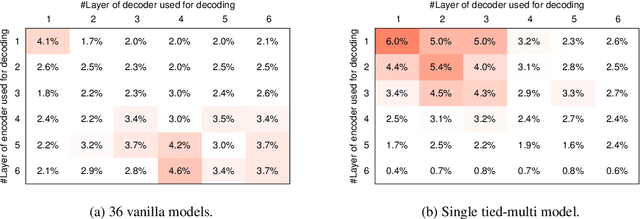
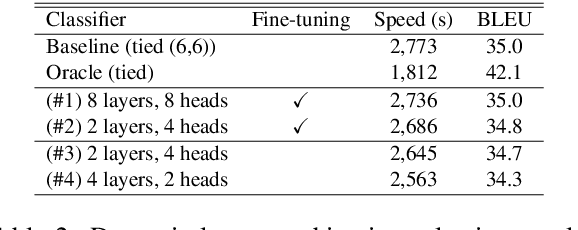
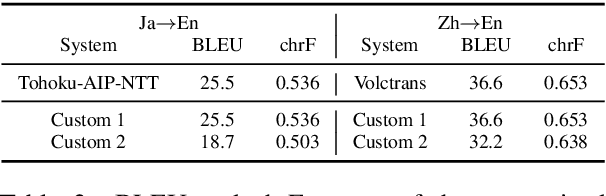
We propose and evaluate a novel procedure for training multiple Transformers with tied parameters which compresses multiple models into one enabling the dynamic choice of the number of encoder and decoder layers during decoding. In sequence-to-sequence modeling, typically, the output of the last layer of the N-layer encoder is fed to the M-layer decoder, and the output of the last decoder layer is used to compute loss. Instead, our method computes a single loss consisting of NxM losses, where each loss is computed from the output of one of the M decoder layers connected to one of the N encoder layers. Such a model subsumes NxM models with different number of encoder and decoder layers, and can be used for decoding with fewer than the maximum number of encoder and decoder layers. We then propose a mechanism to choose a priori the number of encoder and decoder layers for faster decoding, and also explore recurrent stacking of layers and knowledge distillation for model compression. We present a cost-benefit analysis of applying the proposed approaches for neural machine translation and show that they reduce decoding costs while preserving translation quality.
INFODENS: An Open-source Framework for Learning Text Representations
Oct 16, 2018
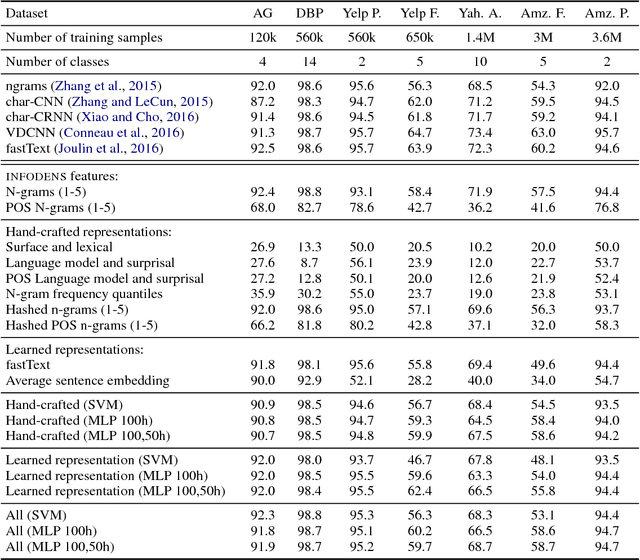


The advent of representation learning methods enabled large performance gains on various language tasks, alleviating the need for manual feature engineering. While engineered representations are usually based on some linguistic understanding and are therefore more interpretable, learned representations are harder to interpret. Empirically studying the complementarity of both approaches can provide more linguistic insights that would help reach a better compromise between interpretability and performance. We present INFODENS, a framework for studying learned and engineered representations of text in the context of text classification tasks. It is designed to simplify the tasks of feature engineering as well as provide the groundwork for extracting learned features and combining both approaches. INFODENS is flexible, extensible, with a short learning curve, and is easy to integrate with many of the available and widely used natural language processing tools.