 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBalancing Cost and Benefit with Tied-Multi Transformers
Paper and Code
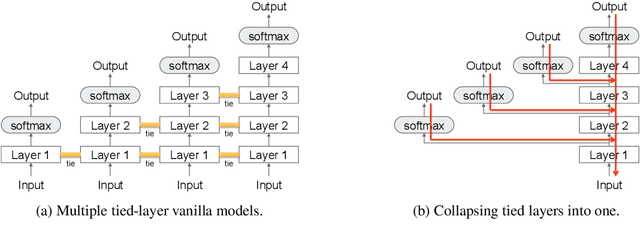
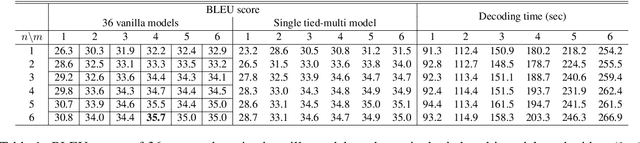
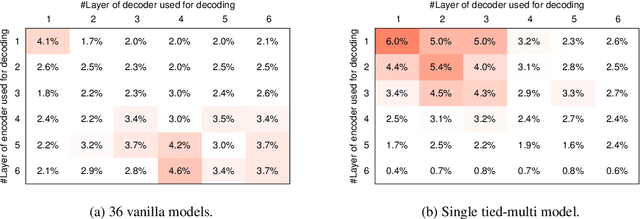
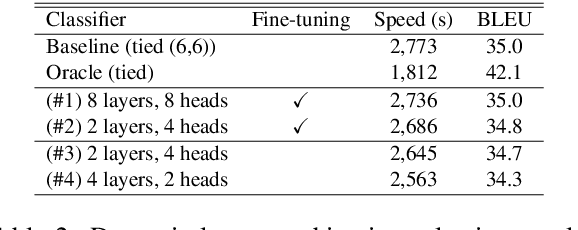
We propose and evaluate a novel procedure for training multiple Transformers with tied parameters which compresses multiple models into one enabling the dynamic choice of the number of encoder and decoder layers during decoding. In sequence-to-sequence modeling, typically, the output of the last layer of the N-layer encoder is fed to the M-layer decoder, and the output of the last decoder layer is used to compute loss. Instead, our method computes a single loss consisting of NxM losses, where each loss is computed from the output of one of the M decoder layers connected to one of the N encoder layers. Such a model subsumes NxM models with different number of encoder and decoder layers, and can be used for decoding with fewer than the maximum number of encoder and decoder layers. We then propose a mechanism to choose a priori the number of encoder and decoder layers for faster decoding, and also explore recurrent stacking of layers and knowledge distillation for model compression. We present a cost-benefit analysis of applying the proposed approaches for neural machine translation and show that they reduce decoding costs while preserving translation quality.