 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeINFODENS: An Open-source Framework for Learning Text Representations
Oct 16, 2018
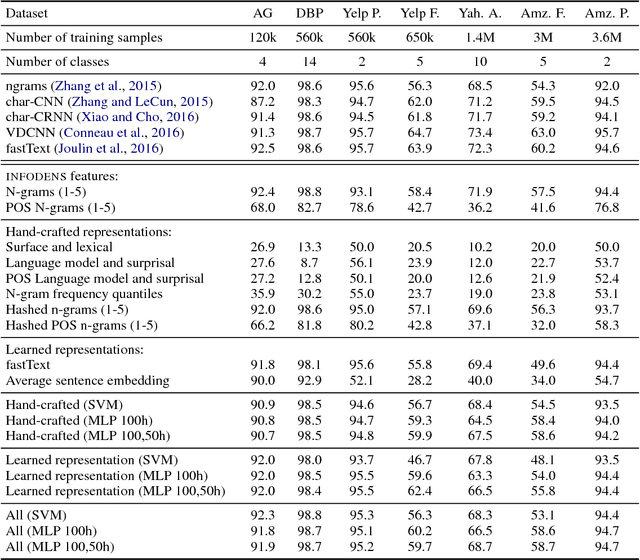


The advent of representation learning methods enabled large performance gains on various language tasks, alleviating the need for manual feature engineering. While engineered representations are usually based on some linguistic understanding and are therefore more interpretable, learned representations are harder to interpret. Empirically studying the complementarity of both approaches can provide more linguistic insights that would help reach a better compromise between interpretability and performance. We present INFODENS, a framework for studying learned and engineered representations of text in the context of text classification tasks. It is designed to simplify the tasks of feature engineering as well as provide the groundwork for extracting learned features and combining both approaches. INFODENS is flexible, extensible, with a short learning curve, and is easy to integrate with many of the available and widely used natural language processing tools.