 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeObject-Focus Actor for Data-efficient Robot Generalization Dexterous Manipulation
May 21, 2025Robot manipulation learning from human demonstrations offers a rapid means to acquire skills but often lacks generalization across diverse scenes and object placements. This limitation hinders real-world applications, particularly in complex tasks requiring dexterous manipulation. Vision-Language-Action (VLA) paradigm leverages large-scale data to enhance generalization. However, due to data scarcity, VLA's performance remains limited. In this work, we introduce Object-Focus Actor (OFA), a novel, data-efficient approach for generalized dexterous manipulation. OFA exploits the consistent end trajectories observed in dexterous manipulation tasks, allowing for efficient policy training. Our method employs a hierarchical pipeline: object perception and pose estimation, pre-manipulation pose arrival and OFA policy execution. This process ensures that the manipulation is focused and efficient, even in varied backgrounds and positional layout. Comprehensive real-world experiments across seven tasks demonstrate that OFA significantly outperforms baseline methods in both positional and background generalization tests. Notably, OFA achieves robust performance with only 10 demonstrations, highlighting its data efficiency.
Dexterous Hand Manipulation via Efficient Imitation-Bootstrapped Online Reinforcement Learning
Mar 06, 2025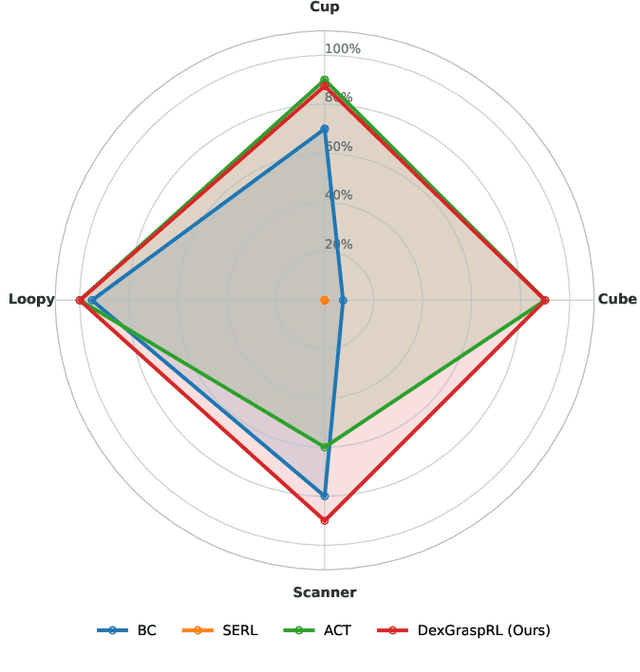
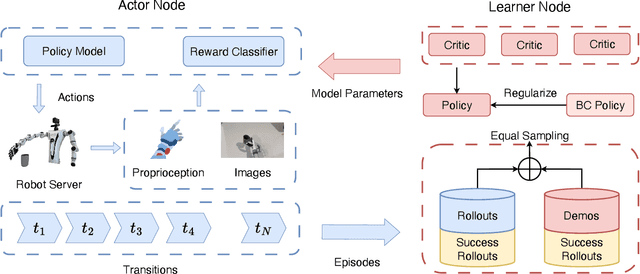
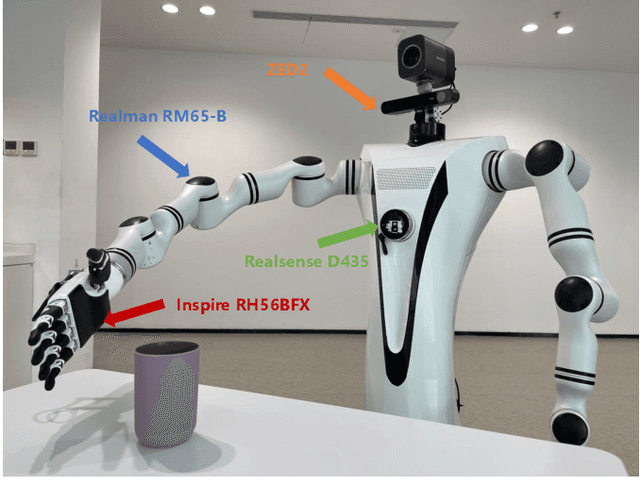

Dexterous hand manipulation in real-world scenarios presents considerable challenges due to its demands for both dexterity and precision. While imitation learning approaches have thoroughly examined these challenges, they still require a significant number of expert demonstrations and are limited by a constrained performance upper bound. In this paper, we propose a novel and efficient Imitation-Bootstrapped Online Reinforcement Learning (IBORL) method tailored for robotic dexterous hand manipulation in real-world environments. Specifically, we pretrain the policy using a limited set of expert demonstrations and subsequently finetune this policy through direct reinforcement learning in the real world. To address the catastrophic forgetting issues that arise from the distribution shift between expert demonstrations and real-world environments, we design a regularization term that balances the exploration of novel behaviors with the preservation of the pretrained policy. Our experiments with real-world tasks demonstrate that our method significantly outperforms existing approaches, achieving an almost 100% success rate and a 23% improvement in cycle time. Furthermore, by finetuning with online reinforcement learning, our method surpasses expert demonstrations and uncovers superior policies. Our code and empirical results are available in https://hggforget.github.io/iborl.github.io/.
Empowering Embodied Manipulation: A Bimanual-Mobile Robot Manipulation Dataset for Household Tasks
May 29, 2024



As Embodied AI advances, it increasingly enables robots to handle the complexity of household manipulation tasks more effectively. However, the application of robots in these settings remains limited due to the scarcity of bimanual-mobile robot manipulation datasets. Existing datasets either focus solely on simple grasping tasks using single-arm robots without mobility, or collect sensor data limited to a narrow scope of sensory inputs. As a result, these datasets often fail to encapsulate the intricate and dynamic nature of real-world tasks that bimanual-mobile robots are expected to perform. To address these limitations, we introduce BRMData, a Bimanual-mobile Robot Manipulation Dataset designed specifically for household applications. The dataset includes 10 diverse household tasks, ranging from simple single-arm manipulation to more complex dual-arm and mobile manipulations. It is collected using multi-view and depth-sensing data acquisition strategies. Human-robot interactions and multi-object manipulations are integrated into the task designs to closely simulate real-world household applications. Moreover, we present a Manipulation Efficiency Score (MES) metric to evaluate both the precision and efficiency of robot manipulation methods. BRMData aims to drive the development of versatile robot manipulation technologies, specifically focusing on advancing imitation learning methods from human demonstrations. The dataset is now open-sourced and available at https://embodiedrobot.github.io/, enhancing research and development efforts in the field of Embodied Manipulation.
Preferred-Action-Optimized Diffusion Policies for Offline Reinforcement Learning
May 29, 2024



Offline reinforcement learning (RL) aims to learn optimal policies from previously collected datasets. Recently, due to their powerful representational capabilities, diffusion models have shown significant potential as policy models for offline RL issues. However, previous offline RL algorithms based on diffusion policies generally adopt weighted regression to improve the policy. This approach optimizes the policy only using the collected actions and is sensitive to Q-values, which limits the potential for further performance enhancement. To this end, we propose a novel preferred-action-optimized diffusion policy for offline RL. In particular, an expressive conditional diffusion model is utilized to represent the diverse distribution of a behavior policy. Meanwhile, based on the diffusion model, preferred actions within the same behavior distribution are automatically generated through the critic function. Moreover, an anti-noise preference optimization is designed to achieve policy improvement by using the preferred actions, which can adapt to noise-preferred actions for stable training. Extensive experiments demonstrate that the proposed method provides competitive or superior performance compared to previous state-of-the-art offline RL methods, particularly in sparse reward tasks such as Kitchen and AntMaze. Additionally, we empirically prove the effectiveness of anti-noise preference optimization.
AutoManual: Generating Instruction Manuals by LLM Agents via Interactive Environmental Learning
May 25, 2024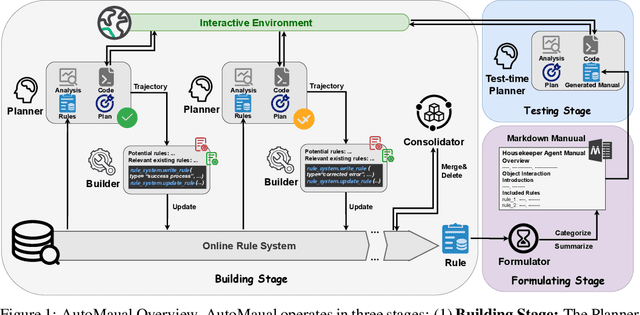
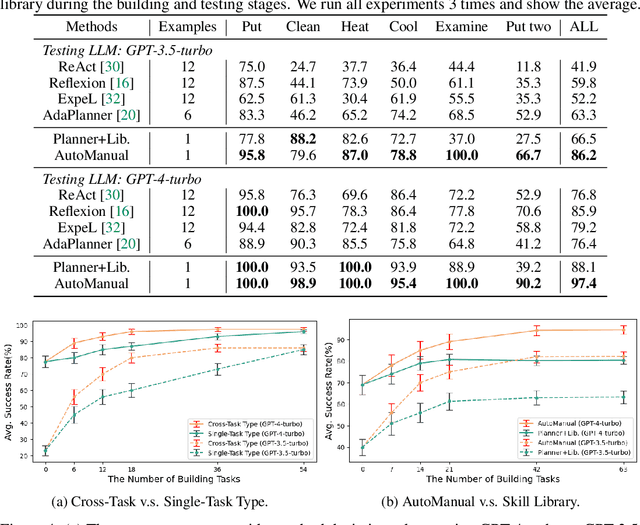
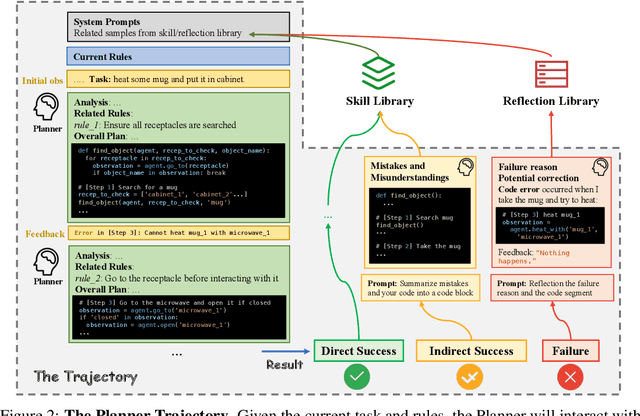
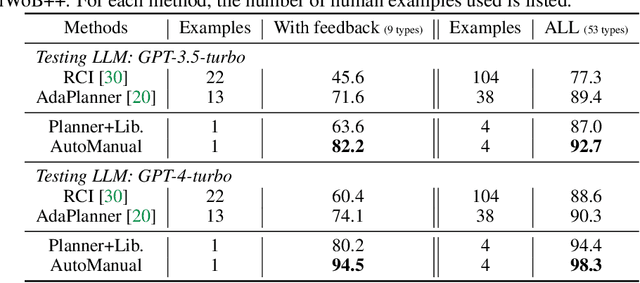
Large Language Models (LLM) based agents have shown promise in autonomously completing tasks across various domains, e.g., robotics, games, and web navigation. However, these agents typically require elaborate design and expert prompts to solve tasks in specific domains, which limits their adaptability. We introduce AutoManual, a framework enabling LLM agents to autonomously build their understanding through interaction and adapt to new environments. AutoManual categorizes environmental knowledge into diverse rules and optimizes them in an online fashion by two agents: 1) The Planner codes actionable plans based on current rules for interacting with the environment. 2) The Builder updates the rules through a well-structured rule system that facilitates online rule management and essential detail retention. To mitigate hallucinations in managing rules, we introduce \textit{case-conditioned prompting} strategy for the Builder. Finally, the Formulator agent compiles these rules into a comprehensive manual. The self-generated manual can not only improve the adaptability but also guide the planning of smaller LLMs while being human-readable. Given only one simple demonstration, AutoManual significantly improves task success rates, achieving 97.4\% with GPT-4-turbo and 86.2\% with GPT-3.5-turbo on ALFWorld benchmark tasks. The source code will be available soon.
MELD-ST: An Emotion-aware Speech Translation Dataset
May 21, 2024Emotion plays a crucial role in human conversation. This paper underscores the significance of considering emotion in speech translation. We present the MELD-ST dataset for the emotion-aware speech translation task, comprising English-to-Japanese and English-to-German language pairs. Each language pair includes about 10,000 utterances annotated with emotion labels from the MELD dataset. Baseline experiments using the SeamlessM4T model on the dataset indicate that fine-tuning with emotion labels can enhance translation performance in some settings, highlighting the need for further research in emotion-aware speech translation systems.
Weaver: Foundation Models for Creative Writing
Jan 30, 2024


This work introduces Weaver, our first family of large language models (LLMs) dedicated to content creation. Weaver is pre-trained on a carefully selected corpus that focuses on improving the writing capabilities of large language models. We then fine-tune Weaver for creative and professional writing purposes and align it to the preference of professional writers using a suit of novel methods for instruction data synthesis and LLM alignment, making it able to produce more human-like texts and follow more diverse instructions for content creation. The Weaver family consists of models of Weaver Mini (1.8B), Weaver Base (6B), Weaver Pro (14B), and Weaver Ultra (34B) sizes, suitable for different applications and can be dynamically dispatched by a routing agent according to query complexity to balance response quality and computation cost. Evaluation on a carefully curated benchmark for assessing the writing capabilities of LLMs shows Weaver models of all sizes outperform generalist LLMs several times larger than them. Notably, our most-capable Weaver Ultra model surpasses GPT-4, a state-of-the-art generalist LLM, on various writing scenarios, demonstrating the advantage of training specialized LLMs for writing purposes. Moreover, Weaver natively supports retrieval-augmented generation (RAG) and function calling (tool usage). We present various use cases of these abilities for improving AI-assisted writing systems, including integration of external knowledge bases, tools, or APIs, and providing personalized writing assistance. Furthermore, we discuss and summarize a guideline and best practices for pre-training and fine-tuning domain-specific LLMs.
Video-Helpful Multimodal Machine Translation
Oct 31, 2023Existing multimodal machine translation (MMT) datasets consist of images and video captions or instructional video subtitles, which rarely contain linguistic ambiguity, making visual information ineffective in generating appropriate translations. Recent work has constructed an ambiguous subtitles dataset to alleviate this problem but is still limited to the problem that videos do not necessarily contribute to disambiguation. We introduce EVA (Extensive training set and Video-helpful evaluation set for Ambiguous subtitles translation), an MMT dataset containing 852k Japanese-English (Ja-En) parallel subtitle pairs, 520k Chinese-English (Zh-En) parallel subtitle pairs, and corresponding video clips collected from movies and TV episodes. In addition to the extensive training set, EVA contains a video-helpful evaluation set in which subtitles are ambiguous, and videos are guaranteed helpful for disambiguation. Furthermore, we propose SAFA, an MMT model based on the Selective Attention model with two novel methods: Frame attention loss and Ambiguity augmentation, aiming to use videos in EVA for disambiguation fully. Experiments on EVA show that visual information and the proposed methods can boost translation performance, and our model performs significantly better than existing MMT models. The EVA dataset and the SAFA model are available at: https://github.com/ku-nlp/video-helpful-MMT.git.
Perch a quadrotor on planes by the ceiling effect
Jul 03, 2023
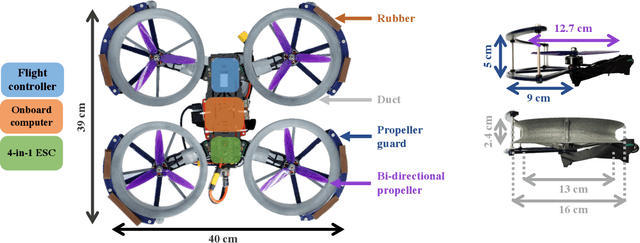
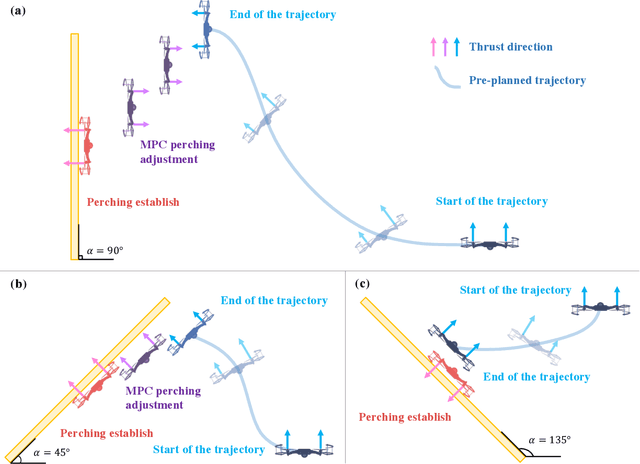
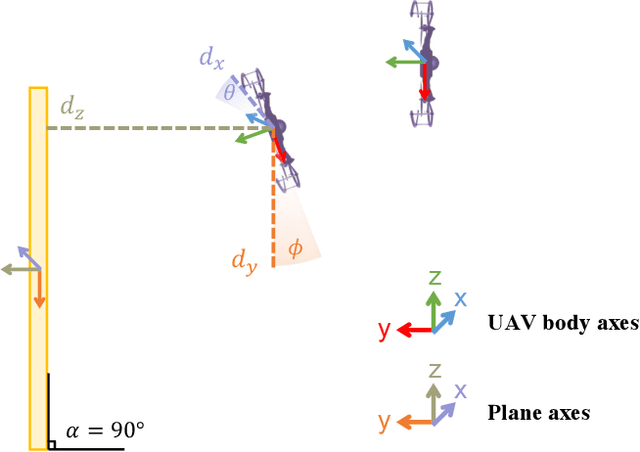
Perching is a promising solution for a small unmanned aerial vehicle (UAV) to save energy and extend operation time. This paper proposes a quadrotor that can perch on planar structures using the ceiling effect. Compared with the existing work, this perching method does not require any claws, hooks, or adhesive pads, leading to a simpler system design. This method does not limit the perching by surface angle or material either. The design of the quadrotor that only uses its propeller guards for surface contact is presented in this paper. We also discussed the automatic perching strategy including trajectory generation and power management. Experiments are conducted to verify that the approach is practical and the UAV can perch on planes with different angles. Energy consumption in the perching state is assessed, showing that more than 30% of power can be saved. Meanwhile, the quadrotor exhibits improved stability while perching compared to when it is hovering.
VISA: An Ambiguous Subtitles Dataset for Visual Scene-Aware Machine Translation
Jan 21, 2022


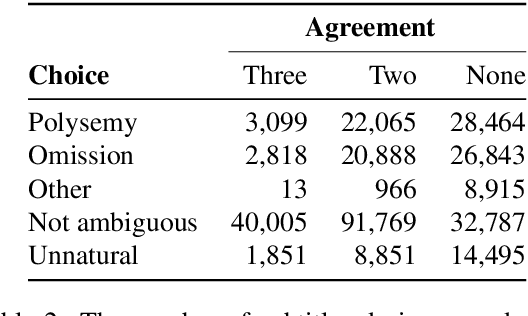
Existing multimodal machine translation (MMT) datasets consist of images and video captions or general subtitles, which rarely contain linguistic ambiguity, making visual information not so effective to generate appropriate translations. We introduce VISA, a new dataset that consists of 40k Japanese-English parallel sentence pairs and corresponding video clips with the following key features: (1) the parallel sentences are subtitles from movies and TV episodes; (2) the source subtitles are ambiguous, which means they have multiple possible translations with different meanings; (3) we divide the dataset into Polysemy and Omission according to the cause of ambiguity. We show that VISA is challenging for the latest MMT system, and we hope that the dataset can facilitate MMT research.