 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNearly Optimal Bayesian Inference for Structural Missingness
Jan 27, 2026Structural missingness breaks 'just impute and train': values can be undefined by causal or logical constraints, and the mask may depend on observed variables, unobserved variables (MNAR), and other missingness indicators. It simultaneously brings (i) a catch-22 situation with causal loop, prediction needs the missing features, yet inferring them depends on the missingness mechanism, (ii) under MNAR, the unseen are different, the missing part can come from a shifted distribution, and (iii) plug-in imputation, a single fill-in can lock in uncertainty and yield overconfident, biased decisions. In the Bayesian view, prediction via the posterior predictive distribution integrates over the full model posterior uncertainty, rather than relying on a single point estimate. This framework decouples (i) learning an in-model missing-value posterior from (ii) label prediction by optimizing the predictive posterior distribution, enabling posterior integration. This decoupling yields an in-model almost-free-lunch: once the posterior is learned, prediction is plug-and-play while preserving uncertainty propagation. It achieves SOTA on 43 classification and 15 imputation benchmarks, with finite-sample near Bayes-optimality guarantees under our SCM prior.
The RoboSense Challenge: Sense Anything, Navigate Anywhere, Adapt Across Platforms
Jan 08, 2026Autonomous systems are increasingly deployed in open and dynamic environments -- from city streets to aerial and indoor spaces -- where perception models must remain reliable under sensor noise, environmental variation, and platform shifts. However, even state-of-the-art methods often degrade under unseen conditions, highlighting the need for robust and generalizable robot sensing. The RoboSense 2025 Challenge is designed to advance robustness and adaptability in robot perception across diverse sensing scenarios. It unifies five complementary research tracks spanning language-grounded decision making, socially compliant navigation, sensor configuration generalization, cross-view and cross-modal correspondence, and cross-platform 3D perception. Together, these tasks form a comprehensive benchmark for evaluating real-world sensing reliability under domain shifts, sensor failures, and platform discrepancies. RoboSense 2025 provides standardized datasets, baseline models, and unified evaluation protocols, enabling large-scale and reproducible comparison of robust perception methods. The challenge attracted 143 teams from 85 institutions across 16 countries, reflecting broad community engagement. By consolidating insights from 23 winning solutions, this report highlights emerging methodological trends, shared design principles, and open challenges across all tracks, marking a step toward building robots that can sense reliably, act robustly, and adapt across platforms in real-world environments.
To Align or Not to Align: Strategic Multimodal Representation Alignment for Optimal Performance
Nov 19, 2025Multimodal learning often relies on aligning representations across modalities to enable effective information integration, an approach traditionally assumed to be universally beneficial. However, prior research has primarily taken an observational approach, examining naturally occurring alignment in multimodal data and exploring its correlation with model performance, without systematically studying the direct effects of explicitly enforced alignment between representations of different modalities. In this work, we investigate how explicit alignment influences both model performance and representation alignment under different modality-specific information structures. Specifically, we introduce a controllable contrastive learning module that enables precise manipulation of alignment strength during training, allowing us to explore when explicit alignment improves or hinders performance. Our results on synthetic and real datasets under different data characteristics show that the impact of explicit alignment on the performance of unimodal models is related to the characteristics of the data: the optimal level of alignment depends on the amount of redundancy between the different modalities. We identify an optimal alignment strength that balances modality-specific signals and shared redundancy in the mixed information distributions. This work provides practical guidance on when and how explicit alignment should be applied to achieve optimal unimodal encoder performance.
Safe Semantics, Unsafe Interpretations: Tackling Implicit Reasoning Safety in Large Vision-Language Models
Aug 12, 2025Large Vision-Language Models face growing safety challenges with multimodal inputs. This paper introduces the concept of Implicit Reasoning Safety, a vulnerability in LVLMs. Benign combined inputs trigger unsafe LVLM outputs due to flawed or hidden reasoning. To showcase this, we developed Safe Semantics, Unsafe Interpretations, the first dataset for this critical issue. Our demonstrations show that even simple In-Context Learning with SSUI significantly mitigates these implicit multimodal threats, underscoring the urgent need to improve cross-modal implicit reasoning.
Navigating the Black Box: Leveraging LLMs for Effective Text-Level Graph Injection Attacks
Jun 16, 2025



Text-attributed graphs (TAGs) integrate textual data with graph structures, providing valuable insights in applications such as social network analysis and recommendation systems. Graph Neural Networks (GNNs) effectively capture both topological structure and textual information in TAGs but are vulnerable to adversarial attacks. Existing graph injection attack (GIA) methods assume that attackers can directly manipulate the embedding layer, producing non-explainable node embeddings. Furthermore, the effectiveness of these attacks often relies on surrogate models with high training costs. Thus, this paper introduces ATAG-LLM, a novel black-box GIA framework tailored for TAGs. Our approach leverages large language models (LLMs) to generate interpretable text-level node attributes directly, ensuring attacks remain feasible in real-world scenarios. We design strategies for LLM prompting that balance exploration and reliability to guide text generation, and propose a similarity assessment method to evaluate attack text effectiveness in disrupting graph homophily. This method efficiently perturbs the target node with minimal training costs in a strict black-box setting, ensuring a text-level graph injection attack for TAGs. Experiments on real-world TAG datasets validate the superior performance of ATAG-LLM compared to state-of-the-art embedding-level and text-level attack methods.
LLM-Driven E-Commerce Marketing Content Optimization: Balancing Creativity and Conversion
May 27, 2025As e-commerce competition intensifies, balancing creative content with conversion effectiveness becomes critical. Leveraging LLMs' language generation capabilities, we propose a framework that integrates prompt engineering, multi-objective fine-tuning, and post-processing to generate marketing copy that is both engaging and conversion-driven. Our fine-tuning method combines sentiment adjustment, diversity enhancement, and CTA embedding. Through offline evaluations and online A/B tests across categories, our approach achieves a 12.5 % increase in CTR and an 8.3 % increase in CVR while maintaining content novelty. This provides a practical solution for automated copy generation and suggests paths for future multimodal, real-time personalization.
Object-Focus Actor for Data-efficient Robot Generalization Dexterous Manipulation
May 21, 2025Robot manipulation learning from human demonstrations offers a rapid means to acquire skills but often lacks generalization across diverse scenes and object placements. This limitation hinders real-world applications, particularly in complex tasks requiring dexterous manipulation. Vision-Language-Action (VLA) paradigm leverages large-scale data to enhance generalization. However, due to data scarcity, VLA's performance remains limited. In this work, we introduce Object-Focus Actor (OFA), a novel, data-efficient approach for generalized dexterous manipulation. OFA exploits the consistent end trajectories observed in dexterous manipulation tasks, allowing for efficient policy training. Our method employs a hierarchical pipeline: object perception and pose estimation, pre-manipulation pose arrival and OFA policy execution. This process ensures that the manipulation is focused and efficient, even in varied backgrounds and positional layout. Comprehensive real-world experiments across seven tasks demonstrate that OFA significantly outperforms baseline methods in both positional and background generalization tests. Notably, OFA achieves robust performance with only 10 demonstrations, highlighting its data efficiency.
RDI: An adversarial robustness evaluation metric for deep neural networks based on sample clustering features
Apr 16, 2025Deep neural networks (DNNs) are highly susceptible to adversarial samples, raising concerns about their reliability in safety-critical tasks. Currently, methods of evaluating adversarial robustness are primarily categorized into attack-based and certified robustness evaluation approaches. The former not only relies on specific attack algorithms but also is highly time-consuming, while the latter due to its analytical nature, is typically difficult to implement for large and complex models. A few studies evaluate model robustness based on the model's decision boundary, but they suffer from low evaluation accuracy. To address the aforementioned issues, we propose a novel adversarial robustness evaluation metric, Robustness Difference Index (RDI), which is based on sample clustering features. RDI draws inspiration from clustering evaluation by analyzing the intra-class and inter-class distances of feature vectors separated by the decision boundary to quantify model robustness. It is attack-independent and has high computational efficiency. Experiments show that, RDI demonstrates a stronger correlation with the gold-standard adversarial robustness metric of attack success rate (ASR). The average computation time of RDI is only 1/30 of the evaluation method based on the PGD attack. Our open-source code is available at: https://anonymous.4open.science/r/RDI-B1DA.
Dexterous Hand Manipulation via Efficient Imitation-Bootstrapped Online Reinforcement Learning
Mar 06, 2025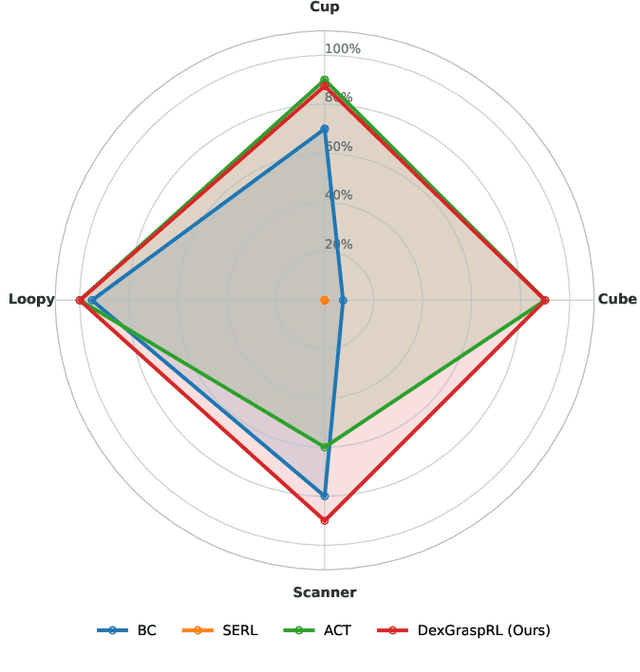
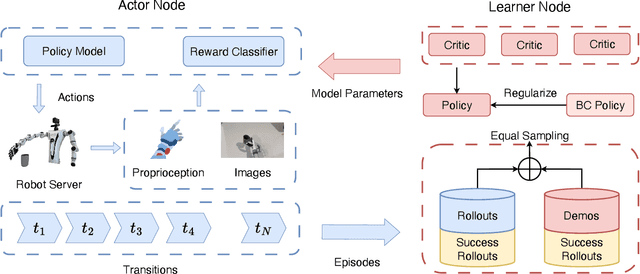
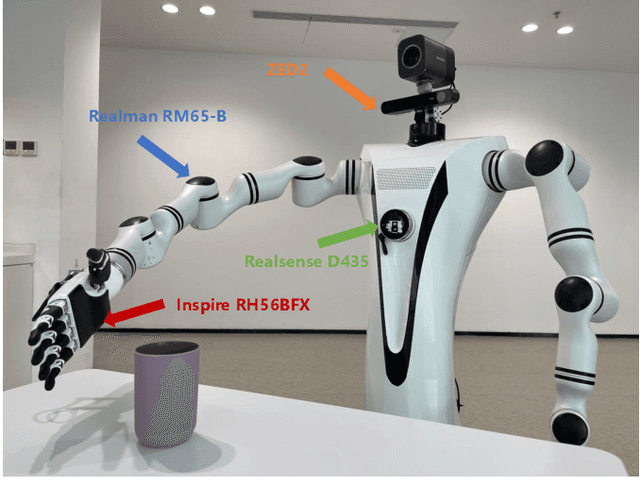

Dexterous hand manipulation in real-world scenarios presents considerable challenges due to its demands for both dexterity and precision. While imitation learning approaches have thoroughly examined these challenges, they still require a significant number of expert demonstrations and are limited by a constrained performance upper bound. In this paper, we propose a novel and efficient Imitation-Bootstrapped Online Reinforcement Learning (IBORL) method tailored for robotic dexterous hand manipulation in real-world environments. Specifically, we pretrain the policy using a limited set of expert demonstrations and subsequently finetune this policy through direct reinforcement learning in the real world. To address the catastrophic forgetting issues that arise from the distribution shift between expert demonstrations and real-world environments, we design a regularization term that balances the exploration of novel behaviors with the preservation of the pretrained policy. Our experiments with real-world tasks demonstrate that our method significantly outperforms existing approaches, achieving an almost 100% success rate and a 23% improvement in cycle time. Furthermore, by finetuning with online reinforcement learning, our method surpasses expert demonstrations and uncovers superior policies. Our code and empirical results are available in https://hggforget.github.io/iborl.github.io/.
Prioritize Alignment in Dataset Distillation
Aug 06, 2024
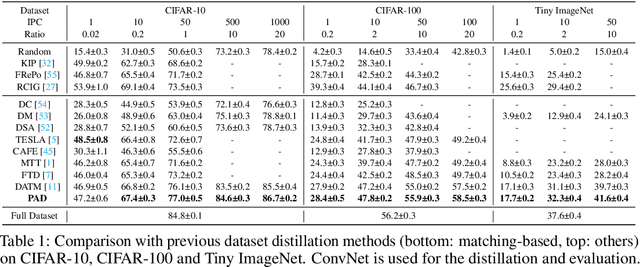
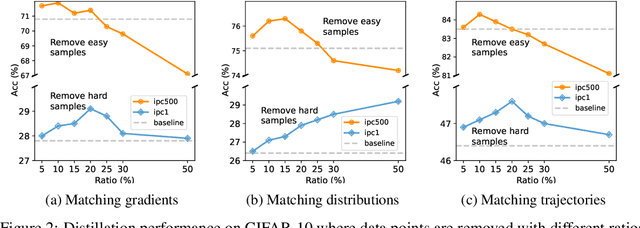
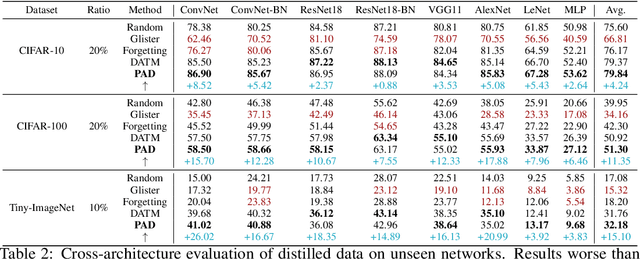
Dataset Distillation aims to compress a large dataset into a significantly more compact, synthetic one without compromising the performance of the trained models. To achieve this, existing methods use the agent model to extract information from the target dataset and embed it into the distilled dataset. Consequently, the quality of extracted and embedded information determines the quality of the distilled dataset. In this work, we find that existing methods introduce misaligned information in both information extraction and embedding stages. To alleviate this, we propose Prioritize Alignment in Dataset Distillation (PAD), which aligns information from the following two perspectives. 1) We prune the target dataset according to the compressing ratio to filter the information that can be extracted by the agent model. 2) We use only deep layers of the agent model to perform the distillation to avoid excessively introducing low-level information. This simple strategy effectively filters out misaligned information and brings non-trivial improvement for mainstream matching-based distillation algorithms. Furthermore, built on trajectory matching, \textbf{PAD} achieves remarkable improvements on various benchmarks, achieving state-of-the-art performance.