 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHiEdit: Lifelong Model Editing with Hierarchical Reinforcement Learning
Apr 13, 2026Lifelong model editing (LME) aims to sequentially rectify outdated or inaccurate knowledge in deployed LLMs while minimizing side effects on unrelated inputs. However, existing approaches typically apply parameter perturbations to a static and dense set of LLM layers for all editing instances. This practice is counter-intuitive, as we hypothesize that different pieces of knowledge are stored in distinct layers of the model. Neglecting this layer-wise specificity can impede adaptability in integrating new knowledge and result in catastrophic forgetting for both general and previously edited knowledge. To address this, we propose HiEdit, a hierarchical reinforcement learning framework that adaptively identifies the most knowledge-relevant layers for each editing instance. By enabling dynamic, instance-aware layer selection and incorporating an intrinsic reward for sparsity, HiEdit achieves precise, localized updates. Experiments on various LLMs show that HiEdit boosts the performance of the competitive RLEdit by an average of 8.48% with perturbing only half of the layers per edit. Our code is available at: https://github.com/yangfanww/hiedit.
Weak Adversarial Neural Pushforward Method for the Wigner Transport Equation
Apr 09, 2026We extend the Weak Adversarial Neural Pushforward Method to the Wigner transport equation governing the phase-space dynamics of quantum systems. The central contribution is a structural observation: integrating the nonlocal pseudo-differential potential operator against plane-wave test functions produces a Dirac delta that exactly inverts the Fourier transform defining the Wigner potential kernel, reducing the operator to a pointwise finite difference of the potential at two shifted arguments. This holds in arbitrary dimension, requires no truncation of the Moyal series, and treats the potential as a black-box function oracle with no derivative information. To handle the negativity of the Wigner quasi-probability distribution, we introduce a signed pushforward architecture that decomposes the solution into two non-negative phase-space distributions mixed with a learnable weight. The resulting method inherits the mesh-free, Jacobian-free, and scalable properties of the original framework while extending it to the quantum setting.
Neural Pushforward Samplers for the Fokker-Planck Equation on Embedded Riemannian Manifolds
Mar 17, 2026We extend the Weak Adversarial Neural Pushforward (WANPF) Method to the Fokker--Planck equation posed on a compact, smoothly embedded Riemannian manifold M in $R^n$. The key observation is that the weak formulation of the Fokker--Planck equation, together with the ambient-space representation of the Laplace--Beltrami operator via the tangential projection $P(x)$ and the mean-curvature vector $H(x)$, permits all integrals to be evaluated as expectations over samples lying on M, using test functions defined globally on $R^n$. A neural pushforward map is constrained to map the support of a base distribution into M at all times through a manifold retraction, so that probability conservation and manifold membership are enforced by construction. Adversarial ambient plane-wave test functions are chosen, and their Laplace--Beltrami operators are derived in closed form, enabling autodiff-free, mesh-free training. We present both a steady-state and a time-dependent formulation, derive explicit Laplace--Beltrami formulae for the sphere $S^{n-1}$ and the flat torus $T^n$, and demonstrate the method numerically on a double-well steady-state Fokker--Planck equation on $S^2$.
Deep Neural networks for solving high-dimensional parabolic partial differential equations
Jan 19, 2026The numerical solution of high dimensional partial differential equations (PDEs) is severely constrained by the curse of dimensionality (CoD), rendering classical grid--based methods impractical beyond a few dimensions. In recent years, deep neural networks have emerged as a promising mesh free alternative, enabling the approximation of PDE solutions in tens to thousands of dimensions. This review provides a tutorial--oriented introduction to neural--network--based methods for solving high dimensional parabolic PDEs, emphasizing conceptual clarity and methodological connections. We organize the literature around three unifying paradigms: (i) PDE residual--based approaches, including physicsinformed neural networks and their high dimensional variants; (ii) stochastic methods derived from Feynman--Kac and backward stochastic differential equation formulations; and (iii) hybrid derivative--free random difference approaches designed to alleviate the computational cost of derivatives in high dimensions. For each paradigm, we outline the underlying mathematical formulation, algorithmic implementation, and practical strengths and limitations. Representative benchmark problems--including Hamilton--Jacobi--Bellman and Black--Scholes equations in up to 1000 dimensions --illustrate the scalability, effectiveness, and accuracy of the methods. The paper concludes with a discussion of open challenges and future directions for reliable and scalable solvers of high dimensional PDEs.
ARDO: A Weak Formulation Deep Neural Network Method for Elliptic and Parabolic PDEs Based on Random Differences of Test Functions
Sep 03, 2025We propose ARDO method for solving PDEs and PDE-related problems with deep learning techniques. This method uses a weak adversarial formulation but transfers the random difference operator onto the test function. The main advantage of this framework is that it is fully derivative-free with respect to the solution neural network. This framework is particularly suitable for Fokker-Planck type second-order elliptic and parabolic PDEs.
Safe Semantics, Unsafe Interpretations: Tackling Implicit Reasoning Safety in Large Vision-Language Models
Aug 12, 2025Large Vision-Language Models face growing safety challenges with multimodal inputs. This paper introduces the concept of Implicit Reasoning Safety, a vulnerability in LVLMs. Benign combined inputs trigger unsafe LVLM outputs due to flawed or hidden reasoning. To showcase this, we developed Safe Semantics, Unsafe Interpretations, the first dataset for this critical issue. Our demonstrations show that even simple In-Context Learning with SSUI significantly mitigates these implicit multimodal threats, underscoring the urgent need to improve cross-modal implicit reasoning.
Multi-scale DeepOnet (Mscale-DeepOnet) for Mitigating Spectral Bias in Learning High Frequency Operators of Oscillatory Functions
Apr 15, 2025



In this paper, a multi-scale DeepOnet (Mscale-DeepOnet) is proposed to reduce the spectral bias of the DeepOnet in learning high-frequency mapping between highly oscillatory functions, with an application to the nonlinear mapping between the coefficient of the Helmholtz equation and its solution. The Mscale-DeepOnet introduces the multiscale neural network in the branch and trunk networks of the original DeepOnet, the resulting Mscale-DeepOnet is shown to be able to capture various high-frequency components of the mapping itself and its image. Numerical results demonstrate the substantial improvement of the Mscale-DeepOnet for the problem of wave scattering in the high-frequency regime over the normal DeepOnet with a similar number of network parameters.
Image registration of 2D optical thin sections in a 3D porous medium: Application to a Berea sandstone digital rock image
Apr 09, 2025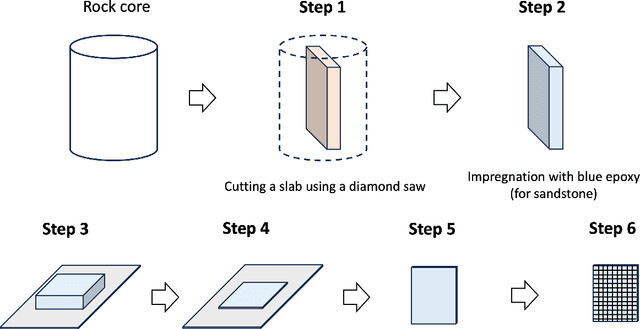
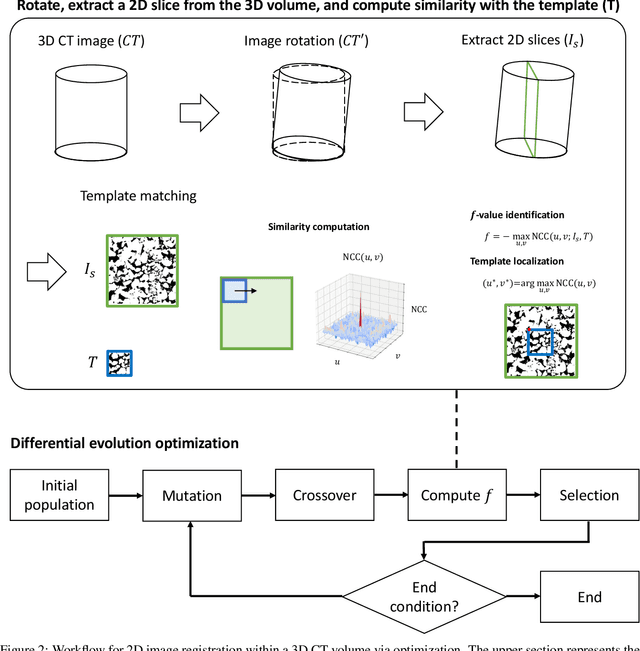
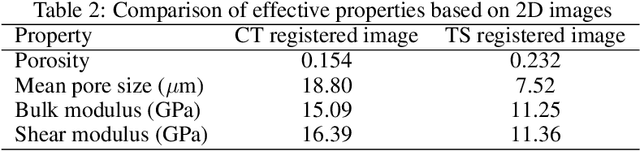
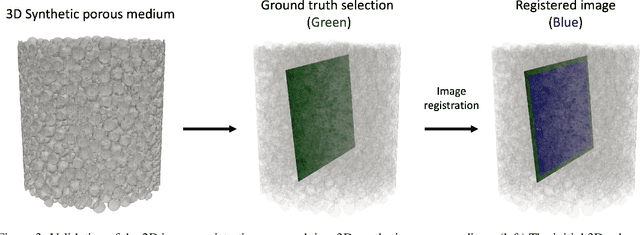
This study proposes a systematic image registration approach to align 2D optical thin-section images within a 3D digital rock volume. Using template image matching with differential evolution optimization, we identify the most similar 2D plane in 3D. The method is validated on a synthetic porous medium, achieving exact registration, and applied to Berea sandstone, where it achieves a structural similarity index (SSIM) of 0.990. With the registered images, we explore upscaling properties based on paired multimodal images, focusing on pore characteristics and effective elastic moduli. The thin-section image reveals 50 % more porosity and submicron pores than the registered CT plane. In addition, bulk and shear moduli from thin sections are 25 % and 30 % lower, respectively, than those derived from CT images. Beyond numerical comparisons, thin sections provide additional geological insights, including cementation, mineral phases, and weathering effects, which are not clear in CT images. This study demonstrates the potential of multimodal image registration to improve computed rock properties in digital rock physics by integrating complementary imaging modalities.
A Multimodal Framework for Topic Propagation Classification in Social Networks
Mar 05, 2025
The rapid proliferation of the Internet and the widespread adoption of social networks have significantly accelerated information dissemination. However, this transformation has introduced complexities in information capture and processing, posing substantial challenges for researchers and practitioners. Predicting the dissemination of topic-related information within social networks has thus become a critical research focus. This paper proposes a predictive model for topic dissemination in social networks by integrating multidimensional features derived from key dissemination characteristics. Specifically, we introduce two novel indicators, user relationship breadth and user authority, into the PageRank algorithm to quantify user influence more effectively. Additionally, we employ a Text-CNN model for sentiment classification, extracting sentiment features from textual content. Temporal embeddings of nodes are encoded using a Bi-LSTM model to capture temporal dynamics. Furthermore, we refine the measurement of user interaction traces with topics, replacing traditional topic view metrics with a more precise communication characteristics measure. Finally, we integrate the extracted multidimensional features using a Transformer model, significantly enhancing predictive performance. Experimental results demonstrate that our proposed model outperforms traditional machine learning and unimodal deep learning models in terms of FI-Score, AUC, and Recall, validating its effectiveness in predicting topic propagation within social networks.
BounTCHA: A CAPTCHA Utilizing Boundary Identification in AI-extended Videos
Jan 30, 2025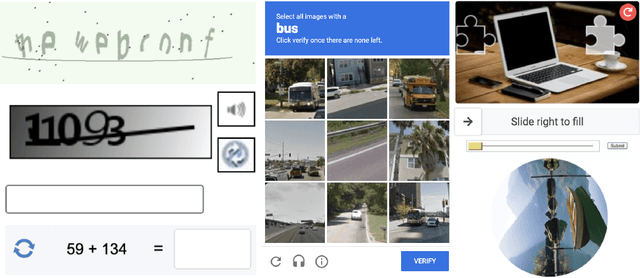


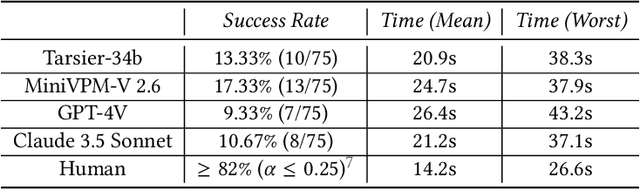
In recent years, the rapid development of artificial intelligence (AI) especially multi-modal Large Language Models (MLLMs), has enabled it to understand text, images, videos, and other multimedia data, allowing AI systems to execute various tasks based on human-provided prompts. However, AI-powered bots have increasingly been able to bypass most existing CAPTCHA systems, posing significant security threats to web applications. This makes the design of new CAPTCHA mechanisms an urgent priority. We observe that humans are highly sensitive to shifts and abrupt changes in videos, while current AI systems still struggle to comprehend and respond to such situations effectively. Based on this observation, we design and implement BounTCHA, a CAPTCHA mechanism that leverages human perception of boundaries in video transitions and disruptions. By utilizing AI's capability to expand original videos with prompts, we introduce unexpected twists and changes to create a pipeline for generating short videos for CAPTCHA purposes. We develop a prototype and conduct experiments to collect data on humans' time biases in boundary identification. This data serves as a basis for distinguishing between human users and bots. Additionally, we perform a detailed security analysis of BounTCHA, demonstrating its resilience against various types of attacks. We hope that BounTCHA will act as a robust defense, safeguarding millions of web applications in the AI-driven era.