 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributionally Robust Graph Out-of-Distribution Recommendation via Diffusion Model
Jan 26, 2025The distributionally robust optimization (DRO)-based graph neural network methods improve recommendation systems' out-of-distribution (OOD) generalization by optimizing the model's worst-case performance. However, these studies fail to consider the impact of noisy samples in the training data, which results in diminished generalization capabilities and lower accuracy. Through experimental and theoretical analysis, this paper reveals that current DRO-based graph recommendation methods assign greater weight to noise distribution, leading to model parameter learning being dominated by it. When the model overly focuses on fitting noise samples in the training data, it may learn irrelevant or meaningless features that cannot be generalized to OOD data. To address this challenge, we design a Distributionally Robust Graph model for OOD recommendation (DRGO). Specifically, our method first employs a simple and effective diffusion paradigm to alleviate the noisy effect in the latent space. Additionally, an entropy regularization term is introduced in the DRO objective function to avoid extreme sample weights in the worst-case distribution. Finally, we provide a theoretical proof of the generalization error bound of DRGO as well as a theoretical analysis of how our approach mitigates noisy sample effects, which helps to better understand the proposed framework from a theoretical perspective. We conduct extensive experiments on four datasets to evaluate the effectiveness of our framework against three typical distribution shifts, and the results demonstrate its superiority in both independently and identically distributed distributions (IID) and OOD.
Self-supervised Hierarchical Representation for Medication Recommendation
Nov 05, 2024



Medication recommender is to suggest appropriate medication combinations based on a patient's health history, e.g., diagnoses and procedures. Existing works represent different diagnoses/procedures well separated by one-hot encodings. However, they ignore the latent hierarchical structures of these medical terms, undermining the generalization performance of the model. For example, "Respiratory Diseases", "Chronic Respiratory Diseases" and "Chronic Bronchiti" have a hierarchical relationship, progressing from general to specific. To address this issue, we propose a novel hierarchical encoder named HIER to hierarchically represent diagnoses and procedures, which is based on standard medical codes and compatible with any existing methods. Specifically, the proposed method learns relation embedding with a self-supervised objective for incorporating the neighbor hierarchical structure. Additionally, we develop the position encoding to explicitly introduce global hierarchical position. Extensive experiments demonstrate significant and consistent improvements in recommendation accuracy across four baselines and two real-world clinical datasets.
CoRA: Collaborative Information Perception by Large Language Model's Weights for Recommendation
Aug 20, 2024



Involving collaborative information in Large Language Models (LLMs) is a promising technique for adapting LLMs for recommendation. Existing methods achieve this by concatenating collaborative features with text tokens into a unified sequence input and then fine-tuning to align these features with LLM's input space. Although effective, in this work, we identify two limitations when adapting LLMs to recommendation tasks, which hinder the integration of general knowledge and collaborative information, resulting in sub-optimal recommendation performance. (1) Fine-tuning LLM with recommendation data can undermine its inherent world knowledge and fundamental competencies, which are crucial for interpreting and inferring recommendation text. (2) Incorporating collaborative features into textual prompts disrupts the semantics of the original prompts, preventing LLM from generating appropriate outputs. In this paper, we propose a new paradigm, CoRA (an acronym for Collaborative LoRA), with a collaborative weights generator. Rather than input space alignment, this method aligns collaborative information with LLM's parameter space, representing them as incremental weights to update LLM's output. This way, LLM perceives collaborative information without altering its general knowledge and text inference capabilities. Specifically, we employ a collaborative filtering model to extract user and item embeddings, converting them into collaborative weights with low-rank properties through the collaborative weights generator. We then merge the collaborative weights into LLM's weights, enabling LLM to perceive the collaborative signals and generate personalized recommendations without fine-tuning or extra collaborative tokens in prompts. Extensive experiments confirm that CoRA effectively integrates collaborative information into LLM, enhancing recommendation performance.
Symmetric Graph Contrastive Learning against Noisy Views for Recommendation
Aug 03, 2024Graph Contrastive Learning (GCL) leverages data augmentation techniques to produce contrasting views, enhancing the accuracy of recommendation systems through learning the consistency between contrastive views. However, existing augmentation methods, such as directly perturbing interaction graph (e.g., node/edge dropout), may interfere with the original connections and generate poor contrasting views, resulting in sub-optimal performance. In this paper, we define the views that share only a small amount of information with the original graph due to poor data augmentation as noisy views (i.e., the last 20% of the views with a cosine similarity value less than 0.1 to the original view). We demonstrate through detailed experiments that noisy views will significantly degrade recommendation performance. Further, we propose a model-agnostic Symmetric Graph Contrastive Learning (SGCL) method with theoretical guarantees to address this issue. Specifically, we introduce symmetry theory into graph contrastive learning, based on which we propose a symmetric form and contrast loss resistant to noisy interference. We provide theoretical proof that our proposed SGCL method has a high tolerance to noisy views. Further demonstration is given by conducting extensive experiments on three real-world datasets. The experimental results demonstrate that our approach substantially increases recommendation accuracy, with relative improvements reaching as high as 12.25% over nine other competing models. These results highlight the efficacy of our method.
Graph Representation Learning via Causal Diffusion for Out-of-Distribution Recommendation
Aug 01, 2024Graph Neural Networks (GNNs)-based recommendation algorithms typically assume that training and testing data are drawn from independent and identically distributed (IID) spaces. However, this assumption often fails in the presence of out-of-distribution (OOD) data, resulting in significant performance degradation. In this study, we construct a Structural Causal Model (SCM) to analyze interaction data, revealing that environmental confounders (e.g., the COVID-19 pandemic) lead to unstable correlations in GNN-based models, thus impairing their generalization to OOD data. To address this issue, we propose a novel approach, graph representation learning via causal diffusion (CausalDiffRec) for OOD recommendation. This method enhances the model's generalization on OOD data by eliminating environmental confounding factors and learning invariant graph representations. Specifically, we use backdoor adjustment and variational inference to infer the real environmental distribution, thereby eliminating the impact of environmental confounders. This inferred distribution is then used as prior knowledge to guide the representation learning in the reverse phase of the diffusion process to learn the invariant representation. In addition, we provide a theoretical derivation that proves optimizing the objective function of CausalDiffRec can encourage the model to learn environment-invariant graph representations, thereby achieving excellent generalization performance in recommendations under distribution shifts. Our extensive experiments validate the effectiveness of CausalDiffRec in improving the generalization of OOD data, and the average improvement is up to 10.69% on Food, 18.83% on KuaiRec, 22.41% on Yelp2018, and 11.65% on Douban datasets.
Towards Unified Modeling for Positive and Negative Preferences in Sign-Aware Recommendation
Mar 13, 2024



Recently, sign-aware graph recommendation has drawn much attention as it will learn users' negative preferences besides positive ones from both positive and negative interactions (i.e., links in a graph) with items. To accommodate the different semantics of negative and positive links, existing works utilize two independent encoders to model users' positive and negative preferences, respectively. However, these approaches cannot learn the negative preferences from high-order heterogeneous interactions between users and items formed by multiple links with different signs, resulting in inaccurate and incomplete negative user preferences. To cope with these intractable issues, we propose a novel \textbf{L}ight \textbf{S}igned \textbf{G}raph Convolution Network specifically for \textbf{Rec}ommendation (\textbf{LSGRec}), which adopts a unified modeling approach to simultaneously model high-order users' positive and negative preferences on a signed user-item interaction graph. Specifically, for the negative preferences within high-order heterogeneous interactions, first-order negative preferences are captured by the negative links, while high-order negative preferences are propagated along positive edges. Then, recommendation results are generated based on positive preferences and optimized with negative ones. Finally, we train representations of users and items through different auxiliary tasks. Extensive experiments on three real-world datasets demonstrate that our method outperforms existing baselines regarding performance and computational efficiency. Our code is available at \url{https://anonymous.4open.science/r/LSGRec-BB95}.
ID Embedding as Subtle Features of Content and Structure for Multimodal Recommendation
Nov 10, 2023


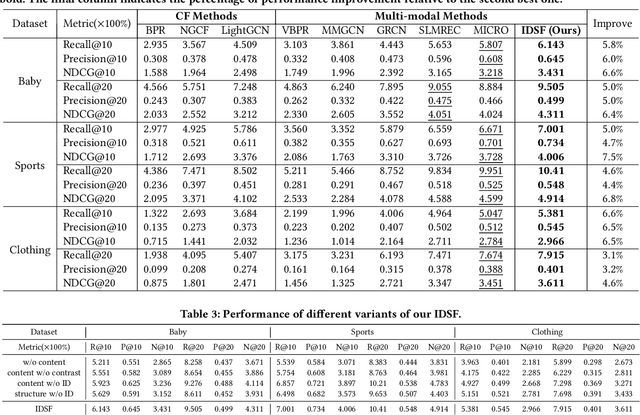
Multimodal recommendation aims to model user and item representations comprehensively with the involvement of multimedia content for effective recommendations. Existing research has shown that it is beneficial for recommendation performance to combine (user- and item-) ID embeddings with multimodal salient features, indicating the value of IDs. However, there is a lack of a thorough analysis of the ID embeddings in terms of feature semantics in the literature. In this paper, we revisit the value of ID embeddings for multimodal recommendation and conduct a thorough study regarding its semantics, which we recognize as subtle features of content and structures. Then, we propose a novel recommendation model by incorporating ID embeddings to enhance the semantic features of both content and structures. Specifically, we put forward a hierarchical attention mechanism to incorporate ID embeddings in modality fusing, coupled with contrastive learning, to enhance content representations. Meanwhile, we propose a lightweight graph convolutional network for each modality to amalgamate neighborhood and ID embeddings for improving structural representations. Finally, the content and structure representations are combined to form the ultimate item embedding for recommendation. Extensive experiments on three real-world datasets (Baby, Sports, and Clothing) demonstrate the superiority of our method over state-of-the-art multimodal recommendation methods and the effectiveness of fine-grained ID embeddings.